 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStates as Strings as Strategies: Steering Language Models with Game-Theoretic Solvers
Feb 06, 2024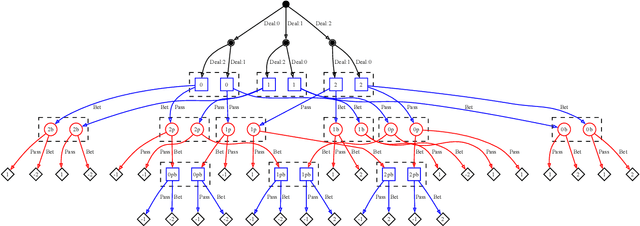

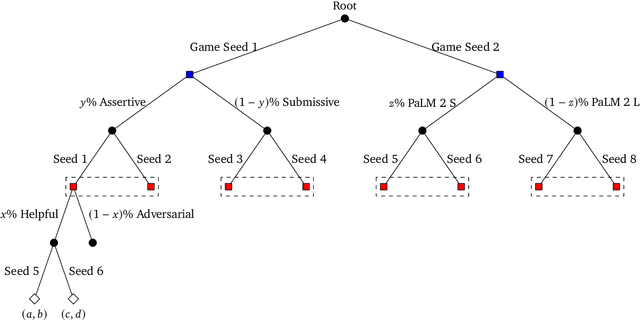
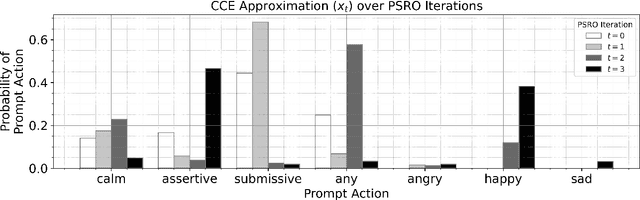
Game theory is the study of mathematical models of strategic interactions among rational agents. Language is a key medium of interaction for humans, though it has historically proven difficult to model dialogue and its strategic motivations mathematically. A suitable model of the players, strategies, and payoffs associated with linguistic interactions (i.e., a binding to the conventional symbolic logic of game theory) would enable existing game-theoretic algorithms to provide strategic solutions in the space of language. In other words, a binding could provide a route to computing stable, rational conversational strategies in dialogue. Large language models (LLMs) have arguably reached a point where their generative capabilities can enable realistic, human-like simulations of natural dialogue. By prompting them in various ways, we can steer their responses towards different output utterances. Leveraging the expressivity of natural language, LLMs can also help us quickly generate new dialogue scenarios, which are grounded in real world applications. In this work, we present one possible binding from dialogue to game theory as well as generalizations of existing equilibrium finding algorithms to this setting. In addition, by exploiting LLMs generation capabilities along with our proposed binding, we can synthesize a large repository of formally-defined games in which one can study and test game-theoretic solution concepts. We also demonstrate how one can combine LLM-driven game generation, game-theoretic solvers, and imitation learning to construct a process for improving the strategic capabilities of LLMs.
Human-Timescale Adaptation in an Open-Ended Task Space
Jan 18, 2023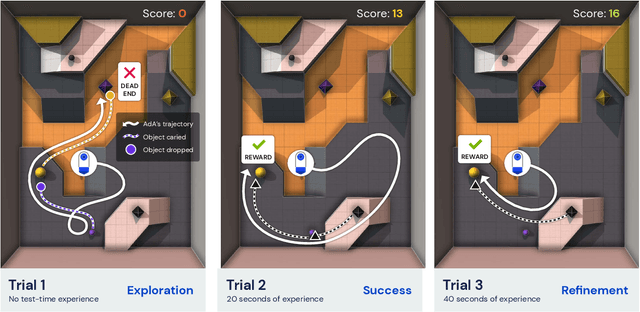
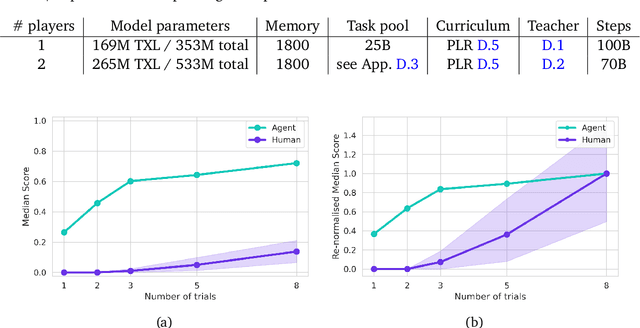
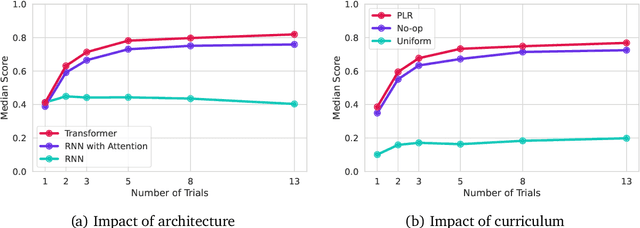
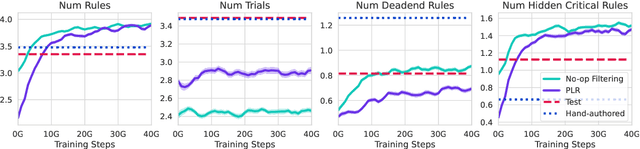
Foundation models have shown impressive adaptation and scalability in supervised and self-supervised learning problems, but so far these successes have not fully translated to reinforcement learning (RL). In this work, we demonstrate that training an RL agent at scale leads to a general in-context learning algorithm that can adapt to open-ended novel embodied 3D problems as quickly as humans. In a vast space of held-out environment dynamics, our adaptive agent (AdA) displays on-the-fly hypothesis-driven exploration, efficient exploitation of acquired knowledge, and can successfully be prompted with first-person demonstrations. Adaptation