 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple yet Effective Self-Debiasing Framework for Transformer Models
Paper and Code

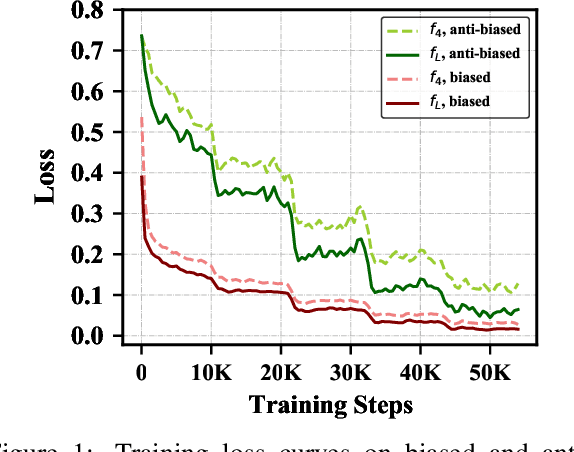
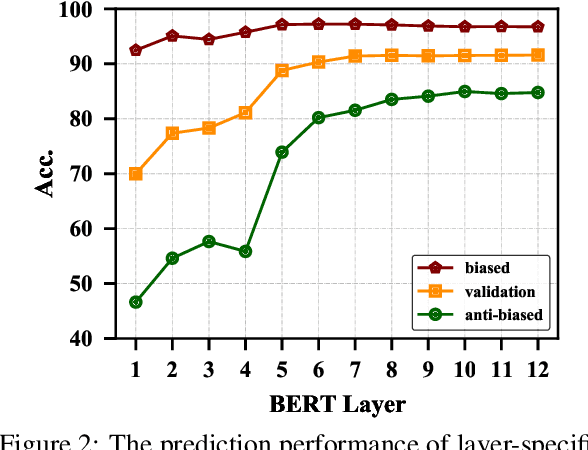

Current Transformer-based natural language understanding (NLU) models heavily rely on dataset biases, while failing to handle real-world out-of-distribution (OOD) instances. Many methods have been proposed to deal with this issue, but they ignore the fact that the features learned in different layers of Transformer-based NLU models are different. In this paper, we first conduct preliminary studies to obtain two conclusions: 1) both low- and high-layer sentence representations encode common biased features during training; 2) the low-layer sentence representations encode fewer unbiased features than the highlayer ones. Based on these conclusions, we propose a simple yet effective self-debiasing framework for Transformer-based NLU models. Concretely, we first stack a classifier on a selected low layer. Then, we introduce a residual connection that feeds the low-layer sentence representation to the top-layer classifier. In this way, the top-layer sentence representation will be trained to ignore the common biased features encoded by the low-layer sentence representation and focus on task-relevant unbiased features. During inference, we remove the residual connection and directly use the top-layer sentence representation to make predictions. Extensive experiments and indepth analyses on NLU tasks show that our framework performs better than several competitive baselines, achieving a new SOTA on all OOD test sets.