 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hyperdimensional One Place Signature to Represent Them All: Stackable Descriptors For Visual Place Recognition
Dec 09, 2024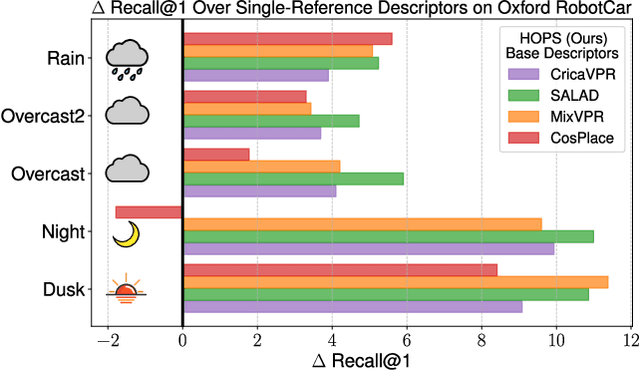
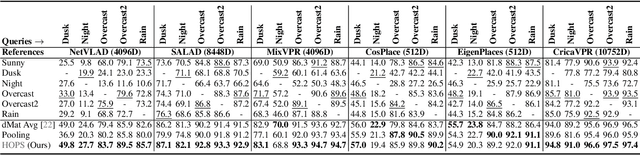
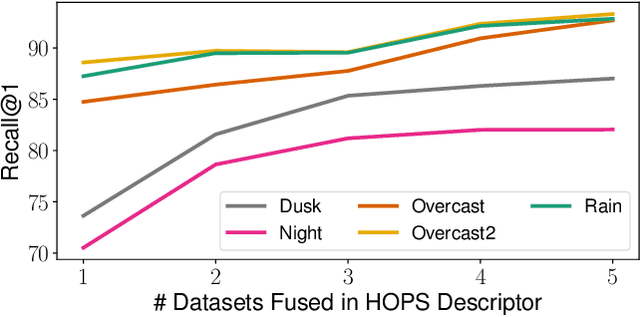
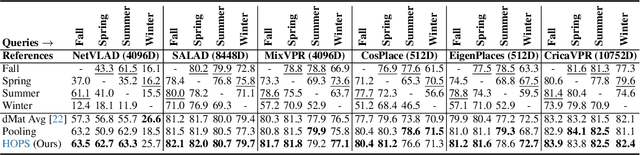
Visual Place Recognition (VPR) enables coarse localization by comparing query images to a reference database of geo-tagged images. Recent breakthroughs in deep learning architectures and training regimes have led to methods with improved robustness to factors like environment appearance change, but with the downside that the required training and/or matching compute scales with the number of distinct environmental conditions encountered. Here, we propose Hyperdimensional One Place Signatures (HOPS) to simultaneously improve the performance, compute and scalability of these state-of-the-art approaches by fusing the descriptors from multiple reference sets captured under different conditions. HOPS scales to any number of environmental conditions by leveraging the Hyperdimensional Computing framework. Extensive evaluations demonstrate that our approach is highly generalizable and consistently improves recall performance across all evaluated VPR methods and datasets by large margins. Arbitrarily fusing reference images without compute penalty enables numerous other useful possibilities, three of which we demonstrate here: descriptor dimensionality reduction with no performance penalty, stacking synthetic images, and coarse localization to an entire traverse or environmental section.