emerges from three ingredients: (1) meta-reinforcement learning across a vast, smooth and diverse task distribution, (2) a policy parameterised as a large-scale attention-based memory architecture, and (3) an effective automated curriculum that prioritises tasks at the frontier of an agent's capabilities. We demonstrate characteristic scaling laws with respect to network size, memory length, and richness of the training task distribution. We believe our results lay the foundation for increasingly general and adaptive RL agents that perform well across ever-larger open-ended domains.
Developing, Evaluating and Scaling Learning Agents in Multi-Agent Environments
Sep 22, 2022The Game Theory & Multi-Agent team at DeepMind studies several aspects of multi-agent learning ranging from computing approximations to fundamental concepts in game theory to simulating social dilemmas in rich spatial environments and training 3-d humanoids in difficult team coordination tasks. A signature aim of our group is to use the resources and expertise made available to us at DeepMind in deep reinforcement learning to explore multi-agent systems in complex environments and use these benchmarks to advance our understanding. Here, we summarise the recent work of our team and present a taxonomy that we feel highlights many important open challenges in multi-agent research.
The Challenges of Exploration for Offline Reinforcement Learning
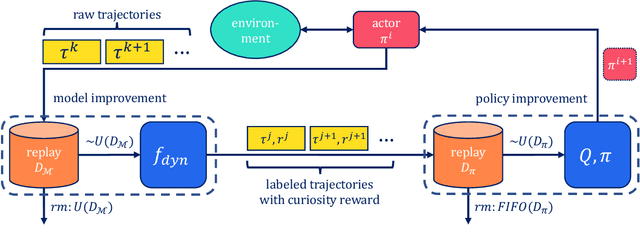
Jan 27, 2022Offline Reinforcement Learning (ORL) enablesus to separately study the two interlinked processes of reinforcement learning: collecting informative experience and inferring optimal behaviour. The second step has been widely studied in the offline setting, but just as critical to data-efficient RL is the collection of informative data. The task-agnostic setting for data collection, where the task is not known a priori, is of particular interest due to the possibility of collecting a single dataset and using it to solve several downstream tasks as they arise. We investigate this setting via curiosity-based intrinsic motivation, a family of exploration methods which encourage the agent to explore those states or transitions it has not yet learned to model. With Explore2Offline, we propose to evaluate the quality of collected data by transferring the collected data and inferring policies with reward relabelling and standard offline RL algorithms. We evaluate a wide variety of data collection strategies, including a new exploration agent, Intrinsic Model Predictive Control (IMPC), using this scheme and demonstrate their performance on various tasks. We use this decoupled framework to strengthen intuitions about exploration and the data prerequisites for effective offline RL.
