 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Spherical Flow Policy for Reinforcement Learning with Combinatorial Actions
Jan 29, 2026Reinforcement learning (RL) with combinatorial action spaces remains challenging because feasible action sets are exponentially large and governed by complex feasibility constraints, making direct policy parameterization impractical. Existing approaches embed task-specific value functions into constrained optimization programs or learn deterministic structured policies, sacrificing generality and policy expressiveness. We propose a solver-induced \emph{latent spherical flow policy} that brings the expressiveness of modern generative policies to combinatorial RL while guaranteeing feasibility by design. Our method, LSFlow, learns a \emph{stochastic} policy in a compact continuous latent space via spherical flow matching, and delegates feasibility to a combinatorial optimization solver that maps each latent sample to a valid structured action. To improve efficiency, we train the value network directly in the latent space, avoiding repeated solver calls during policy optimization. To address the piecewise-constant and discontinuous value landscape induced by solver-based action selection, we introduce a smoothed Bellman operator that yields stable, well-defined learning targets. Empirically, our approach outperforms state-of-the-art baselines by an average of 20.6\% across a range of challenging combinatorial RL tasks.
Generative AI Against Poaching: Latent Composite Flow Matching for Wildlife Conservation
Aug 20, 2025
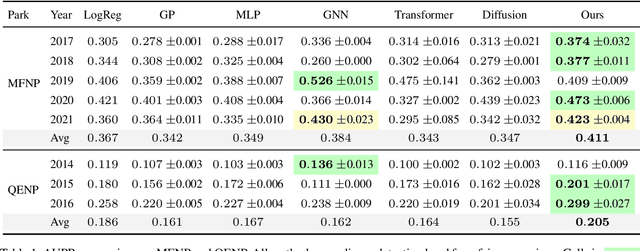
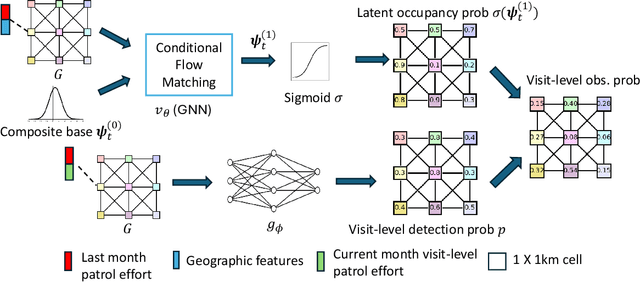
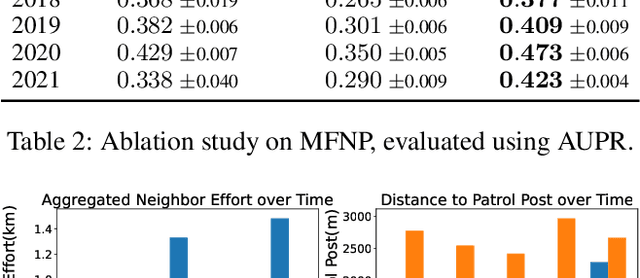
Poaching poses significant threats to wildlife and biodiversity. A valuable step in reducing poaching is to forecast poacher behavior, which can inform patrol planning and other conservation interventions. Existing poaching prediction methods based on linear models or decision trees lack the expressivity to capture complex, nonlinear spatiotemporal patterns. Recent advances in generative modeling, particularly flow matching, offer a more flexible alternative. However, training such models on real-world poaching data faces two central obstacles: imperfect detection of poaching events and limited data. To address imperfect detection, we integrate flow matching with an occupancy-based detection model and train the flow in latent space to infer the underlying occupancy state. To mitigate data scarcity, we adopt a composite flow initialized from a linear-model prediction rather than random noise which is the standard in diffusion models, injecting prior knowledge and improving generalization. Evaluations on datasets from two national parks in Uganda show consistent gains in predictive accuracy.
