 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Arbitrary-Goal Fabric Folding with One Hour of Real Robot Experience
Paper and Code
Oct 07, 2020

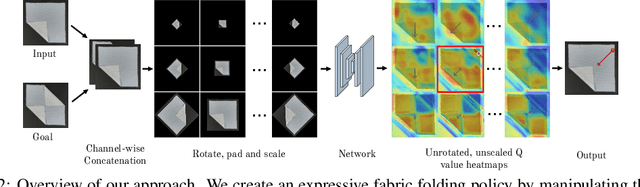
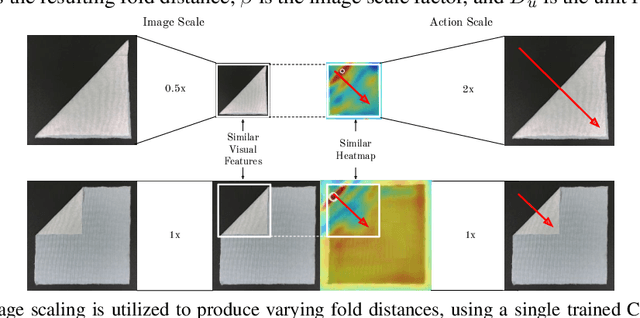
Manipulating deformable objects, such as fabric, is a long standing problem in robotics, with state estimation and control posing a significant challenge for traditional methods. In this paper, we show that it is possible to learn fabric folding skills in only an hour of self-supervised real robot experience, without human supervision or simulation. Our approach relies on fully convolutional networks and the manipulation of visual inputs to exploit learned features, allowing us to create an expressive goal-conditioned pick and place policy that can be trained efficiently with real world robot data only. Folding skills are learned with only a sparse reward function and thus do not require reward function engineering, merely an image of the goal configuration. We demonstrate our method on a set of towel-folding tasks, and show that our approach is able to discover sequential folding strategies, purely from trial-and-error. We achieve state-of-the-art results without the need for demonstrations or simulation, used in prior approaches. Videos available at: https://sites.google.com/view/learningtofold