Zero-Shot Uncertainty-Aware Deployment of Simulation Trained Policies on Real-World Robots
Dec 10, 2021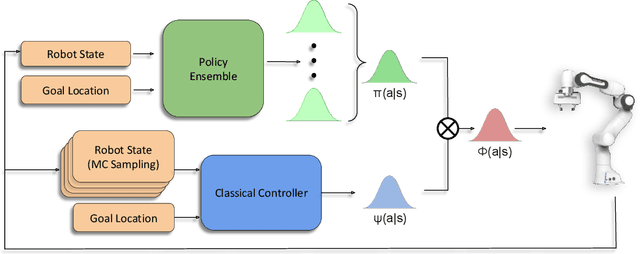
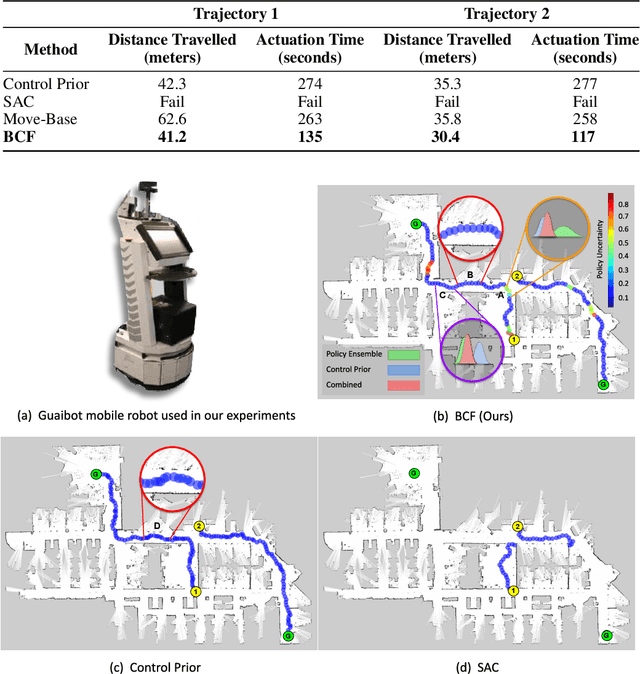
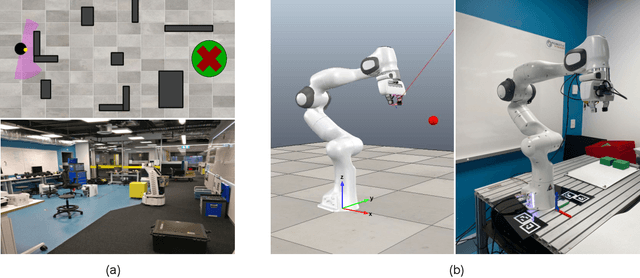

While deep reinforcement learning (RL) agents have demonstrated incredible potential in attaining dexterous behaviours for robotics, they tend to make errors when deployed in the real world due to mismatches between the training and execution environments. In contrast, the classical robotics community have developed a range of controllers that can safely operate across most states in the real world given their explicit derivation. These controllers however lack the dexterity required for complex tasks given limitations in analytical modelling and approximations. In this paper, we propose Bayesian Controller Fusion (BCF), a novel uncertainty-aware deployment strategy that combines the strengths of deep RL policies and traditional handcrafted controllers. In this framework, we can perform zero-shot sim-to-real transfer, where our uncertainty based formulation allows the robot to reliably act within out-of-distribution states by leveraging the handcrafted controller while gaining the dexterity of the learned system otherwise. We show promising results on two real-world continuous control tasks, where BCF outperforms both the standalone policy and controller, surpassing what either can achieve independently. A supplementary video demonstrating our system is provided at https://bit.ly/bcf_deploy.
Is Curiosity All You Need? On the Utility of Emergent Behaviours from Curious Exploration
Sep 17, 2021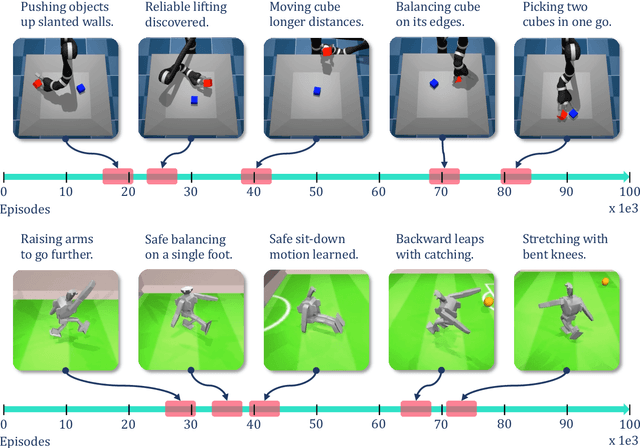


Curiosity-based reward schemes can present powerful exploration mechanisms which facilitate the discovery of solutions for complex, sparse or long-horizon tasks. However, as the agent learns to reach previously unexplored spaces and the objective adapts to reward new areas, many behaviours emerge only to disappear due to being overwritten by the constantly shifting objective. We argue that merely using curiosity for fast environment exploration or as a bonus reward for a specific task does not harness the full potential of this technique and misses useful skills. Instead, we propose to shift the focus towards retaining the behaviours which emerge during curiosity-based learning. We posit that these self-discovered behaviours serve as valuable skills in an agent's repertoire to solve related tasks. Our experiments demonstrate the continuous shift in behaviour throughout training and the benefits of a simple policy snapshot method to reuse discovered behaviour for transfer tasks.