Improving Visual Place Recognition Based Robot Navigation Through Verification of Localization Estimates
Jul 11, 2024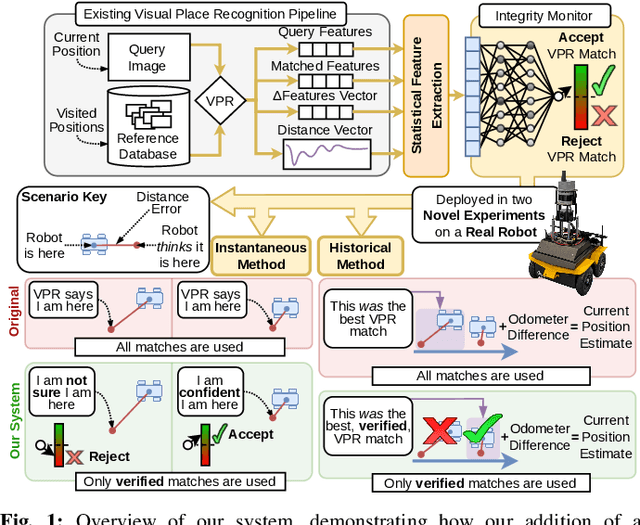
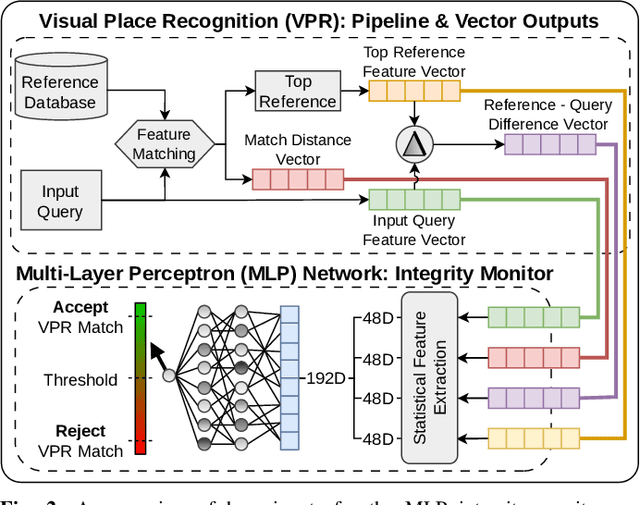
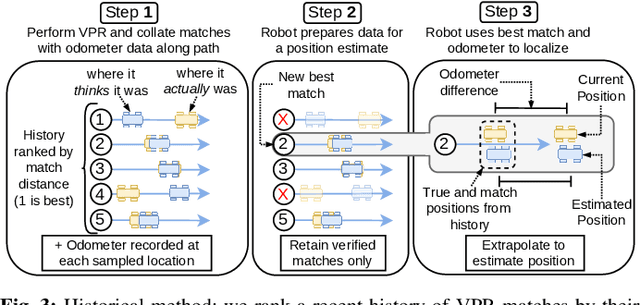
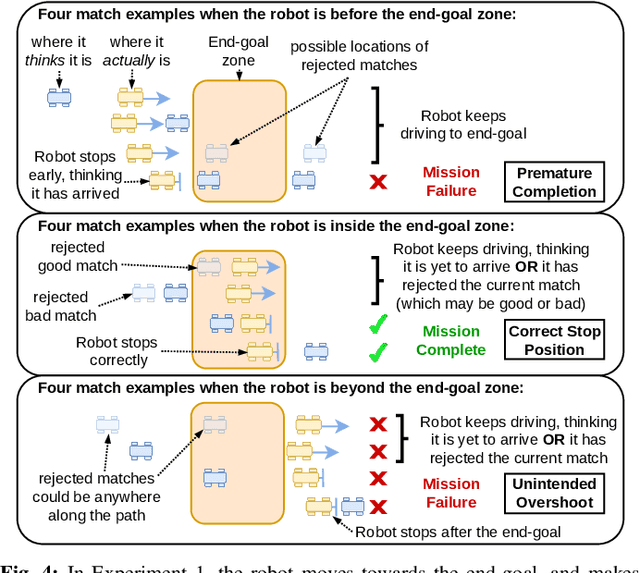
Visual Place Recognition (VPR) systems often have imperfect performance, which affects robot navigation decisions. This research introduces a novel Multi-Layer Perceptron (MLP) integrity monitor for VPR which demonstrates improved performance and generalizability over the previous state-of-the-art SVM approach, removing per-environment training and reducing manual tuning requirements. We test our proposed system in extensive real-world experiments, where we also present two real-time integrity-based VPR verification methods: an instantaneous rejection method for a robot navigating to a goal zone (Experiment 1); and a historical method that takes a best, verified, match from its recent trajectory and uses an odometer to extrapolate forwards to a current position estimate (Experiment 2). Noteworthy results for Experiment 1 include a decrease in aggregate mean along-track goal error from ~9.8m to ~3.1m in missions the robot pursued to completion, and an increase in the aggregate rate of successful mission completion from ~41% to ~55%. Experiment 2 showed a decrease in aggregate mean along-track localization error from ~2.0m to ~0.5m, and an increase in the aggregate precision of localization attempts from ~97% to ~99%. Overall, our results demonstrate the practical usefulness of a VPR integrity monitor in real-world robotics to improve VPR localization and consequent navigation performance.