A Bayesian Approach to Online Learning for Contextual Restless Bandits with Applications to Public Health
Feb 07, 2024



Restless multi-armed bandits (RMABs) are used to model sequential resource allocation in public health intervention programs. In these settings, the underlying transition dynamics are often unknown a priori, requiring online reinforcement learning (RL). However, existing methods in online RL for RMABs cannot incorporate properties often present in real-world public health applications, such as contextual information and non-stationarity. We present Bayesian Learning for Contextual RMABs (BCoR), an online RL approach for RMABs that novelly combines techniques in Bayesian modeling with Thompson sampling to flexibly model a wide range of complex RMAB settings, such as contextual and non-stationary RMABs. A key contribution of our approach is its ability to leverage shared information within and between arms to learn unknown RMAB transition dynamics quickly in budget-constrained settings with relatively short time horizons. Empirically, we show that BCoR achieves substantially higher finite-sample performance than existing approaches over a range of experimental settings, including one constructed from a real-world public health campaign in India.
Reflections from the Workshop on AI-Assisted Decision Making for Conservation
Jul 17, 2023

In this white paper, we synthesize key points made during presentations and discussions from the AI-Assisted Decision Making for Conservation workshop, hosted by the Center for Research on Computation and Society at Harvard University on October 20-21, 2022. We identify key open research questions in resource allocation, planning, and interventions for biodiversity conservation, highlighting conservation challenges that not only require AI solutions, but also require novel methodological advances. In addition to providing a summary of the workshop talks and discussions, we hope this document serves as a call-to-action to orient the expansion of algorithmic decision-making approaches to prioritize real-world conservation challenges, through collaborative efforts of ecologists, conservation decision-makers, and AI researchers.
Artificial Replay: A Meta-Algorithm for Harnessing Historical Data in Bandits
Sep 30, 2022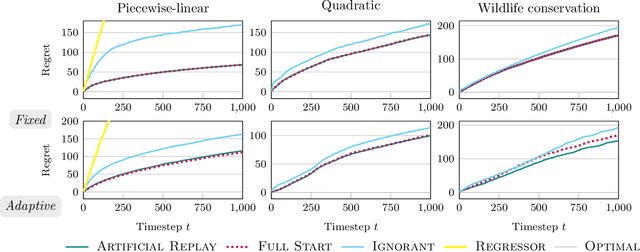

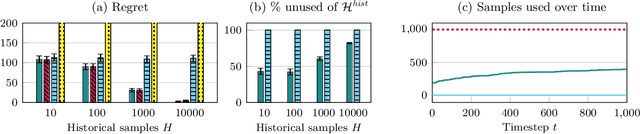
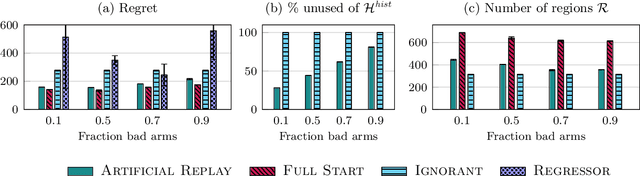
While standard bandit algorithms sometimes incur high regret, their performance can be greatly improved by "warm starting" with historical data. Unfortunately, how best to incorporate historical data is unclear: naively initializing reward estimates using all historical samples can suffer from spurious data and imbalanced data coverage, leading to computational and storage issues - particularly in continuous action spaces. We address these two challenges by proposing Artificial Replay, a meta-algorithm for incorporating historical data into any arbitrary base bandit algorithm. Artificial Replay uses only a subset of the historical data as needed to reduce computation and storage. We show that for a broad class of base algorithms that satisfy independence of irrelevant data (IIData), a novel property that we introduce, our method achieves equal regret as a full warm-start approach while potentially using only a fraction of the historical data. We complement these theoretical results with a case study of $K$-armed and continuous combinatorial bandit algorithms, including on a green security domain using real poaching data, to show the practical benefits of Artificial Replay in achieving optimal regret alongside low computational and storage costs.
