 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Vision-based Navigation for a Robot in an Indoor Environment
Jul 02, 2023This paper presents a study on the development of an obstacle-avoidance navigation system for autonomous navigation in home environments. The system utilizes vision-based techniques and advanced path-planning algorithms to enable the robot to navigate toward the destination while avoiding obstacles. The performance of the system is evaluated through qualitative and quantitative metrics, highlighting its strengths and limitations. The findings contribute to the advancement of indoor robot navigation, showcasing the potential of vision-based techniques for real-time, autonomous navigation.
Look Both Ways: Bidirectional Visual Sensing for Automatic Multi-Camera Registration
Aug 15, 2022



This work describes the automatic registration of a large network (approximately 40) of fixed, ceiling-mounted environment cameras spread over a large area (approximately 800 squared meters) using a mobile calibration robot equipped with a single upward-facing fisheye camera and a backlit ArUco marker for easy detection. The fisheye camera is used to do visual odometry (VO), and the ArUco marker facilitates easy detection of the calibration robot in the environment cameras. In addition, the fisheye camera is also able to detect the environment cameras. This two-way, bidirectional detection constrains the pose of the environment cameras to solve an optimization problem. Such an approach can be used to automatically register a large-scale multi-camera system used for surveillance, automated parking, or robotic applications. This VO based multicamera registration method is extensively validated using real-world experiments, and also compared against a similar approach which uses an LiDAR - an expensive, heavier and power hungry sensor.
S-BEV: Semantic Birds-Eye View Representation for Weather and Lighting Invariant 3-DoF Localization
Jan 23, 2021
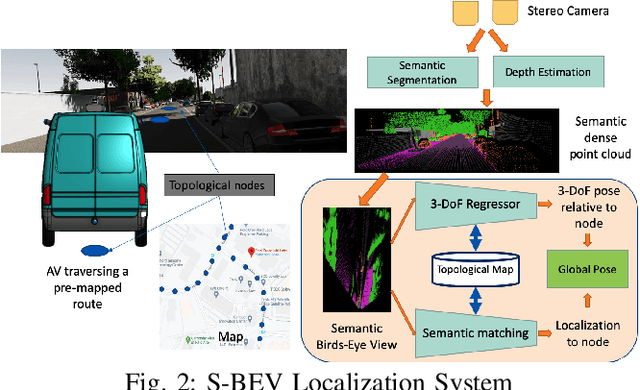
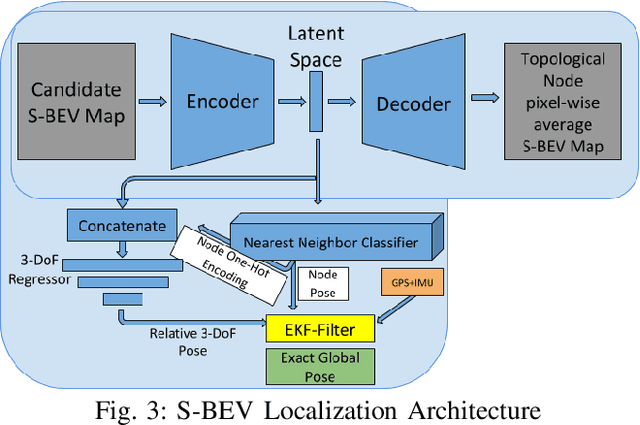

We describe a light-weight, weather and lighting invariant, Semantic Bird's Eye View (S-BEV) signature for vision-based vehicle re-localization. A topological map of S-BEV signatures is created during the first traversal of the route, which are used for coarse localization in subsequent route traversal. A fine-grained localizer is then trained to output the global 3-DoF pose of the vehicle using its S-BEV and its coarse localization. We conduct experiments on vKITTI2 virtual dataset and show the potential of the S-BEV to be robust to weather and lighting. We also demonstrate results with 2 vehicles on a 22 km long highway route in the Ford AV dataset.
Deflating Dataset Bias Using Synthetic Data Augmentation
Apr 28, 2020
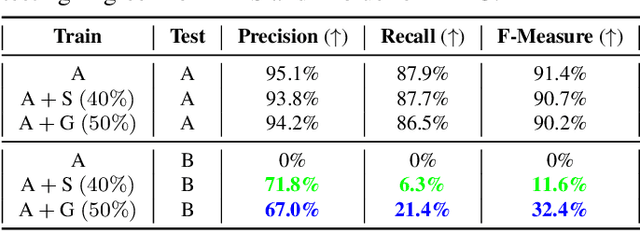

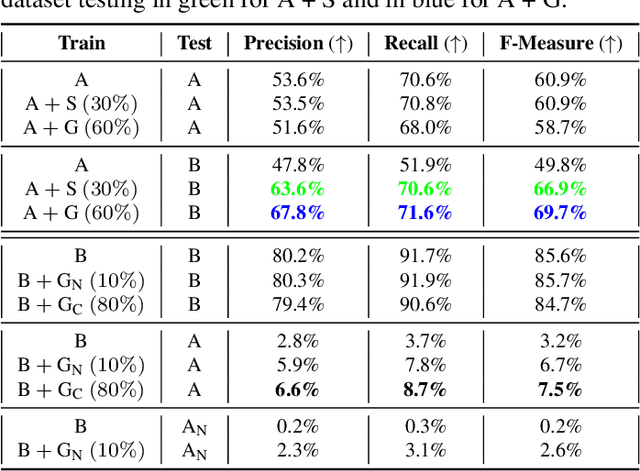
Deep Learning has seen an unprecedented increase in vision applications since the publication of large-scale object recognition datasets and introduction of scalable compute hardware. State-of-the-art methods for most vision tasks for Autonomous Vehicles (AVs) rely on supervised learning and often fail to generalize to domain shifts and/or outliers. Dataset diversity is thus key to successful real-world deployment. No matter how big the size of the dataset, capturing long tails of the distribution pertaining to task-specific environmental factors is impractical. The goal of this paper is to investigate the use of targeted synthetic data augmentation - combining the benefits of gaming engine simulations and sim2real style transfer techniques - for filling gaps in real datasets for vision tasks. Empirical studies on three different computer vision tasks of practical use to AVs - parking slot detection, lane detection and monocular depth estimation - consistently show that having synthetic data in the training mix provides a significant boost in cross-dataset generalization performance as compared to training on real data only, for the same size of the training set.