 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiHi-GS: LiDAR-Supervised Gaussian Splatting for Highway Driving Scene Reconstruction
Dec 19, 2024



Photorealistic 3D scene reconstruction plays an important role in autonomous driving, enabling the generation of novel data from existing datasets to simulate safety-critical scenarios and expand training data without additional acquisition costs. Gaussian Splatting (GS) facilitates real-time, photorealistic rendering with an explicit 3D Gaussian representation of the scene, providing faster processing and more intuitive scene editing than the implicit Neural Radiance Fields (NeRFs). While extensive GS research has yielded promising advancements in autonomous driving applications, they overlook two critical aspects: First, existing methods mainly focus on low-speed and feature-rich urban scenes and ignore the fact that highway scenarios play a significant role in autonomous driving. Second, while LiDARs are commonplace in autonomous driving platforms, existing methods learn primarily from images and use LiDAR only for initial estimates or without precise sensor modeling, thus missing out on leveraging the rich depth information LiDAR offers and limiting the ability to synthesize LiDAR data. In this paper, we propose a novel GS method for dynamic scene synthesis and editing with improved scene reconstruction through LiDAR supervision and support for LiDAR rendering. Unlike prior works that are tested mostly on urban datasets, to the best of our knowledge, we are the first to focus on the more challenging and highly relevant highway scenes for autonomous driving, with sparse sensor views and monotone backgrounds.
LANe: Lighting-Aware Neural Fields for Compositional Scene Synthesis
Apr 06, 2023



Neural fields have recently enjoyed great success in representing and rendering 3D scenes. However, most state-of-the-art implicit representations model static or dynamic scenes as a whole, with minor variations. Existing work on learning disentangled world and object neural fields do not consider the problem of composing objects into different world neural fields in a lighting-aware manner. We present Lighting-Aware Neural Field (LANe) for the compositional synthesis of driving scenes in a physically consistent manner. Specifically, we learn a scene representation that disentangles the static background and transient elements into a world-NeRF and class-specific object-NeRFs to allow compositional synthesis of multiple objects in the scene. Furthermore, we explicitly designed both the world and object models to handle lighting variation, which allows us to compose objects into scenes with spatially varying lighting. This is achieved by constructing a light field of the scene and using it in conjunction with a learned shader to modulate the appearance of the object NeRFs. We demonstrate the performance of our model on a synthetic dataset of diverse lighting