Optimistic Whittle Index Policy: Online Learning for Restless Bandits
May 30, 2022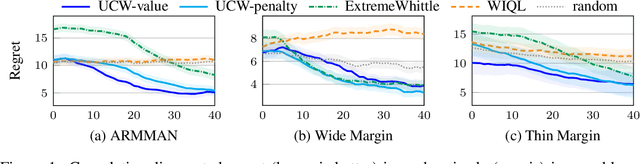

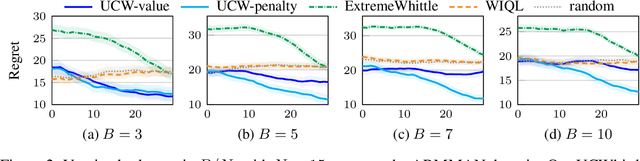
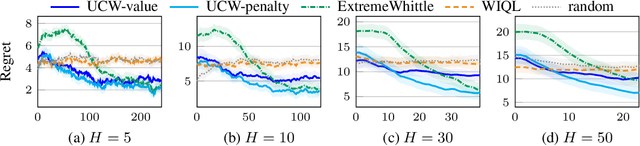
Restless multi-armed bandits (RMABs) extend multi-armed bandits to allow for stateful arms, where the state of each arm evolves restlessly with different transitions depending on whether that arm is pulled. However, solving RMABs requires information on transition dynamics, which is often not available upfront. To plan in RMAB settings with unknown transitions, we propose the first online learning algorithm based on the Whittle index policy, using an upper confidence bound (UCB) approach to learn transition dynamics. Specifically, we formulate a bilinear program to compute the optimistic Whittle index from the confidence bounds in transition dynamics. Our algorithm, UCWhittle, achieves sublinear $O(\sqrt{T \log T})$ frequentist regret to solve RMABs with unknown transitions. Empirically, we demonstrate that UCWhittle leverages the structure of RMABs and the Whittle index policy solution to achieve better performance than existing online learning baselines across three domains, including on real-world maternal and childcare data aimed at reducing maternal mortality.
Ranked Prioritization of Groups in Combinatorial Bandit Allocation
May 11, 2022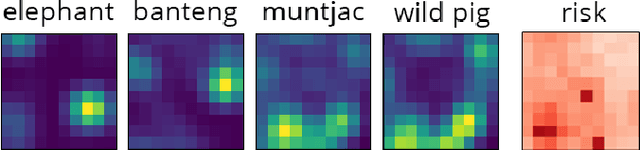
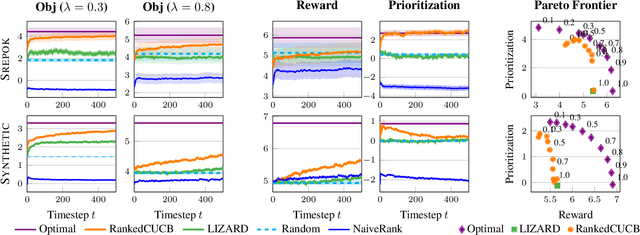
Preventing poaching through ranger patrols protects endangered wildlife, directly contributing to the UN Sustainable Development Goal 15 of life on land. Combinatorial bandits have been used to allocate limited patrol resources, but existing approaches overlook the fact that each location is home to multiple species in varying proportions, so a patrol benefits each species to differing degrees. When some species are more vulnerable, we ought to offer more protection to these animals; unfortunately, existing combinatorial bandit approaches do not offer a way to prioritize important species. To bridge this gap, (1) We propose a novel combinatorial bandit objective that trades off between reward maximization and also accounts for prioritization over species, which we call ranked prioritization. We show this objective can be expressed as a weighted linear sum of Lipschitz-continuous reward functions. (2) We provide RankedCUCB, an algorithm to select combinatorial actions that optimize our prioritization-based objective, and prove that it achieves asymptotic no-regret. (3) We demonstrate empirically that RankedCUCB leads to up to 38% improvement in outcomes for endangered species using real-world wildlife conservation data. Along with adapting to other challenges such as preventing illegal logging and overfishing, our no-regret algorithm addresses the general combinatorial bandit problem with a weighted linear objective.