Dynamically Modulating Visual Place Recognition Sequence Length For Minimum Acceptable Performance Scenarios
Jul 01, 2024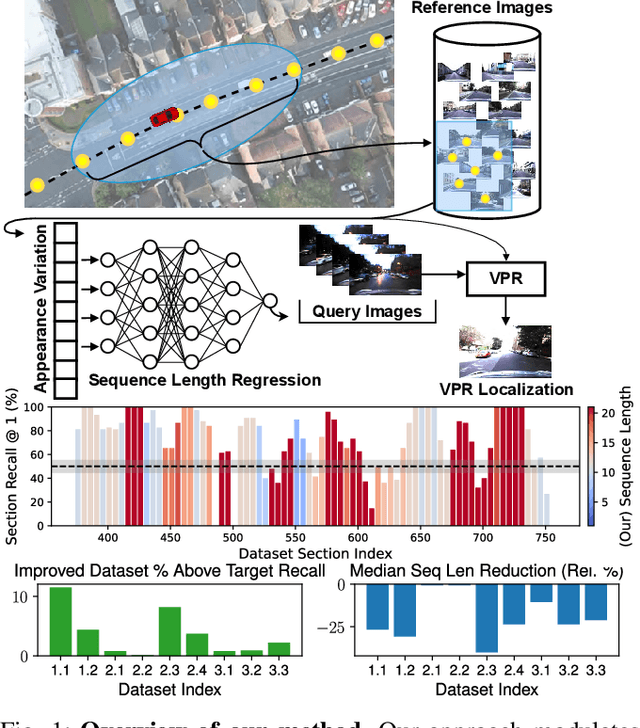
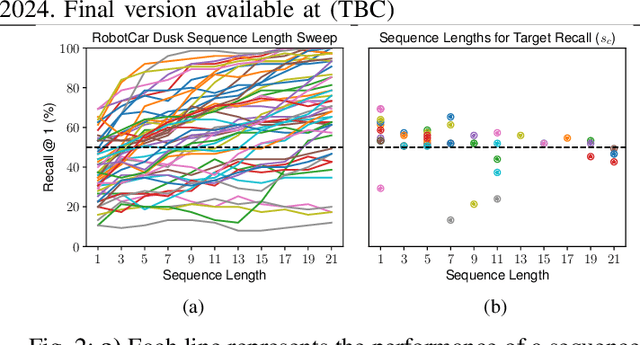
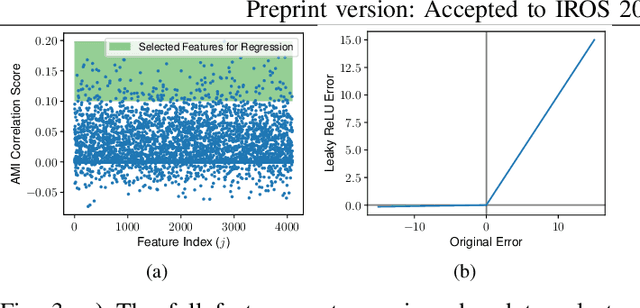

Mobile robots and autonomous vehicles are often required to function in environments where critical position estimates from sensors such as GPS become uncertain or unreliable. Single image visual place recognition (VPR) provides an alternative for localization but often requires techniques such as sequence matching to improve robustness, which incurs additional computation and latency costs. Even then, the sequence length required to localize at an acceptable performance level varies widely; and simply setting overly long fixed sequence lengths creates unnecessary latency, computational overhead, and can even degrade performance. In these scenarios it is often more desirable to meet or exceed a set target performance at minimal expense. In this paper we present an approach which uses a calibration set of data to fit a model that modulates sequence length for VPR as needed to exceed a target localization performance. We make use of a coarse position prior, which could be provided by any other localization system, and capture the variation in appearance across this region. We use the correlation between appearance variation and sequence length to curate VPR features and fit a multilayer perceptron (MLP) for selecting the optimal length. We demonstrate that this method is effective at modulating sequence length to maximize the number of sections in a dataset which meet or exceed a target performance whilst minimizing the median length used. We show applicability across several datasets and reveal key phenomena like generalization capabilities, the benefits of curating features and the utility of non-state-of-the-art feature extractors with nuanced properties.