conditions rendered with the CARLA simulator, as well as a novel real-world dataset of cars collected at different times of the day. Our approach shows that it outperforms state-of-the-art compositional scene synthesis on the challenging dataset setup, via composing object-NeRFs learned from one scene into an entirely different scene whilst still respecting the lighting variations in the novel scene. For more results, please visit our project website https://lane-composition.github.io/.
SIMBAR: Single Image-Based Scene Relighting For Effective Data Augmentation For Automated Driving Vision Tasks
Apr 01, 2022
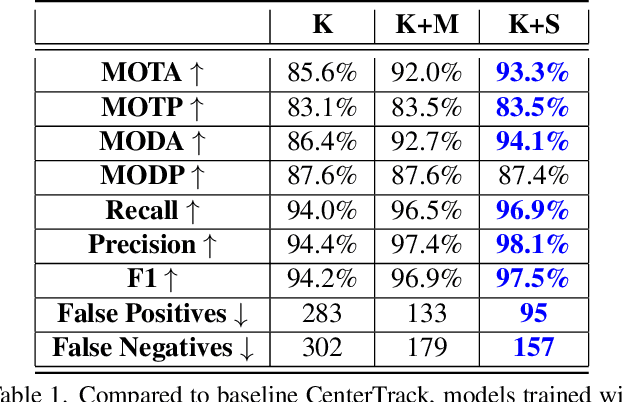
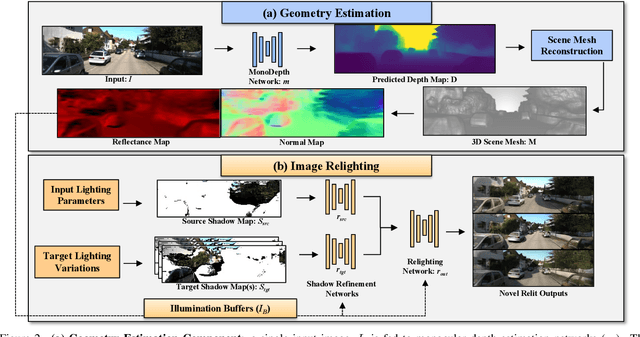
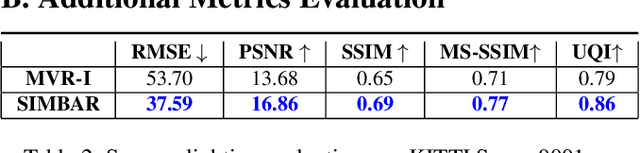
Real-world autonomous driving datasets comprise of images aggregated from different drives on the road. The ability to relight captured scenes to unseen lighting conditions, in a controllable manner, presents an opportunity to augment datasets with a richer variety of lighting conditions, similar to what would be encountered in the real-world. This paper presents a novel image-based relighting pipeline, SIMBAR, that can work with a single image as input. To the best of our knowledge, there is no prior work on scene relighting leveraging explicit geometric representations from a single image. We present qualitative comparisons with prior multi-view scene relighting baselines. To further validate and effectively quantify the benefit of leveraging SIMBAR for data augmentation for automated driving vision tasks, object detection and tracking experiments are conducted with a state-of-the-art method, a Multiple Object Tracking Accuracy (MOTA) of 93.3% is achieved with CenterTrack on SIMBAR-augmented KITTI - an impressive 9.0% relative improvement over the baseline MOTA of 85.6% with CenterTrack on original KITTI, both models trained from scratch and tested on Virtual KITTI. For more details and SIMBAR relit datasets, please visit our project website (https://simbarv1.github.io/).
Deflating Dataset Bias Using Synthetic Data Augmentation
Apr 28, 2020
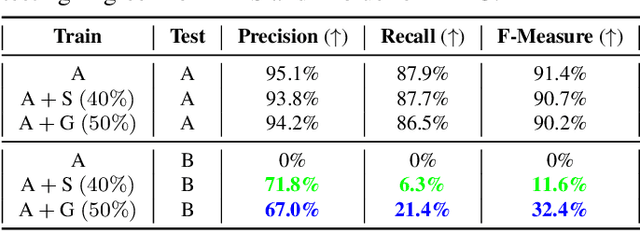

Deep Learning has seen an unprecedented increase in vision applications since the publication of large-scale object recognition datasets and introduction of scalable compute hardware. State-of-the-art methods for most vision tasks for Autonomous Vehicles (AVs) rely on supervised learning and often fail to generalize to domain shifts and/or outliers. Dataset diversity is thus key to successful real-world deployment. No matter how big the size of the dataset, capturing long tails of the distribution pertaining to task-specific environmental factors is impractical. The goal of this paper is to investigate the use of targeted synthetic data augmentation - combining the benefits of gaming engine simulations and sim2real style transfer techniques - for filling gaps in real datasets for vision tasks. Empirical studies on three different computer vision tasks of practical use to AVs - parking slot detection, lane detection and monocular depth estimation - consistently show that having synthetic data in the training mix provides a significant boost in cross-dataset generalization performance as compared to training on real data only, for the same size of the training set.
