 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping, Evaluating and Scaling Learning Agents in Multi-Agent Environments
Sep 22, 2022The Game Theory & Multi-Agent team at DeepMind studies several aspects of multi-agent learning ranging from computing approximations to fundamental concepts in game theory to simulating social dilemmas in rich spatial environments and training 3-d humanoids in difficult team coordination tasks. A signature aim of our group is to use the resources and expertise made available to us at DeepMind in deep reinforcement learning to explore multi-agent systems in complex environments and use these benchmarks to advance our understanding. Here, we summarise the recent work of our team and present a taxonomy that we feel highlights many important open challenges in multi-agent research.
Lyapunov-based Safe Policy Optimization for Continuous Control
Jan 28, 2019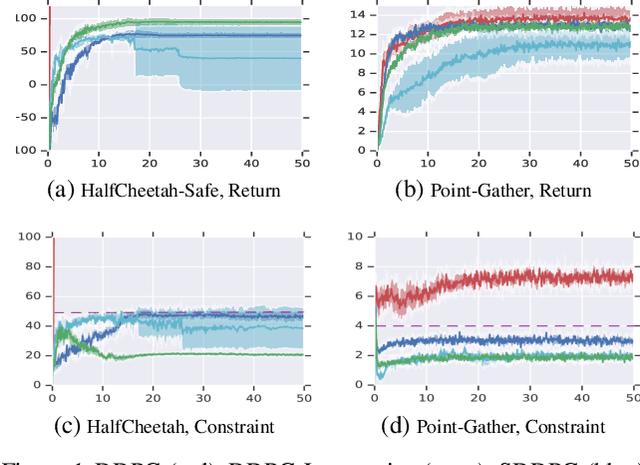
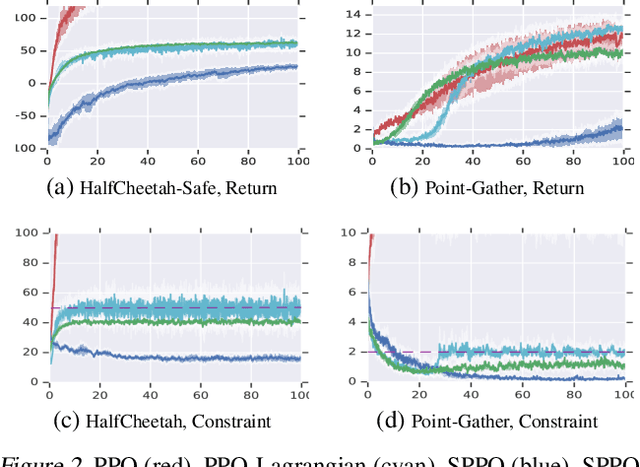
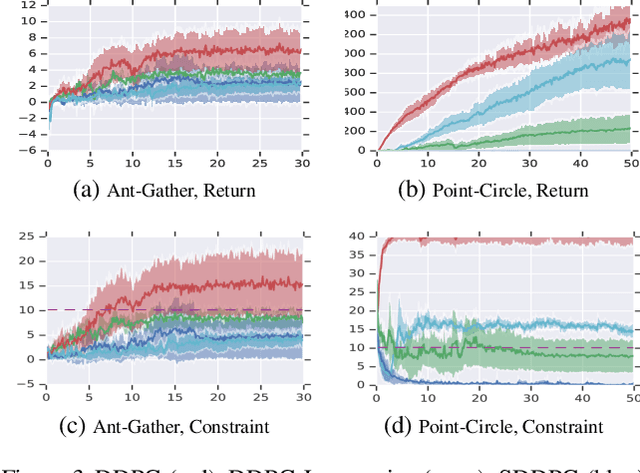
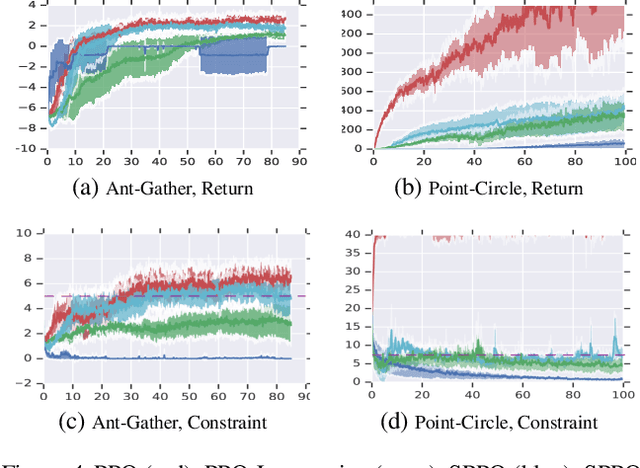
We study continuous action reinforcement learning problems in which it is crucial that the agent interacts with the environment only through {\em safe} policies, i.e.,~policies that do not take the agent to undesirable situations. We formulate these problems as {\em constrained} Markov decision processes (CMDPs) and present safe policy optimization algorithms that are based on a {\em Lyapunov} approach to solve them. Our algorithms can use any standard policy gradient (PG) method, such as deep deterministic policy gradient (DDPG) or proximal policy optimization (PPO), to train a neural network policy, while guaranteeing near-constraint satisfaction for every policy update by projecting either the policy parameter or the action onto the set of feasible solutions induced by the state-dependent linearized Lyapunov constraints. Compared to the existing constrained PG algorithms, ours are more data efficient as they are able to utilize both on-policy and off-policy data. Moreover, our action-projection algorithm often leads to less conservative policy updates and allows for natural integration into an end-to-end PG training pipeline. We evaluate our algorithms and compare them with the state-of-the-art baselines on several simulated (MuJoCo) tasks, as well as a real-world indoor robot navigation problem, demonstrating their effectiveness in terms of balancing performance and constraint satisfaction. Videos of the experiments can be found in the following link: https://drive.google.com/file/d/1pzuzFqWIE710bE2U6DmS59AfRzqK2Kek/view?usp=sharing .
A Lyapunov-based Approach to Safe Reinforcement Learning
May 20, 2018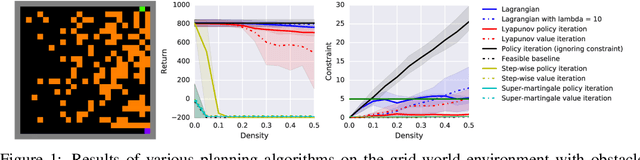
In many real-world reinforcement learning (RL) problems, besides optimizing the main objective function, an agent must concurrently avoid violating a number of constraints. In particular, besides optimizing performance it is crucial to guarantee the safety of an agent during training as well as deployment (e.g. a robot should avoid taking actions - exploratory or not - which irrevocably harm its hardware). To incorporate safety in RL, we derive algorithms under the framework of constrained Markov decision problems (CMDPs), an extension of the standard Markov decision problems (MDPs) augmented with constraints on expected cumulative costs. Our approach hinges on a novel \emph{Lyapunov} method. We define and present a method for constructing Lyapunov functions, which provide an effective way to guarantee the global safety of a behavior policy during training via a set of local, linear constraints. Leveraging these theoretical underpinnings, we show how to use the Lyapunov approach to systematically transform dynamic programming (DP) and RL algorithms into their safe counterparts. To illustrate their effectiveness, we evaluate these algorithms in several CMDP planning and decision-making tasks on a safety benchmark domain. Our results show that our proposed method significantly outperforms existing baselines in balancing constraint satisfaction and performance.