Robust Restless Bandits: Tackling Interval Uncertainty with Deep Reinforcement Learning
Jul 04, 2021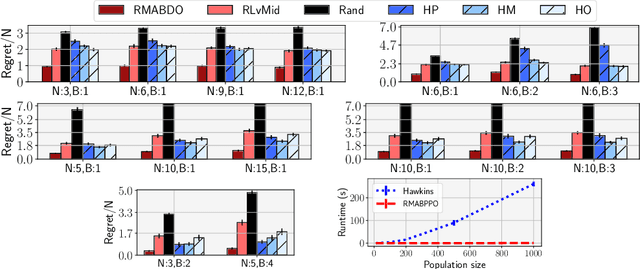
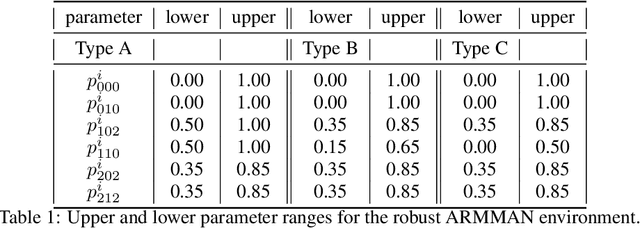
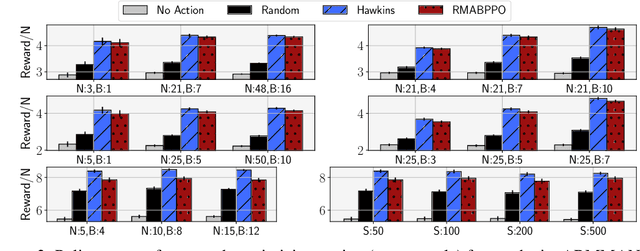

We introduce Robust Restless Bandits, a challenging generalization of restless multi-arm bandits (RMAB). RMABs have been widely studied for intervention planning with limited resources. However, most works make the unrealistic assumption that the transition dynamics are known perfectly, restricting the applicability of existing methods to real-world scenarios. To make RMABs more useful in settings with uncertain dynamics: (i) We introduce the Robust RMAB problem and develop solutions for a minimax regret objective when transitions are given by interval uncertainties; (ii) We develop a double oracle algorithm for solving Robust RMABs and demonstrate its effectiveness on three experimental domains; (iii) To enable our double oracle approach, we introduce RMABPPO, a novel deep reinforcement learning algorithm for solving RMABs. RMABPPO hinges on learning an auxiliary "$\lambda$-network" that allows each arm's learning to decouple, greatly reducing sample complexity required for training; (iv) Under minimax regret, the adversary in the double oracle approach is notoriously difficult to implement due to non-stationarity. To address this, we formulate the adversary oracle as a multi-agent reinforcement learning problem and solve it with a multi-agent extension of RMABPPO, which may be of independent interest as the first known algorithm for this setting. Code is available at https://github.com/killian-34/RobustRMAB.