Boosting Performance of a Baseline Visual Place Recognition Technique by Predicting the Maximally Complementary Technique
Oct 14, 2022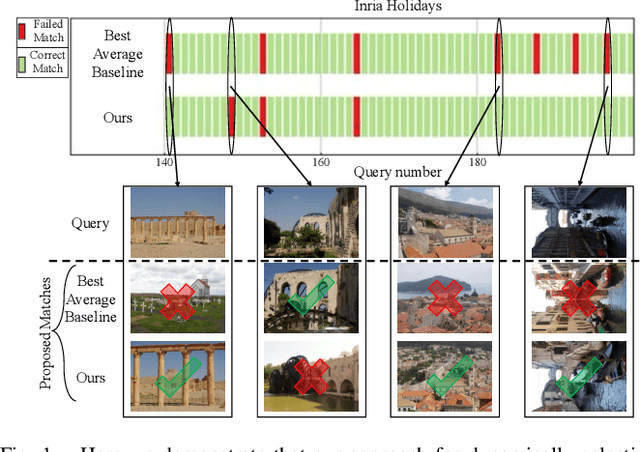
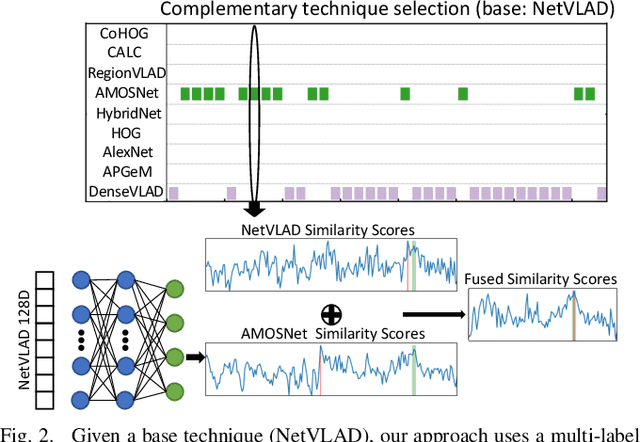
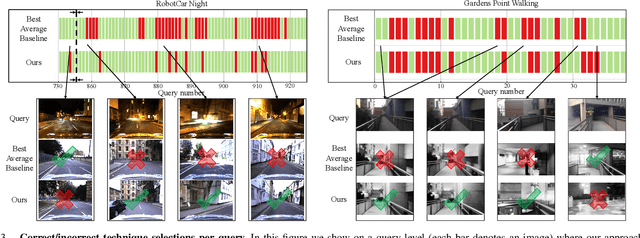
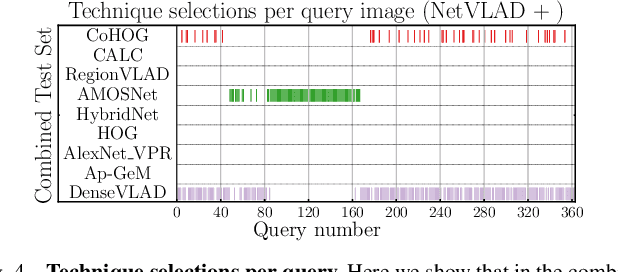
One recent promising approach to the Visual Place Recognition (VPR) problem has been to fuse the place recognition estimates of multiple complementary VPR techniques using methods such as SRAL and multi-process fusion. These approaches come with a substantial practical limitation: they require all potential VPR methods to be brute-force run before they are selectively fused. The obvious solution to this limitation is to predict the viable subset of methods ahead of time, but this is challenging because it requires a predictive signal within the imagery itself that is indicative of high performance methods. Here we propose an alternative approach that instead starts with a known single base VPR technique, and learns to predict the most complementary additional VPR technique to fuse with it, that results in the largest improvement in performance. The key innovation here is to use a dimensionally reduced difference vector between the query image and the top-retrieved reference image using this baseline technique as the predictive signal of the most complementary additional technique, both during training and inference. We demonstrate that our approach can train a single network to select performant, complementary technique pairs across datasets which span multiple modes of transportation (train, car, walking) as well as to generalise to unseen datasets, outperforming multiple baseline strategies for manually selecting the best technique pairs based on the same training data.
