 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Spiking-Convolutional Neural Network Approach for Advancing Machine Learning Models
Jul 11, 2024In this article, we propose a novel standalone hybrid Spiking-Convolutional Neural Network (SC-NN) model and test on using image inpainting tasks. Our approach uses the unique capabilities of SNNs, such as event-based computation and temporal processing, along with the strong representation learning abilities of CNNs, to generate high-quality inpainted images. The model is trained on a custom dataset specifically designed for image inpainting, where missing regions are created using masks. The hybrid model consists of SNNConv2d layers and traditional CNN layers. The SNNConv2d layers implement the leaky integrate-and-fire (LIF) neuron model, capturing spiking behavior, while the CNN layers capture spatial features. In this study, a mean squared error (MSE) loss function demonstrates the training process, where a training loss value of 0.015, indicates accurate performance on the training set and the model achieved a validation loss value as low as 0.0017 on the testing set. Furthermore, extensive experimental results demonstrate state-of-the-art performance, showcasing the potential of integrating temporal dynamics and feature extraction in a single network for image inpainting.
* 7 Pages, 3 figures, and 2 tables
A Unified Approach to Entity-Centric Context Tracking in Social Conversations
Jan 28, 2022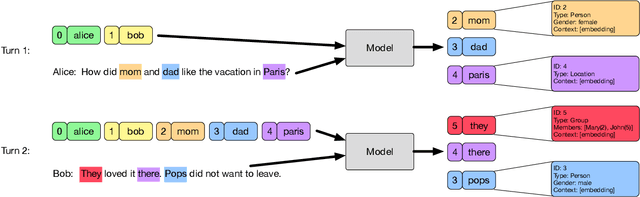
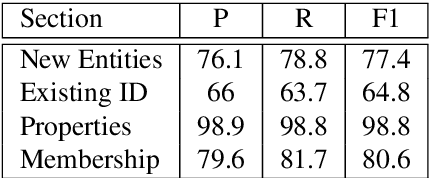
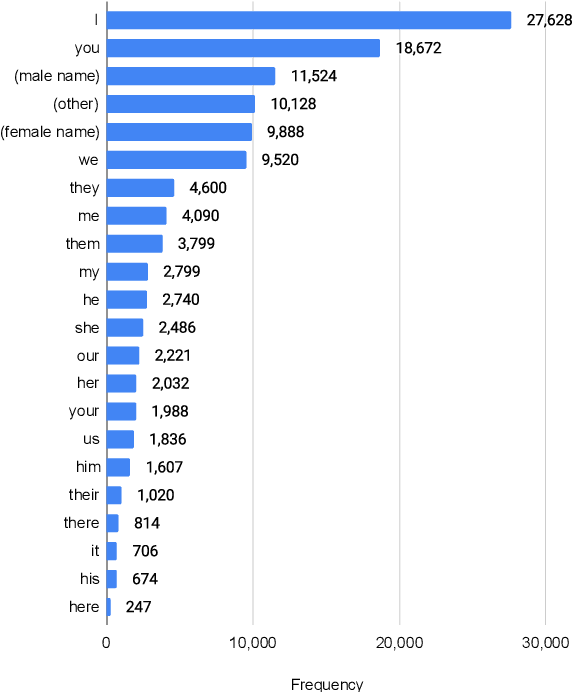
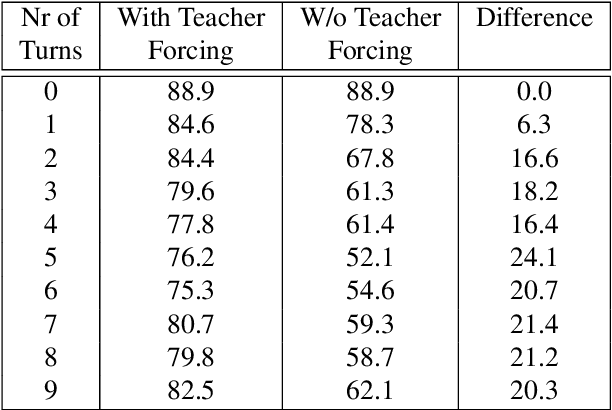
In human-human conversations, Context Tracking deals with identifying important entities and keeping track of their properties and relationships. This is a challenging problem that encompasses several subtasks such as slot tagging, coreference resolution, resolving plural mentions and entity linking. We approach this problem as an end-to-end modeling task where the conversational context is represented by an entity repository containing the entity references mentioned so far, their properties and the relationships between them. The repository is updated turn-by-turn, thus making training and inference computationally efficient even for long conversations. This paper lays the groundwork for an investigation of this framework in two ways. First, we release Contrack, a large scale human-human conversation corpus for context tracking with people and location annotations. It contains over 7000 conversations with an average of 11.8 turns, 5.8 entities and 15.2 references per conversation. Second, we open-source a neural network architecture for context tracking. Finally we compare this network to state-of-the-art approaches for the subtasks it subsumes and report results on the involved tradeoffs.
