 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Deep Reinforcement Learning for a Distributed and Adaptive Locomotion Controller of a Hexapod Robot
May 21, 2020
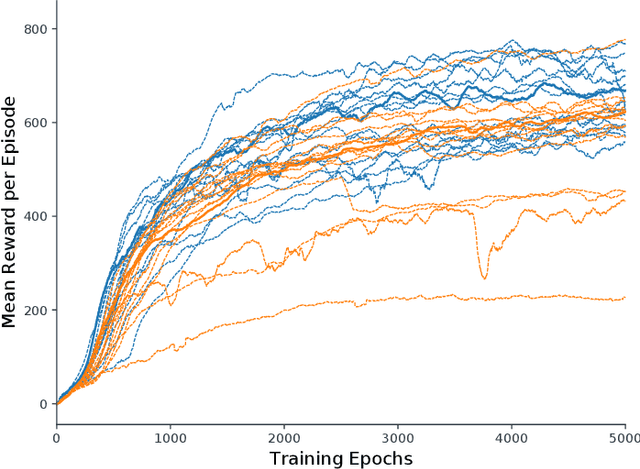
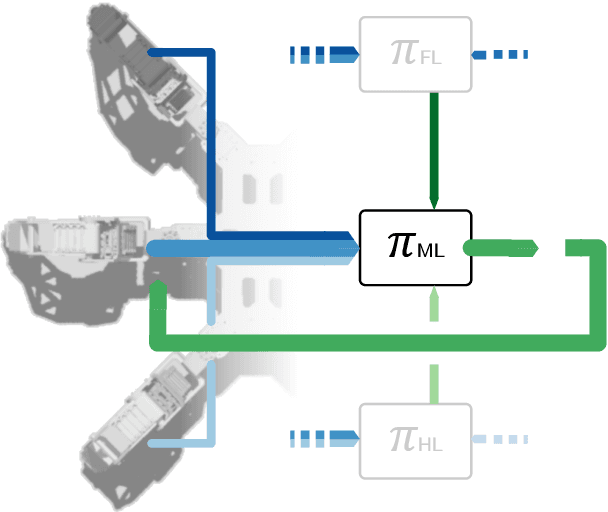
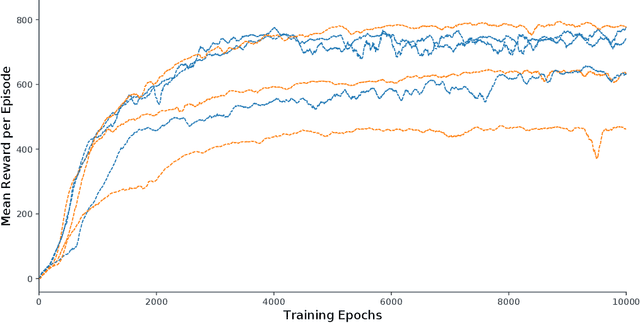
Locomotion is a prime example for adaptive behavior in animals and biological control principles have inspired control architectures for legged robots. While machine learning has been successfully applied to many tasks in recent years, Deep Reinforcement Learning approaches still appear to struggle when applied to real world robots in continuous control tasks and in particular do not appear as robust solutions that can handle uncertainties well. Therefore, there is a new interest in incorporating biological principles into such learning architectures. While inducing a hierarchical organization as found in motor control has shown already some success, we here propose a decentralized organization as found in insect motor control for coordination of different legs. A decentralized and distributed architecture is introduced on a simulated hexapod robot and the details of the controller are learned through Deep Reinforcement Learning. We first show that such a concurrent local structure is able to learn better walking behavior. Secondly, that the simpler organization is learned faster compared to holistic approaches.
A Perceived Environment Design using a Multi-Modal Variational Autoencoder for learning Active-Sensing
Nov 01, 2019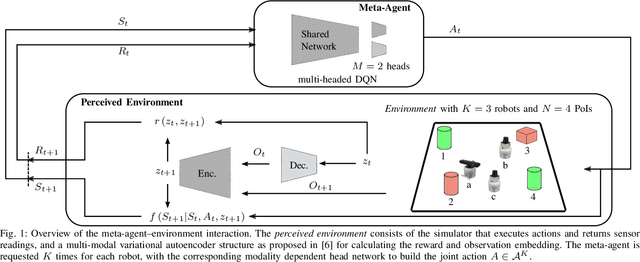
This contribution comprises the interplay between a multi-modal variational autoencoder and an environment to a perceived environment, on which an agent can act. Furthermore, we conclude our work with a comparison to curiosity-driven learning.
M$^2$VAE - Derivation of a Multi-Modal Variational Autoencoder Objective from the Marginal Joint Log-Likelihood
Mar 18, 2019

