 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinated Heterogeneous Distributed Perception based on Latent Space Representation
Paper and Code
Sep 12, 2018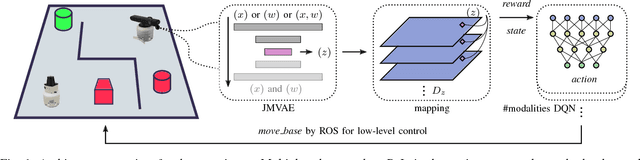
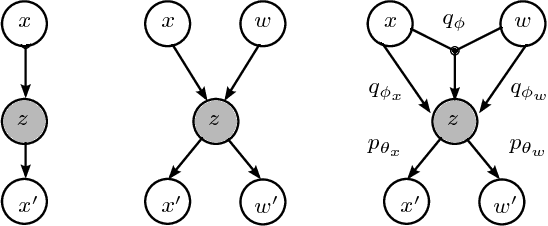
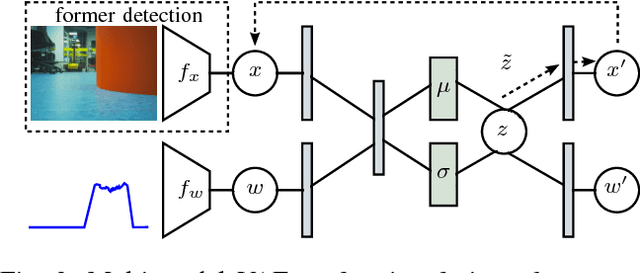
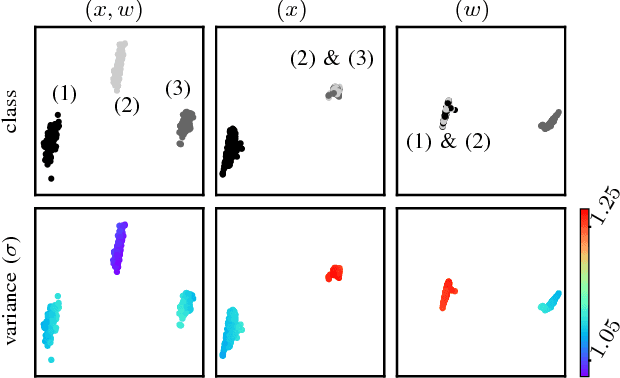
We investigate a reinforcement approach for distributed sensing based on the latent space derived from multi-modal deep generative models. Our contribution provides insights to the following benefits: Detections can be exchanged effectively between robots equipped with uni-modal sensors due to a shared latent representation of information that is trained by a Variational Auto Encoder (VAE). Sensor-fusion can be applied asynchronously due to the generative feature of the VAE. Deep Q-Networks (DQNs) are trained to minimize uncertainty in latent space by coordinating robots to a Point-of-Interest (PoI) where their sensor modality can provide beneficial information about the PoI. Additionally, we show that the decrease in uncertainty can be defined as the direct reward signal for training the DQN.