Benchmarking Deep Spiking Neural Networks on Neuromorphic Hardware
Apr 29, 2020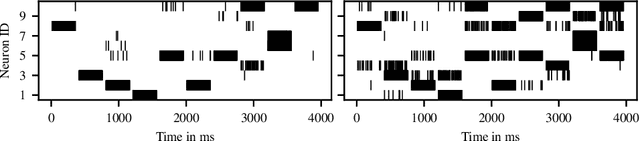
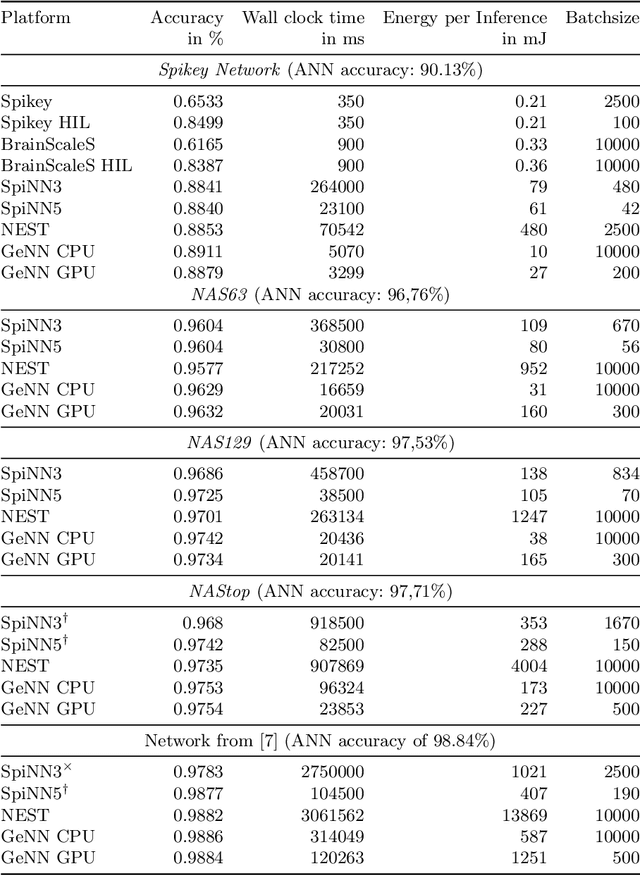
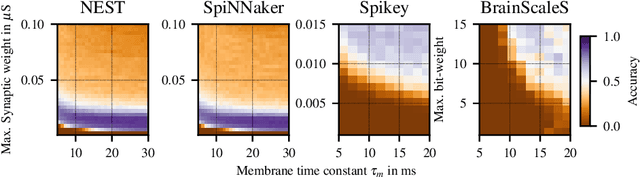
With more and more event-based neuromorphic hardware systems being developed at universities and in industry, there is a growing need for assessing their performance with domain specific measures. In this work, we use the methodology of converting pre-trained non-spiking to spiking neural networks to evaluate the performance loss and measure the energy-per-inference for three neuromorphic hardware systems (BrainScaleS, Spikey, SpiNNaker) and common simulation frameworks for CPU (NEST) and CPU/GPU (GeNN). For analog hardware we further apply a re-training technique known as hardware-in-the-loop training to cope with device mismatch. This analysis is performed for five different networks, including three networks that have been found by an automated optimization with a neural architecture search framework. We demonstrate that the conversion loss is usually below one percent for digital implementations, and moderately higher for analog systems with the benefit of much lower energy-per-inference costs.