On the Role of Receptive Field in Unsupervised Sim-to-Real Image Translation
Jan 25, 2020
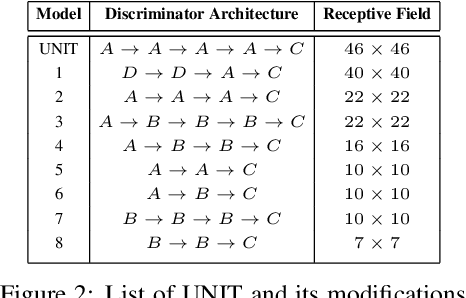
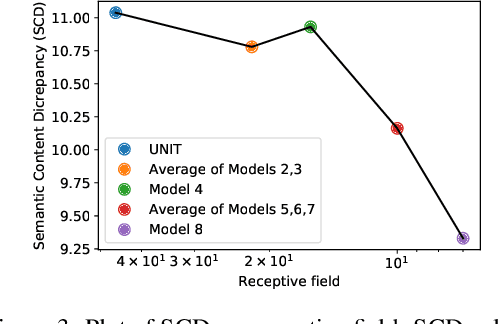

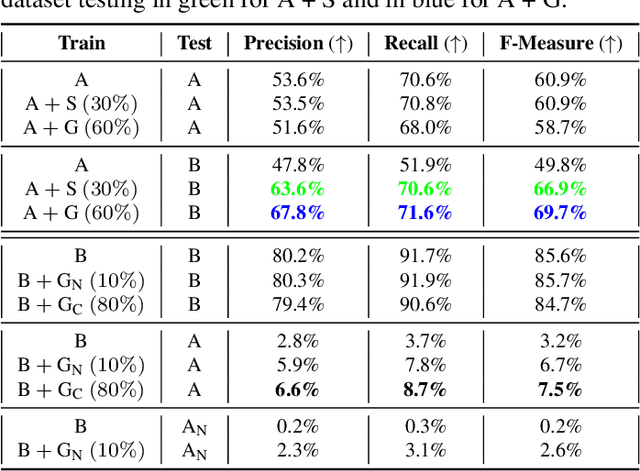
Generative Adversarial Networks (GANs) are now widely used for photo-realistic image synthesis. In applications where a simulated image needs to be translated into a realistic image (sim-to-real), GANs trained on unpaired data from the two domains are susceptible to failure in semantic content retention as the image is translated from one domain to the other. This failure mode is more pronounced in cases where the real data lacks content diversity, resulting in a content \emph{mismatch} between the two domains - a situation often encountered in real-world deployment. In this paper, we investigate the role of the discriminator's receptive field in GANs for unsupervised image-to-image translation with mismatched data, and study its effect on semantic content retention. Experiments with the discriminator architecture of a state-of-the-art coupled Variational Auto-Encoder (VAE) - GAN model on diverse, mismatched datasets show that the discriminator receptive field is directly correlated with semantic content discrepancy of the generated image.
Context-Aware Pedestrian Motion Prediction In Urban Intersections
Jun 25, 2018
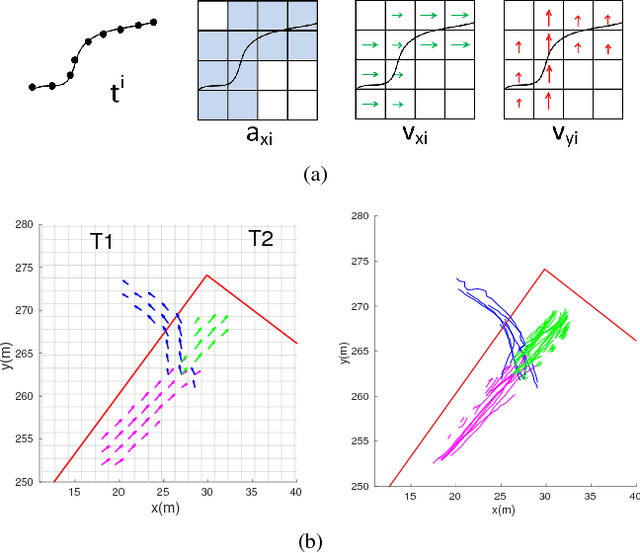
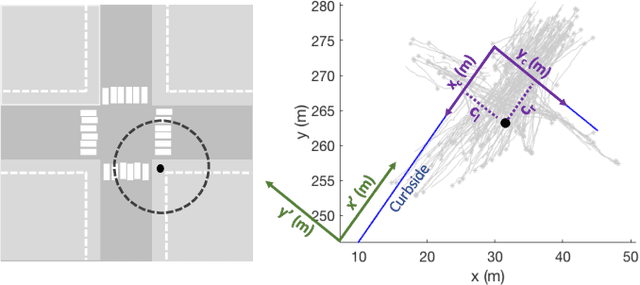
This paper presents a novel context-based approach for pedestrian motion prediction in crowded, urban intersections, with the additional flexibility of prediction in similar, but new, environments. Previously, Chen et. al. combined Markovian-based and clustering-based approaches to learn motion primitives in a grid-based world and subsequently predict pedestrian trajectories by modeling the transition between learned primitives as a Gaussian Process (GP). This work extends that prior approach by incorporating semantic features from the environment (relative distance to curbside and status of pedestrian traffic lights) in the GP formulation for more accurate predictions of pedestrian trajectories over the same timescale. We evaluate the new approach on real-world data collected using one of the vehicles in the MIT Mobility On Demand fleet. The results show 12.5% improvement in prediction accuracy and a 2.65 times reduction in Area Under the Curve (AUC), which is used as a metric to quantify the span of predicted set of trajectories, such that a lower AUC corresponds to a higher level of confidence in the future direction of pedestrian motion.