This work gives an in-depth derivation of the trainable evidence lower bound obtained from the marginal joint log-Likelihood with the goal of training a Multi-Modal Variational Autoencoder (M$^2$VAE).
Coordinated Heterogeneous Distributed Perception based on Latent Space Representation
Sep 12, 2018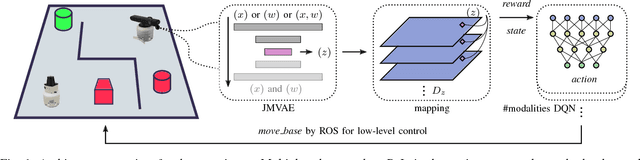
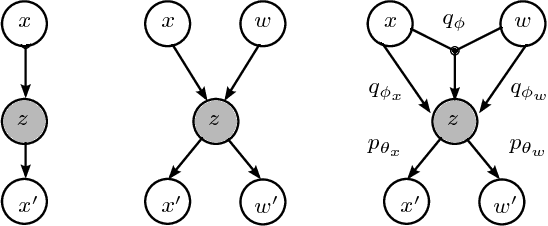
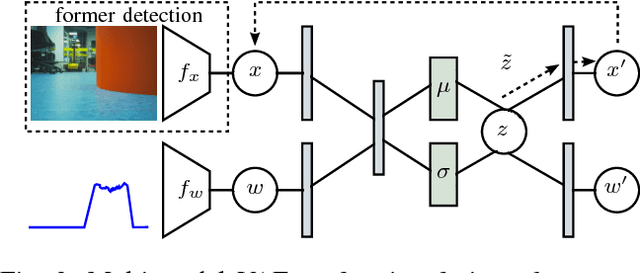
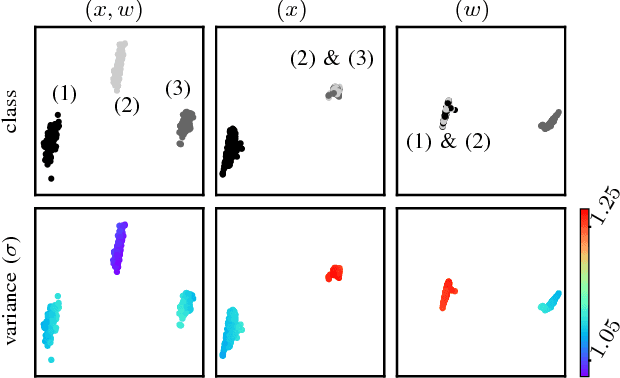
We investigate a reinforcement approach for distributed sensing based on the latent space derived from multi-modal deep generative models. Our contribution provides insights to the following benefits: Detections can be exchanged effectively between robots equipped with uni-modal sensors due to a shared latent representation of information that is trained by a Variational Auto Encoder (VAE). Sensor-fusion can be applied asynchronously due to the generative feature of the VAE. Deep Q-Networks (DQNs) are trained to minimize uncertainty in latent space by coordinating robots to a Point-of-Interest (PoI) where their sensor modality can provide beneficial information about the PoI. Additionally, we show that the decrease in uncertainty can be defined as the direct reward signal for training the DQN.
Towards Inverse Sensor Mapping in Agriculture
May 22, 2018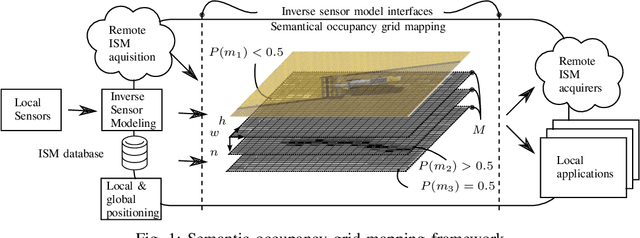


In recent years, the drive of the Industry 4.0 initiative has enriched industrial and scientific approaches to build self-driving cars or smart factories. Agricultural applications benefit from both advances, as they are in reality mobile driving factories which process the environment. Therefore, acurate perception of the surrounding is a crucial task as it involves the goods to be processed, in contrast to standard indoor production lines. Environmental processing requires accurate and robust quantification in order to correctly adjust processing parameters and detect hazardous risks during the processing. While today approaches still implement functional elements based on a single particular set of sensors, it may become apparent that a unified representation of the environment compiled from all available information sources would be more versatile, sufficient, and cost effective. The key to this approach is the means of developing a common information language from the data provided. In this paper, we introduce and discuss techniques to build so called inverse sensor models that create a common information language among different, but typically agricultural, information providers. These can be current live sensor data, farm management systems, or long term information generated from previous processing, drones, or satellites. In the context of Industry 4.0, this enables the interoperability of different agricultural systems and allows information transparency.
Path Evaluation via HMM on Semantical Occupancy Grid Maps
May 22, 2018



Traditional approaches to mapping of environments in robotics make use of spatially discretized representations, such as occupancy grid maps. Modern systems, e.g. in agriculture or automotive applications, are equipped with a variety of different sensors to gather diverse process-relevant modalities from the environment. The amount of data and its associated semantic information demand for broader data structures and frameworks, like semantical occupancy grid maps (SOGMs). This multi-modal representation also calls for novel methods of path planning. Due to the sequential nature of path planning as a consecutive execution of tasks and their ability to handle multi-modal data as provided by SOGMs, Markovian models, such as Hidden Markov Models (HMM) or Partially Observable Markov Decision Processes, are applicable. Furthermore, for these techniques to be applied effectively and efficiently, data from SOGMs must be extracted and refined. Superpixel algorithms, originating from computer vision, provide a method to de-noise and re-express SOGMs in an alternative representation. This publication explores and extends the use of superpixel segmentation as a post-processing step and applies Markovian models for path decoding on SOGMs.