Coordinated Heterogeneous Distributed Perception based on Latent Space Representation
Sep 12, 2018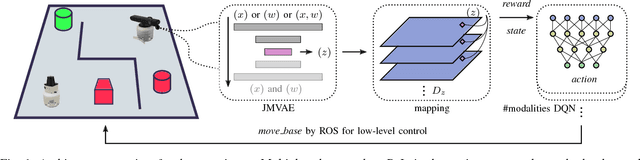
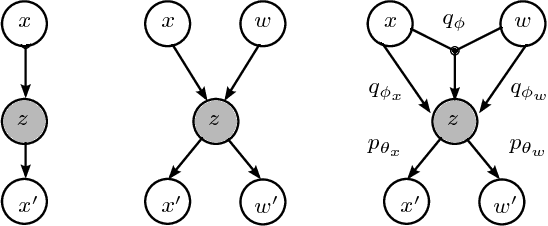
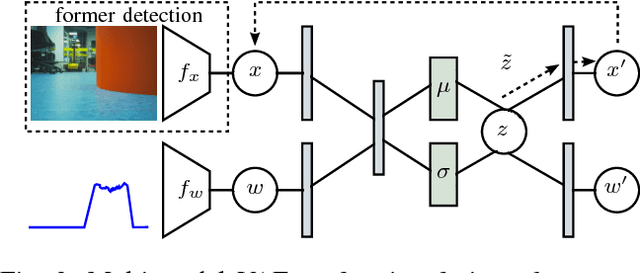
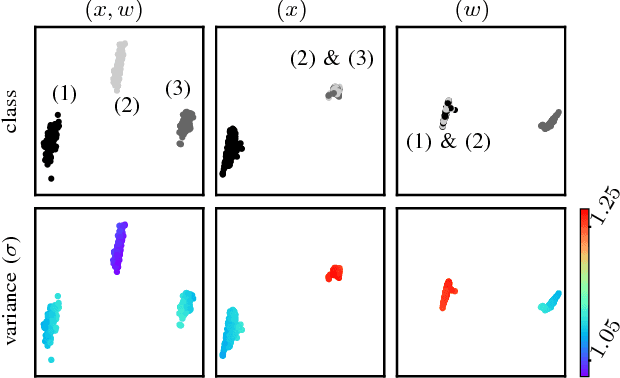
We investigate a reinforcement approach for distributed sensing based on the latent space derived from multi-modal deep generative models. Our contribution provides insights to the following benefits: Detections can be exchanged effectively between robots equipped with uni-modal sensors due to a shared latent representation of information that is trained by a Variational Auto Encoder (VAE). Sensor-fusion can be applied asynchronously due to the generative feature of the VAE. Deep Q-Networks (DQNs) are trained to minimize uncertainty in latent space by coordinating robots to a Point-of-Interest (PoI) where their sensor modality can provide beneficial information about the PoI. Additionally, we show that the decrease in uncertainty can be defined as the direct reward signal for training the DQN.
