 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Performance of a Baseline Visual Place Recognition Technique by Predicting the Maximally Complementary Technique
Paper and Code
Oct 14, 2022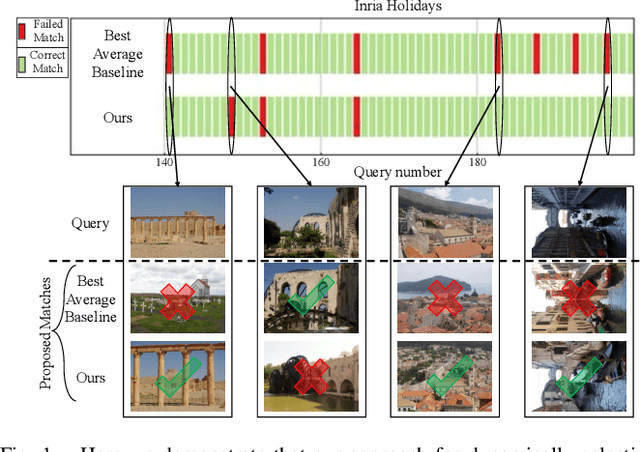
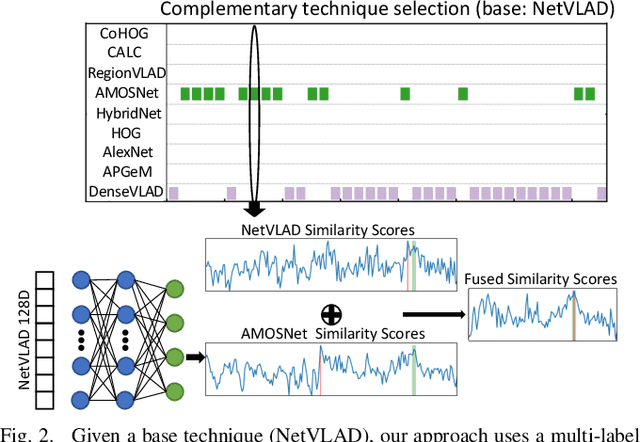
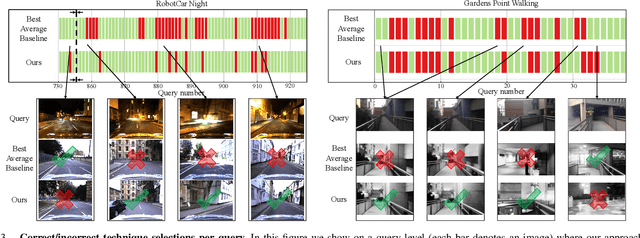
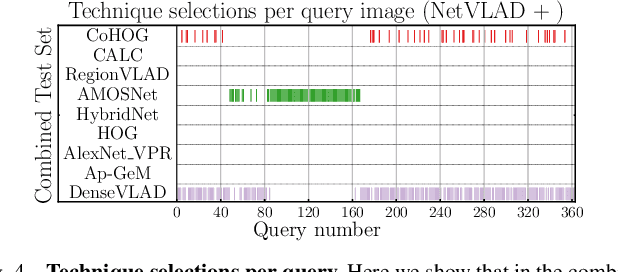
One recent promising approach to the Visual Place Recognition (VPR) problem has been to fuse the place recognition estimates of multiple complementary VPR techniques using methods such as SRAL and multi-process fusion. These approaches come with a substantial practical limitation: they require all potential VPR methods to be brute-force run before they are selectively fused. The obvious solution to this limitation is to predict the viable subset of methods ahead of time, but this is challenging because it requires a predictive signal within the imagery itself that is indicative of high performance methods. Here we propose an alternative approach that instead starts with a known single base VPR technique, and learns to predict the most complementary additional VPR technique to fuse with it, that results in the largest improvement in performance. The key innovation here is to use a dimensionally reduced difference vector between the query image and the top-retrieved reference image using this baseline technique as the predictive signal of the most complementary additional technique, both during training and inference. We demonstrate that our approach can train a single network to select performant, complementary technique pairs across datasets which span multiple modes of transportation (train, car, walking) as well as to generalise to unseen datasets, outperforming multiple baseline strategies for manually selecting the best technique pairs based on the same training data.