Bayesian Controller Fusion: Leveraging Control Priors in Deep Reinforcement Learning for Robotics
Jul 22, 2021

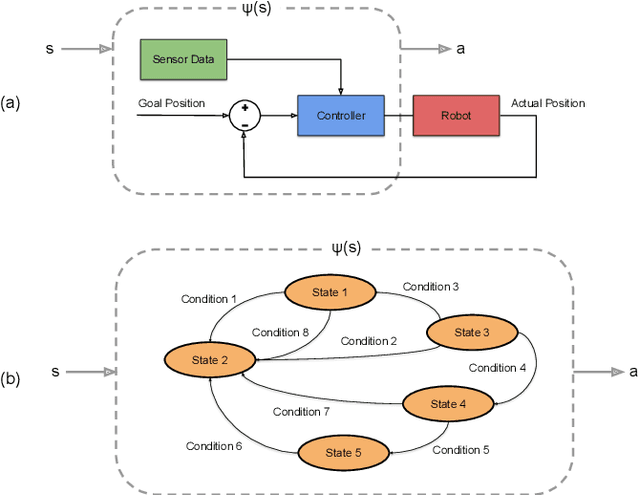
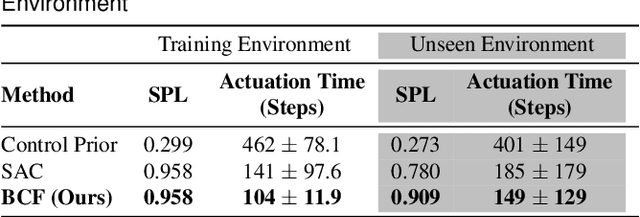
We present Bayesian Controller Fusion (BCF): a hybrid control strategy that combines the strengths of traditional hand-crafted controllers and model-free deep reinforcement learning (RL). BCF thrives in the robotics domain, where reliable but suboptimal control priors exist for many tasks, but RL from scratch remains unsafe and data-inefficient. By fusing uncertainty-aware distributional outputs from each system, BCF arbitrates control between them, exploiting their respective strengths. We study BCF on two real-world robotics tasks involving navigation in a vast and long-horizon environment, and a complex reaching task that involves manipulability maximisation. For both these domains, there exist simple handcrafted controllers that can solve the task at hand in a risk-averse manner but do not necessarily exhibit the optimal solution given limitations in analytical modelling, controller miscalibration and task variation. As exploration is naturally guided by the prior in the early stages of training, BCF accelerates learning, while substantially improving beyond the performance of the control prior, as the policy gains more experience. More importantly, given the risk-aversity of the control prior, BCF ensures safe exploration and deployment, where the control prior naturally dominates the action distribution in states unknown to the policy. We additionally show BCF's applicability to the zero-shot sim-to-real setting and its ability to deal with out-of-distribution states in the real-world. BCF is a promising approach for combining the complementary strengths of deep RL and traditional robotic control, surpassing what either can achieve independently. The code and supplementary video material are made publicly available at https://krishanrana.github.io/bcf.