A Transferable Pedestrian Motion Prediction Model for Intersections with Different Geometries
Jun 25, 2018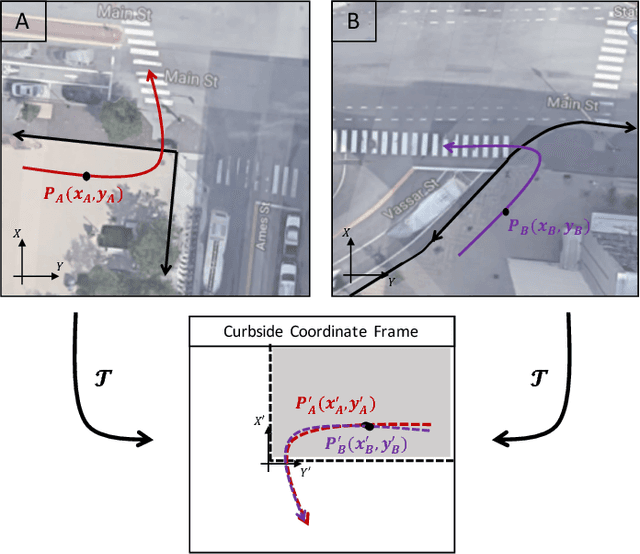
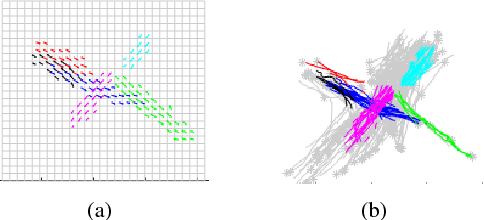
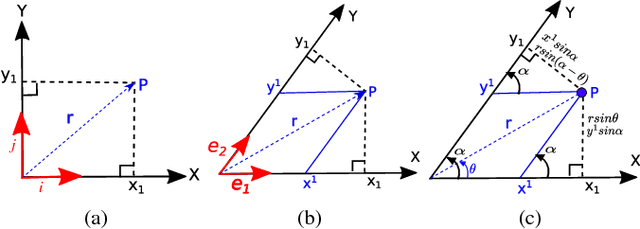
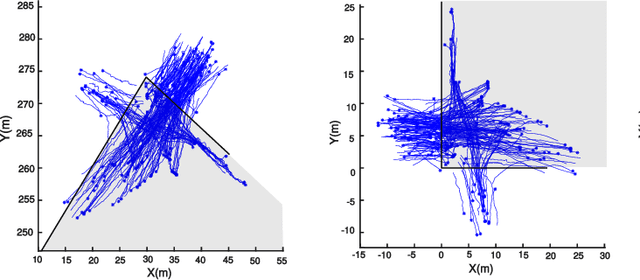
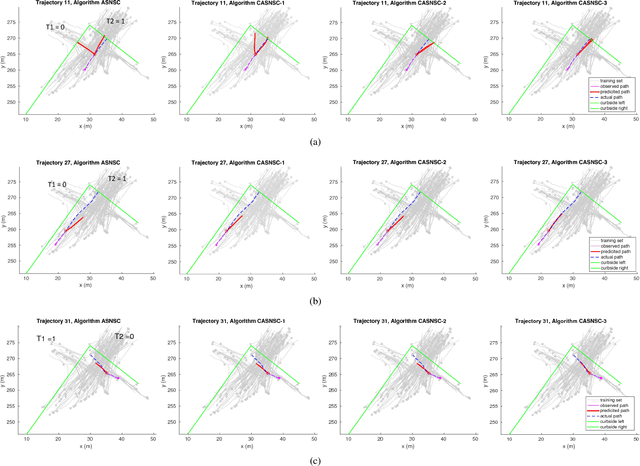
This paper presents a novel framework for accurate pedestrian intent prediction at intersections. Given some prior knowledge of the curbside geometry, the presented framework can accurately predict pedestrian trajectories, even in new intersections that it has not been trained on. This is achieved by making use of the contravariant components of trajectories in the curbside coordinate system, which ensures that the transformation of trajectories across intersections is affine, regardless of the curbside geometry. Our method is based on the Augmented Semi Nonnegative Sparse Coding (ASNSC) formulation and we use that as a baseline to show improvement in prediction performance on real pedestrian datasets collected at two intersections in Cambridge, with distinctly different curbside and crosswalk geometries. We demonstrate a 7.2% improvement in prediction accuracy in the case of same train and test intersections. Furthermore, we show a comparable prediction performance of TASNSC when trained and tested in different intersections with the baseline, trained and tested on the same intersection.