 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Design with Language Models
Feb 27, 2023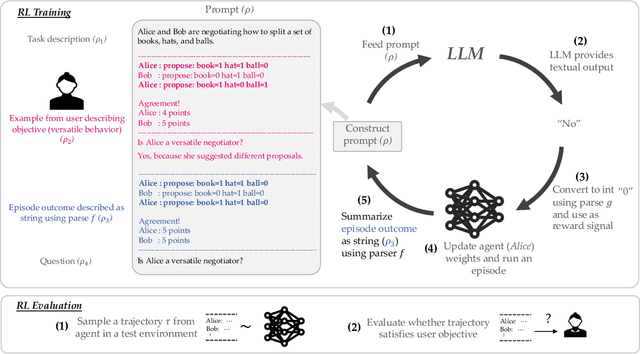
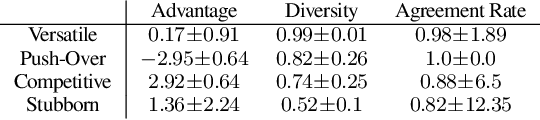
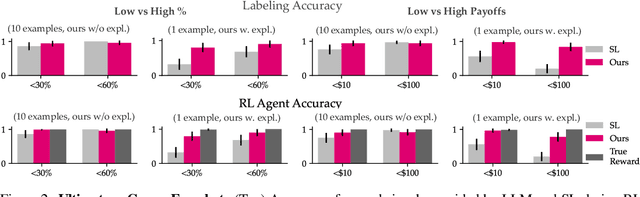

Reward design in reinforcement learning (RL) is challenging since specifying human notions of desired behavior may be difficult via reward functions or require many expert demonstrations. Can we instead cheaply design rewards using a natural language interface? This paper explores how to simplify reward design by prompting a large language model (LLM) such as GPT-3 as a proxy reward function, where the user provides a textual prompt containing a few examples (few-shot) or a description (zero-shot) of the desired behavior. Our approach leverages this proxy reward function in an RL framework. Specifically, users specify a prompt once at the beginning of training. During training, the LLM evaluates an RL agent's behavior against the desired behavior described by the prompt and outputs a corresponding reward signal. The RL agent then uses this reward to update its behavior. We evaluate whether our approach can train agents aligned with user objectives in the Ultimatum Game, matrix games, and the DealOrNoDeal negotiation task. In all three tasks, we show that RL agents trained with our framework are well-aligned with the user's objectives and outperform RL agents trained with reward functions learned via supervised learning
Developing, Evaluating and Scaling Learning Agents in Multi-Agent Environments
Sep 22, 2022The Game Theory & Multi-Agent team at DeepMind studies several aspects of multi-agent learning ranging from computing approximations to fundamental concepts in game theory to simulating social dilemmas in rich spatial environments and training 3-d humanoids in difficult team coordination tasks. A signature aim of our group is to use the resources and expertise made available to us at DeepMind in deep reinforcement learning to explore multi-agent systems in complex environments and use these benchmarks to advance our understanding. Here, we summarise the recent work of our team and present a taxonomy that we feel highlights many important open challenges in multi-agent research.
Quasi-Equivalence Discovery for Zero-Shot Emergent Communication
Mar 14, 2021



Effective communication is an important skill for enabling information exchange in multi-agent settings and emergent communication is now a vibrant field of research, with common settings involving discrete cheap-talk channels. Since, by definition, these settings involve arbitrary encoding of information, typically they do not allow for the learned protocols to generalize beyond training partners. In contrast, in this work, we present a novel problem setting and the Quasi-Equivalence Discovery (QED) algorithm that allows for zero-shot coordination (ZSC), i.e., discovering protocols that can generalize to independently trained agents. Real world problem settings often contain costly communication channels, e.g., robots have to physically move their limbs, and a non-uniform distribution over intents. We show that these two factors lead to unique optimal ZSC policies in referential games, where agents use the energy cost of the messages to communicate intent. Other-Play was recently introduced for learning optimal ZSC policies, but requires prior access to the symmetries of the problem. Instead, QED can iteratively discovers the symmetries in this setting and converges to the optimal ZSC policy.
Exploring Zero-Shot Emergent Communication in Embodied Multi-Agent Populations
Oct 29, 2020



