 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuiet Feature Learning in Algorithmic Tasks
May 06, 2025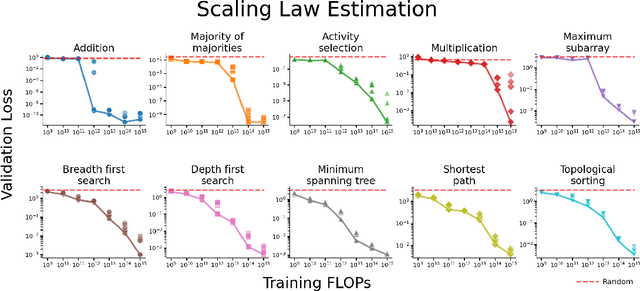
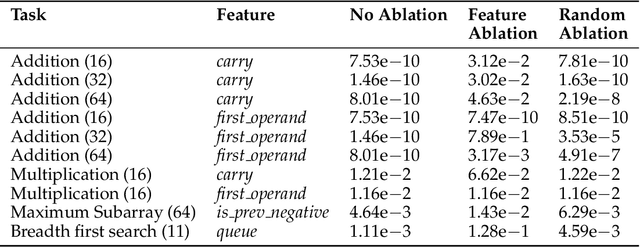
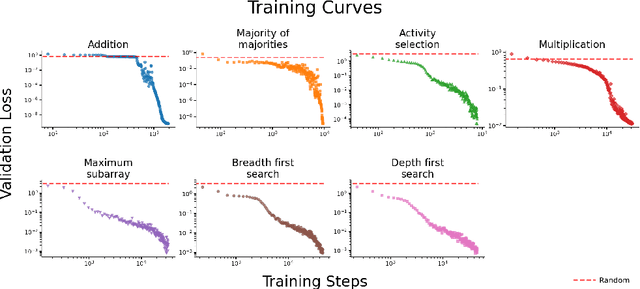
We train Transformer-based language models on ten foundational algorithmic tasks and observe pronounced phase transitions in their loss curves that deviate from established power-law scaling trends. Over large ranges of compute, the validation loss barely improves, then abruptly decreases. Probing the models' internal representations reveals the learning of quiet features during the stagnant phase, followed by sudden acquisition of loud features that coincide with the sharp drop in loss. Our ablation experiments show that disrupting a single learned feature can dramatically degrade performance, providing evidence of their causal role in task performance. These findings challenge the prevailing assumption that next-token predictive loss reliably tracks incremental progress; instead, key internal features may be developing below the surface until they coalesce, triggering a rapid performance gain.
DORIS-MAE: Scientific Document Retrieval using Multi-level Aspect-based Queries
Oct 10, 2023In scientific research, the ability to effectively retrieve relevant documents based on complex, multifaceted queries is critical. Existing evaluation datasets for this task are limited, primarily due to the high cost and effort required to annotate resources that effectively represent complex queries. To address this, we propose a novel task, Scientific DOcument Retrieval using Multi-level Aspect-based quEries (DORIS-MAE), which is designed to handle the complex nature of user queries in scientific research. We developed a benchmark dataset within the field of computer science, consisting of 100 human-authored complex query cases. For each complex query, we assembled a collection of 100 relevant documents and produced annotated relevance scores for ranking them. Recognizing the significant labor of expert annotation, we also introduce Anno-GPT, a scalable framework for validating the performance of Large Language Models (LLMs) on expert-level dataset annotation tasks. LLM annotation of the DORIS-MAE dataset resulted in a 500x reduction in cost, without compromising quality. Furthermore, due to the multi-tiered structure of these complex queries, the DORIS-MAE dataset can be extended to over 4,000 sub-query test cases without requiring additional annotation. We evaluated 17 recent retrieval methods on DORIS-MAE, observing notable performance drops compared to traditional datasets. This highlights the need for better approaches to handle complex, multifaceted queries in scientific research. Our dataset and codebase are available at https://github.com/Real-Doris-Mae/Doris-Mae-Dataset.