Robust Reinforcement Learning Under Minimax Regret for Green Security
Jun 15, 2021
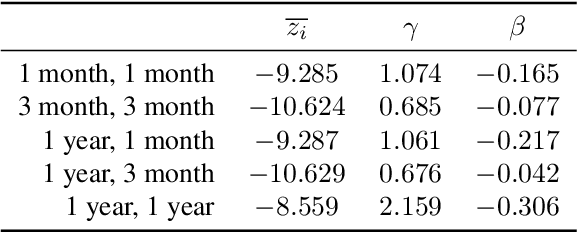
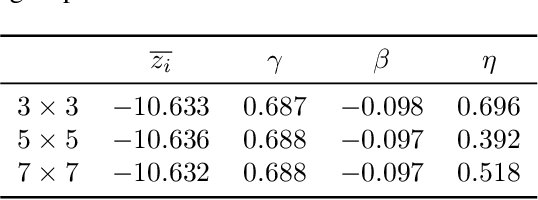
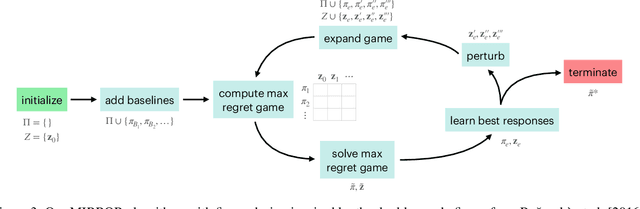
Green security domains feature defenders who plan patrols in the face of uncertainty about the adversarial behavior of poachers, illegal loggers, and illegal fishers. Importantly, the deterrence effect of patrols on adversaries' future behavior makes patrol planning a sequential decision-making problem. Therefore, we focus on robust sequential patrol planning for green security following the minimax regret criterion, which has not been considered in the literature. We formulate the problem as a game between the defender and nature who controls the parameter values of the adversarial behavior and design an algorithm MIRROR to find a robust policy. MIRROR uses two reinforcement learning-based oracles and solves a restricted game considering limited defender strategies and parameter values. We evaluate MIRROR on real-world poaching data.
Envisioning Communities: A Participatory Approach Towards AI for Social Good
May 04, 2021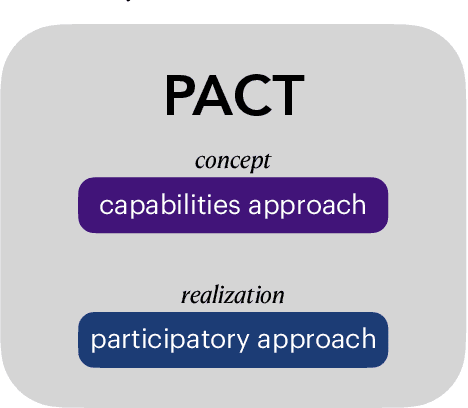
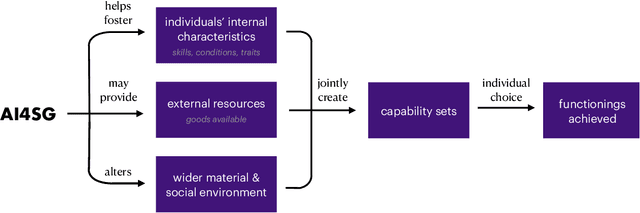
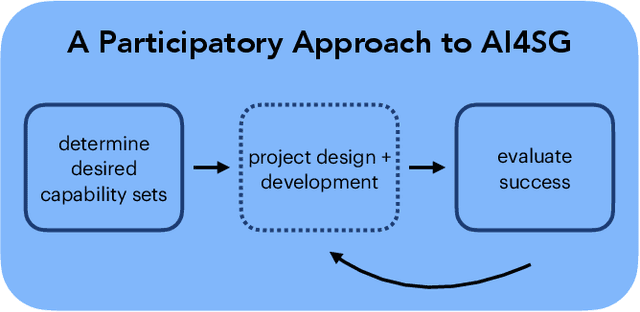
Research in artificial intelligence (AI) for social good presupposes some definition of social good, but potential definitions have been seldom suggested and never agreed upon. The normative question of what AI for social good research should be "for" is not thoughtfully elaborated, or is frequently addressed with a utilitarian outlook that prioritizes the needs of the majority over those who have been historically marginalized, brushing aside realities of injustice and inequity. We argue that AI for social good ought to be assessed by the communities that the AI system will impact, using as a guide the capabilities approach, a framework to measure the ability of different policies to improve human welfare equity. Furthermore, we lay out how AI research has the potential to catalyze social progress by expanding and equalizing capabilities. We show how the capabilities approach aligns with a participatory approach for the design and implementation of AI for social good research in a framework we introduce called PACT, in which community members affected should be brought in as partners and their input prioritized throughout the project. We conclude by providing an incomplete set of guiding questions for carrying out such participatory AI research in a way that elicits and respects a community's own definition of social good.