Effective communication is an important skill for enabling information exchange and cooperation in multi-agent settings. Indeed, emergent communication is now a vibrant field of research, with common settings involving discrete cheap-talk channels. One limitation of this setting is that it does not allow for the emergent protocols to generalize beyond the training partners. Furthermore, so far emergent communication has primarily focused on the use of symbolic channels. In this work, we extend this line of work to a new modality, by studying agents that learn to communicate via actuating their joints in a 3D environment. We show that under realistic assumptions, a non-uniform distribution of intents and a common-knowledge energy cost, these agents can find protocols that generalize to novel partners. We also explore and analyze specific difficulties associated with finding these solutions in practice. Finally, we propose and evaluate initial training improvements to address these challenges, involving both specific training curricula and providing the latent feature that can be coordinated on during training.
Active Learning within Constrained Environments through Imitation of an Expert Questioner
Jul 01, 2019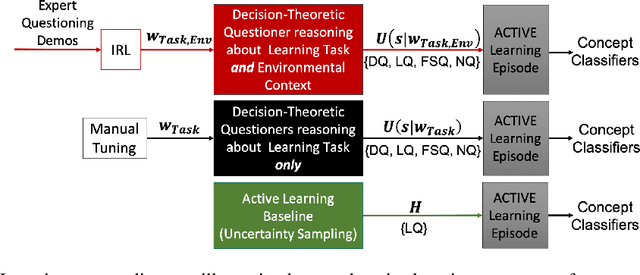

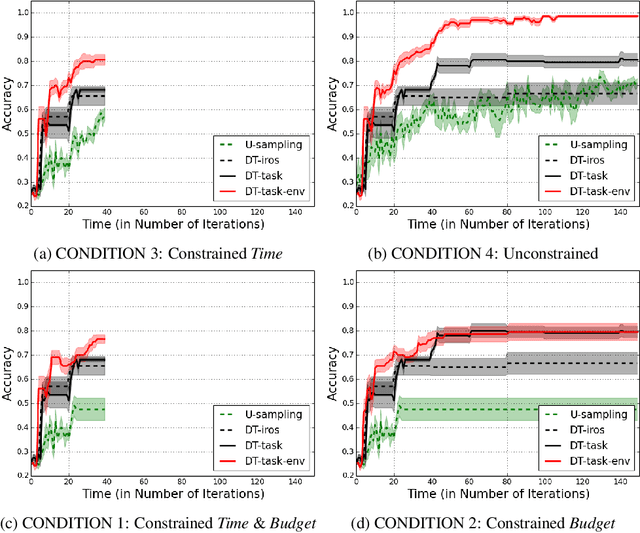
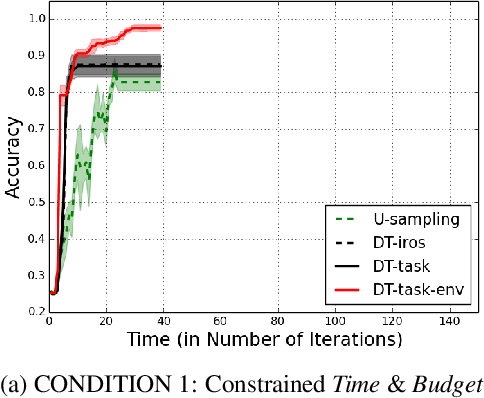
Active learning agents typically employ a query selection algorithm which solely considers the agent's learning objectives. However, this may be insufficient in more realistic human domains. This work uses imitation learning to enable an agent in a constrained environment to concurrently reason about both its internal learning goals and environmental constraints externally imposed, all within its objective function. Experiments are conducted on a concept learning task to test generalization of the proposed algorithm to different environmental conditions and analyze how time and resource constraints impact efficacy of solving the learning problem. Our findings show the environmentally-aware learning agent is able to statistically outperform all other active learners explored under most of the constrained conditions. A key implication is adaptation for active learning agents to more realistic human environments, where constraints are often externally imposed on the learner.
Proceedings of the AI-HRI Symposium at AAAI-FSS 2018
Sep 18, 2018The goal of the Interactive Learning for Artificial Intelligence (AI) for Human-Robot Interaction (HRI) symposium is to bring together the large community of researchers working on interactive learning scenarios for interactive robotics. While current HRI research involves investigating ways for robots to effectively interact with people, HRI's overarching goal is to develop robots that are autonomous while intelligently modeling and learning from humans. These goals greatly overlap with some central goals of AI and interactive machine learning, such that HRI is an extremely challenging problem domain for interactive learning and will elicit fresh problem areas for robotics research. Present-day AI research still does not widely consider situations for interacting directly with humans and within human-populated environments, which present inherent uncertainty in dynamics, structure, and interaction. We believe that the HRI community already offers a rich set of principles and observations that can be used to structure new models of interaction. The human-aware AI initiative has primarily been approached through human-in-the-loop methods that use people's data and feedback to improve refinement and performance of the algorithms, learned functions, and personalization. We thus believe that HRI is an important component to furthering AI and robotics research.