Learning Arbitrary-Goal Fabric Folding with One Hour of Real Robot Experience
Oct 07, 2020

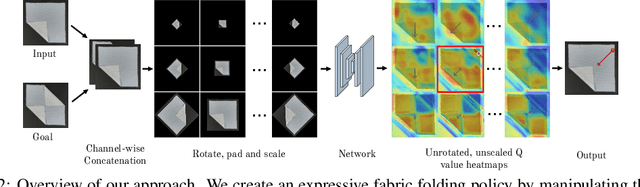
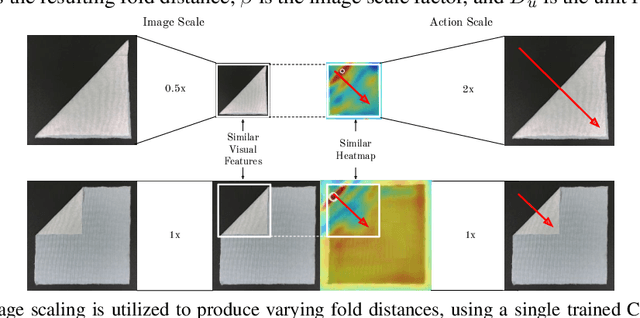
Manipulating deformable objects, such as fabric, is a long standing problem in robotics, with state estimation and control posing a significant challenge for traditional methods. In this paper, we show that it is possible to learn fabric folding skills in only an hour of self-supervised real robot experience, without human supervision or simulation. Our approach relies on fully convolutional networks and the manipulation of visual inputs to exploit learned features, allowing us to create an expressive goal-conditioned pick and place policy that can be trained efficiently with real world robot data only. Folding skills are learned with only a sparse reward function and thus do not require reward function engineering, merely an image of the goal configuration. We demonstrate our method on a set of towel-folding tasks, and show that our approach is able to discover sequential folding strategies, purely from trial-and-error. We achieve state-of-the-art results without the need for demonstrations or simulation, used in prior approaches. Videos available at: https://sites.google.com/view/learningtofold
Multiplicative Controller Fusion: A Hybrid Navigation Strategy For Deployment in Unknown Environments
Mar 13, 2020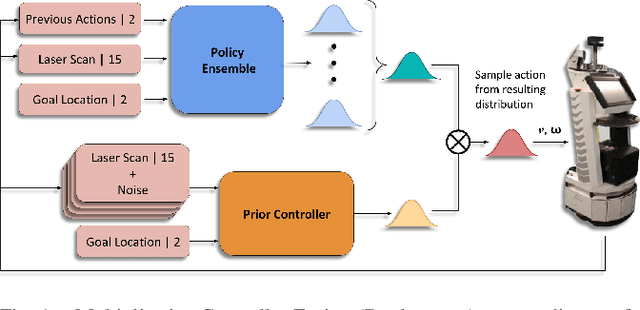
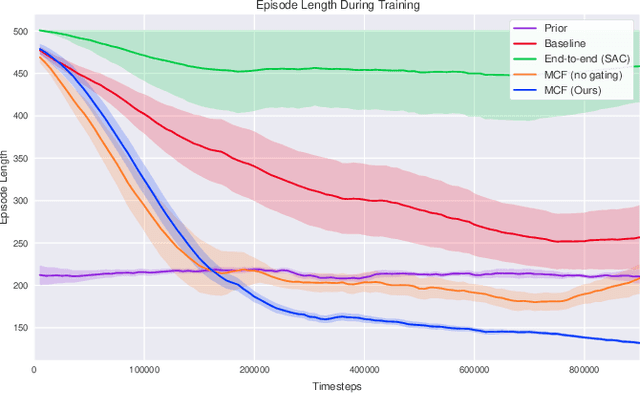
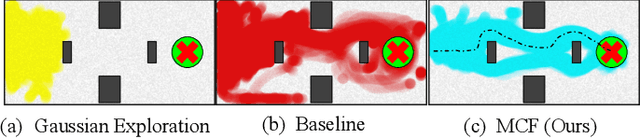
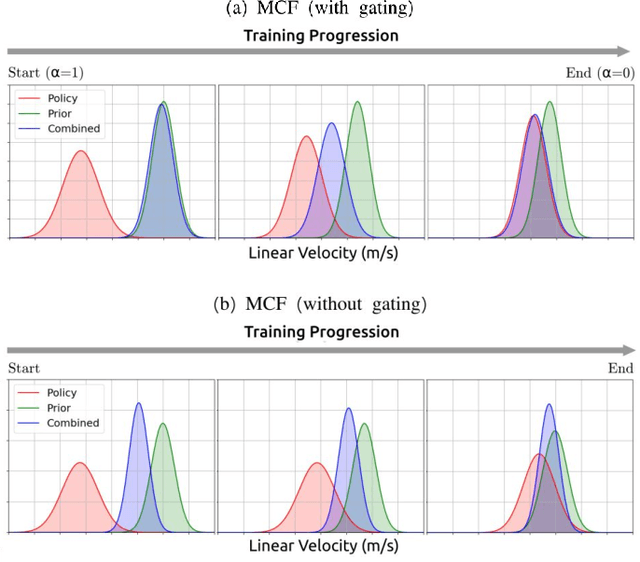
Learning-based approaches often outperform hand-coded algorithmic solutions for many problems in robotics. However, learning long-horizon tasks on real robot hardware can be intractable, and transferring a learned policy from simulation to reality is still extremely challenging. We present a novel approach to model-free reinforcement learning that can leverage existing sub-optimal solutions as an algorithmic prior during training and deployment. During training, our gated fusion approach enables the prior to guide the initial stages of exploration, increasing sample-efficiency and enabling learning from sparse long-horizon reward signals. Importantly, the policy can learn to improve beyond the performance of the sub-optimal prior since the prior's influence is annealed gradually. During deployment, the policy's uncertainty provides a reliable strategy for transferring a simulation-trained policy to the real world by falling back to the prior controller in uncertain states. We show the efficacy of our Multiplicative Controller Fusion approach on the task of robot navigation and demonstrate safe transfer from simulation to the real world without any fine tuning. The code for this project is made publicly available at https://sites.google.com/view/mcf-nav/home.
