 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidenceBench: A Benchmark for Extracting Evidence from Biomedical Papers
Apr 25, 2025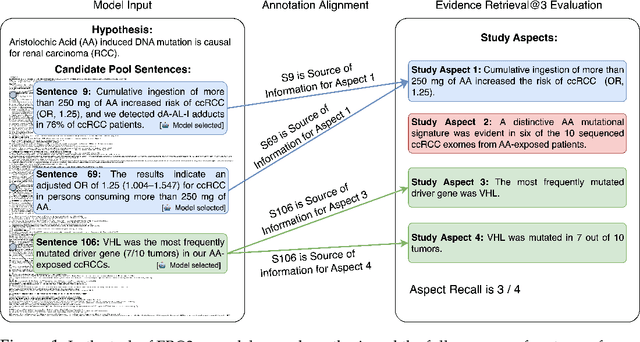



We study the task of automatically finding evidence relevant to hypotheses in biomedical papers. Finding relevant evidence is an important step when researchers investigate scientific hypotheses. We introduce EvidenceBench to measure models performance on this task, which is created by a novel pipeline that consists of hypothesis generation and sentence-by-sentence annotation of biomedical papers for relevant evidence, completely guided by and faithfully following existing human experts judgment. We demonstrate the pipeline's validity and accuracy with multiple sets of human-expert annotations. We evaluated a diverse set of language models and retrieval systems on the benchmark and found that model performances still fall significantly short of the expert level on this task. To show the scalability of our proposed pipeline, we create a larger EvidenceBench-100k with 107,461 fully annotated papers with hypotheses to facilitate model training and development. Both datasets are available at https://github.com/EvidenceBench/EvidenceBench
Single-Pass Document Scanning for Question Answering
Apr 04, 2025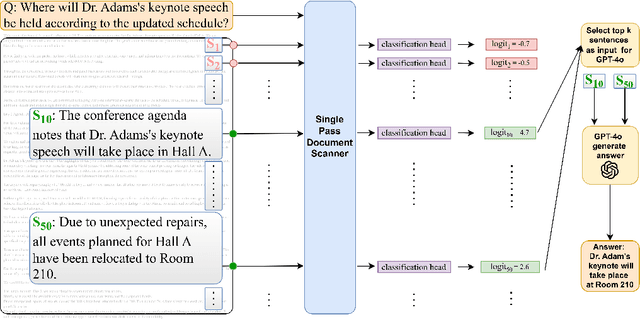
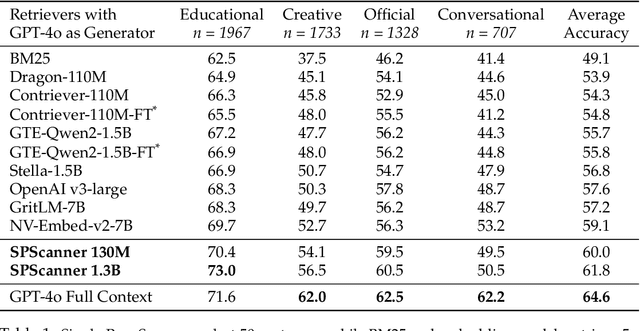
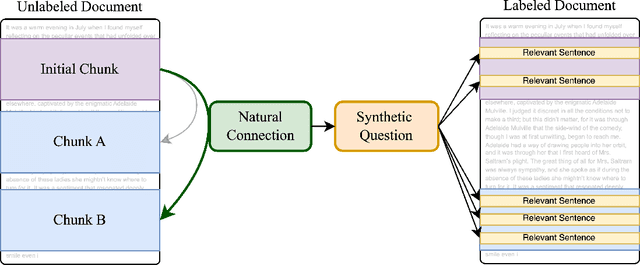
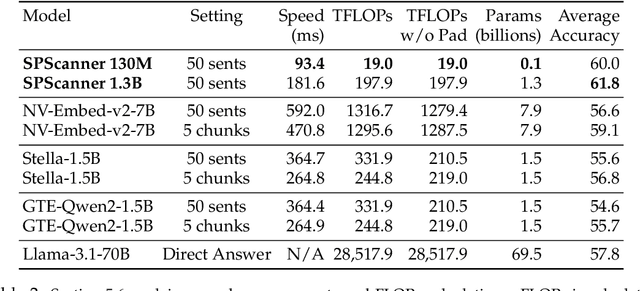
Handling extremely large documents for question answering is challenging: chunk-based embedding methods often lose track of important global context, while full-context transformers can be prohibitively expensive for hundreds of thousands of tokens. We propose a single-pass document scanning approach that processes the entire text in linear time, preserving global coherence while deciding which sentences are most relevant to the query. On 41 QA benchmarks, our single-pass scanner consistently outperforms chunk-based embedding methods and competes with large language models at a fraction of the computational cost. By conditioning on the entire preceding context without chunk breaks, the method preserves global coherence, which is especially important for long documents. Overall, single-pass document scanning offers a simple solution for question answering over massive text. All code, datasets, and model checkpoints are available at https://github.com/MambaRetriever/MambaRetriever
Measuring Risk of Bias in Biomedical Reports: The RoBBR Benchmark
Nov 28, 2024



Systems that answer questions by reviewing the scientific literature are becoming increasingly feasible. To draw reliable conclusions, these systems should take into account the quality of available evidence, placing more weight on studies that use a valid methodology. We present a benchmark for measuring the methodological strength of biomedical papers, drawing on the risk-of-bias framework used for systematic reviews. The four benchmark tasks, drawn from more than 500 papers, cover the analysis of research study methodology, followed by evaluation of risk of bias in these studies. The benchmark contains 2000 expert-generated bias annotations, and a human-validated pipeline for fine-grained alignment with research paper content. We evaluate a range of large language models on the benchmark, and find that these models fall significantly short of expert-level performance. By providing a standardized tool for measuring judgments of study quality, the benchmark can help to guide systems that perform large-scale aggregation of scientific data. The dataset is available at https://github.com/RoBBR-Benchmark/RoBBR.
IR2: Information Regularization for Information Retrieval
Feb 25, 2024



Effective information retrieval (IR) in settings with limited training data, particularly for complex queries, remains a challenging task. This paper introduces IR2, Information Regularization for Information Retrieval, a technique for reducing overfitting during synthetic data generation. This approach, representing a novel application of regularization techniques in synthetic data creation for IR, is tested on three recent IR tasks characterized by complex queries: DORIS-MAE, ArguAna, and WhatsThatBook. Experimental results indicate that our regularization techniques not only outperform previous synthetic query generation methods on the tasks considered but also reduce cost by up to 50%. Furthermore, this paper categorizes and explores three regularization methods at different stages of the query synthesis pipeline-input, prompt, and output-each offering varying degrees of performance improvement compared to models where no regularization is applied. This provides a systematic approach for optimizing synthetic data generation in data-limited, complex-query IR scenarios. All code, prompts and synthetic data are available at https://github.com/Info-Regularization/Information-Regularization.
BIRCO: A Benchmark of Information Retrieval Tasks with Complex Objectives
Feb 21, 2024We present the Benchmark of Information Retrieval (IR) tasks with Complex Objectives (BIRCO). BIRCO evaluates the ability of IR systems to retrieve documents given multi-faceted user objectives. The benchmark's complexity and compact size make it suitable for evaluating large language model (LLM)-based information retrieval systems. We present a modular framework for investigating factors that may influence LLM performance on retrieval tasks, and identify a simple baseline model which matches or outperforms existing approaches and more complex alternatives. No approach achieves satisfactory performance on all benchmark tasks, suggesting that stronger models and new retrieval protocols are necessary to address complex user needs.