Towards Inverse Sensor Mapping in Agriculture
May 22, 2018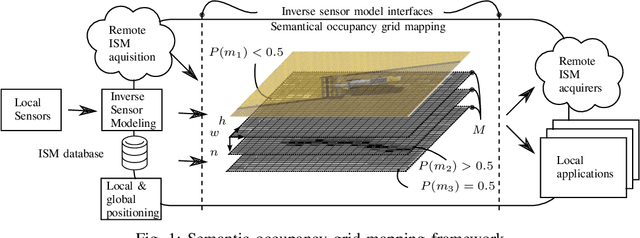
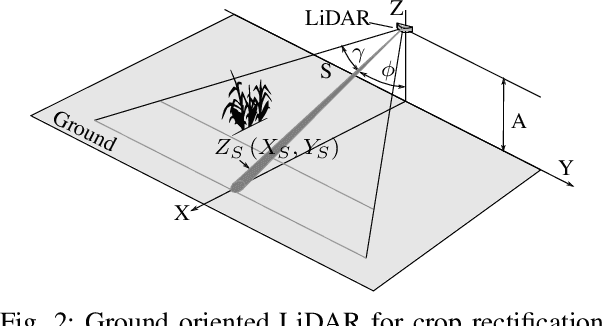


In recent years, the drive of the Industry 4.0 initiative has enriched industrial and scientific approaches to build self-driving cars or smart factories. Agricultural applications benefit from both advances, as they are in reality mobile driving factories which process the environment. Therefore, acurate perception of the surrounding is a crucial task as it involves the goods to be processed, in contrast to standard indoor production lines. Environmental processing requires accurate and robust quantification in order to correctly adjust processing parameters and detect hazardous risks during the processing. While today approaches still implement functional elements based on a single particular set of sensors, it may become apparent that a unified representation of the environment compiled from all available information sources would be more versatile, sufficient, and cost effective. The key to this approach is the means of developing a common information language from the data provided. In this paper, we introduce and discuss techniques to build so called inverse sensor models that create a common information language among different, but typically agricultural, information providers. These can be current live sensor data, farm management systems, or long term information generated from previous processing, drones, or satellites. In the context of Industry 4.0, this enables the interoperability of different agricultural systems and allows information transparency.
A Unifying View of Multiple Kernel Learning
May 04, 2010
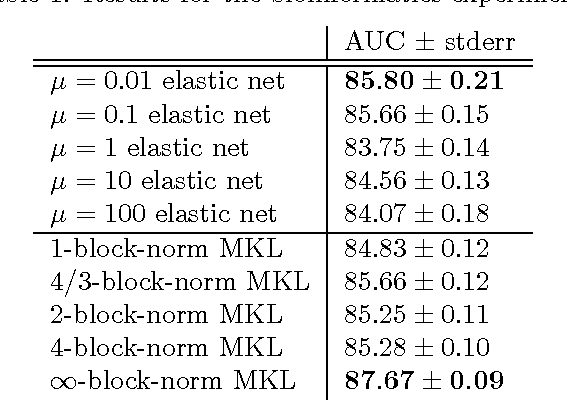
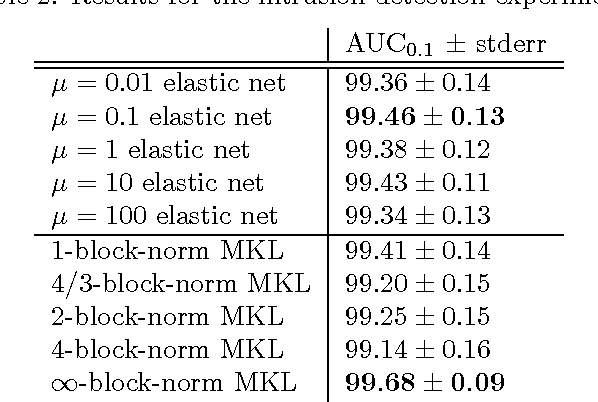
Recent research on multiple kernel learning has lead to a number of approaches for combining kernels in regularized risk minimization. The proposed approaches include different formulations of objectives and varying regularization strategies. In this paper we present a unifying general optimization criterion for multiple kernel learning and show how existing formulations are subsumed as special cases. We also derive the criterion's dual representation, which is suitable for general smooth optimization algorithms. Finally, we evaluate multiple kernel learning in this framework analytically using a Rademacher complexity bound on the generalization error and empirically in a set of experiments.