Evaluating task-agnostic exploration for fixed-batch learning of arbitrary future tasks
Nov 20, 2019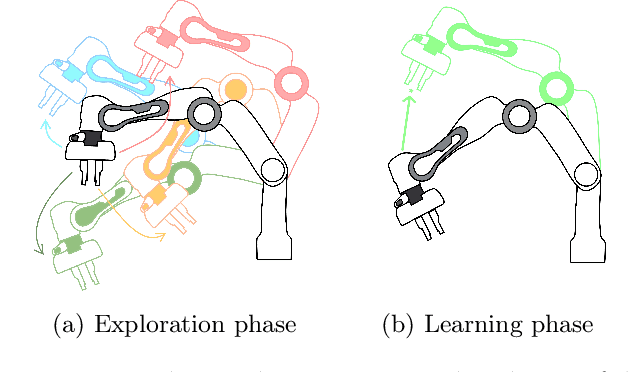
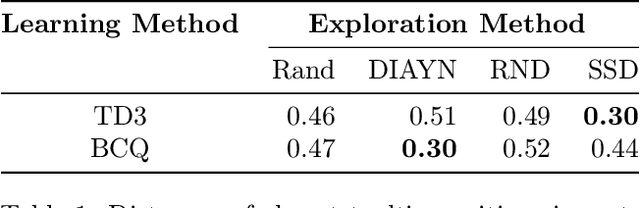

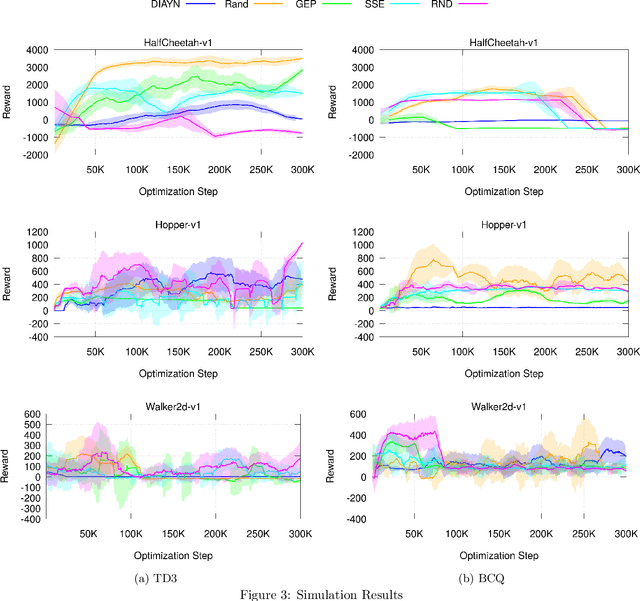
Deep reinforcement learning has been shown to solve challenging tasks where large amounts of training experience is available, usually obtained online while learning the task. Robotics is a significant potential application domain for many of these algorithms, but generating robot experience in the real world is expensive, especially when each task requires a lengthy online training procedure. Off-policy algorithms can in principle learn arbitrary tasks from a diverse enough fixed dataset. In this work, we evaluate popular exploration methods by generating robotics datasets for the purpose of learning to solve tasks completely offline without any further interaction in the real world. We present results on three popular continuous control tasks in simulation, as well as continuous control of a high-dimensional real robot arm. Code documenting all algorithms, experiments, and hyper-parameters is available at https://github.com/qutrobotlearning/batchlearning.