Improving Road Segmentation in Challenging Domains Using Similar Place Priors
May 27, 2022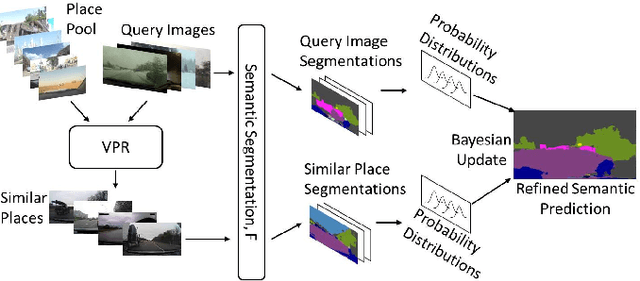
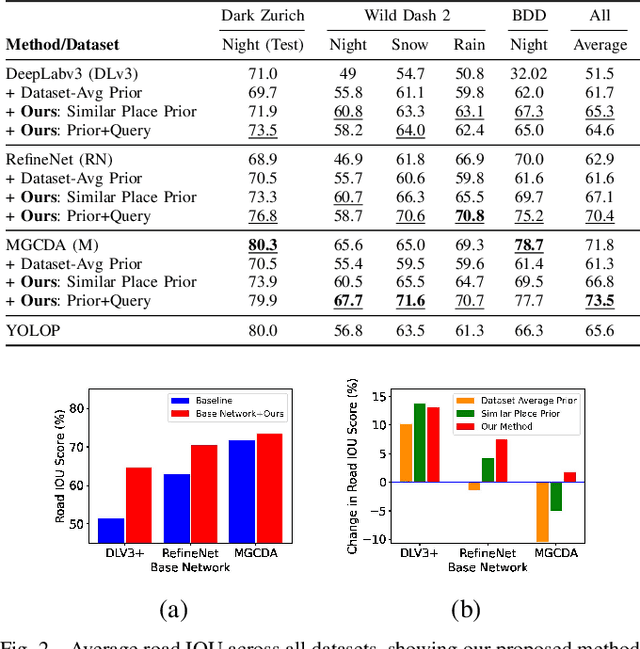
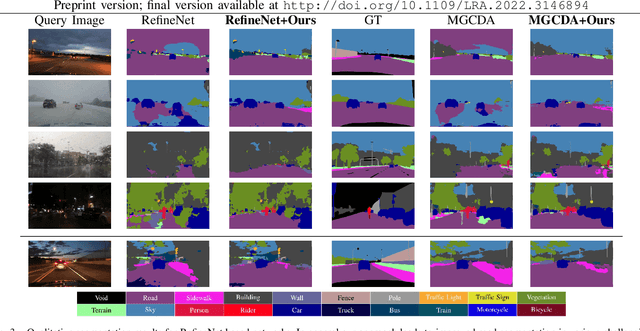
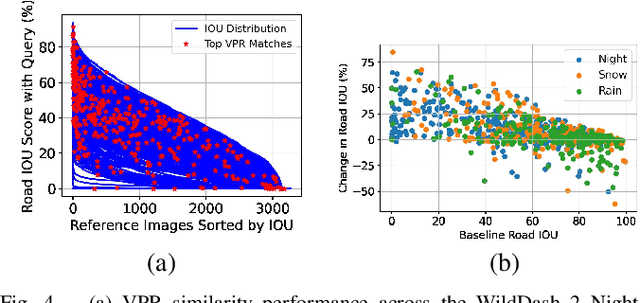
Road segmentation in challenging domains, such as night, snow or rain, is a difficult task. Most current approaches boost performance using fine-tuning, domain adaptation, style transfer, or by referencing previously acquired imagery. These approaches share one or more of three significant limitations: a reliance on large amounts of annotated training data that can be costly to obtain, both anticipation of and training data from the type of environmental conditions expected at inference time, and/or imagery captured from a previous visit to the location. In this research, we remove these restrictions by improving road segmentation based on similar places. We use Visual Place Recognition (VPR) to find similar but geographically distinct places, and fuse segmentations for query images and these similar place priors using a Bayesian approach and novel segmentation quality metric. Ablation studies show the need to re-evaluate notions of VPR utility for this task. We demonstrate the system achieving state-of-the-art road segmentation performance across multiple challenging condition scenarios including night time and snow, without requiring any prior training or previous access to the same geographical locations. Furthermore, we show that this method is network agnostic, improves multiple baseline techniques and is competitive against methods specialised for road prediction.
* Accepted into IEEE Robotics and Automation Letters (RA-L) and presented at IEEE International Conference on Robotics and Automation (ICRA 2022)