 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Approach to Entity-Centric Context Tracking in Social Conversations
Jan 28, 2022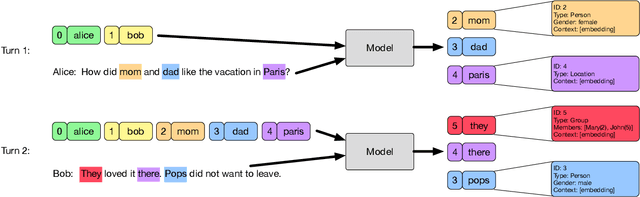
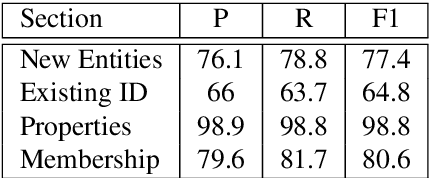
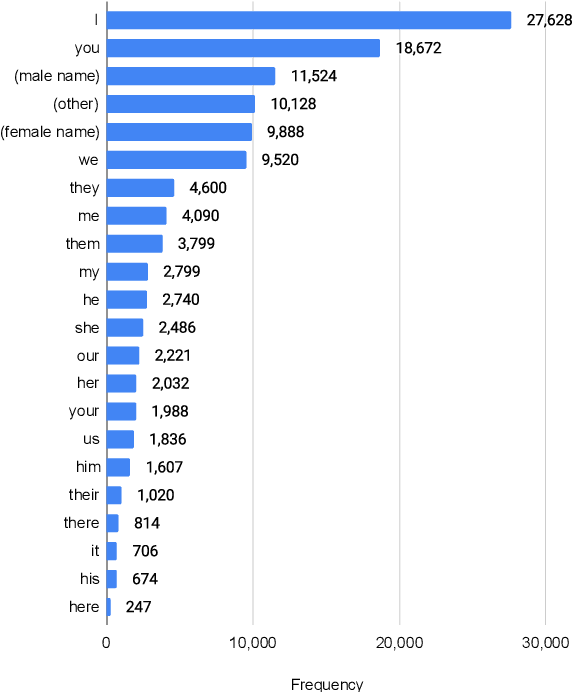
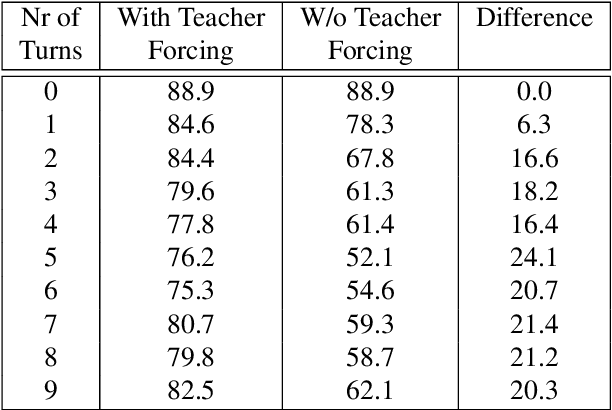
In human-human conversations, Context Tracking deals with identifying important entities and keeping track of their properties and relationships. This is a challenging problem that encompasses several subtasks such as slot tagging, coreference resolution, resolving plural mentions and entity linking. We approach this problem as an end-to-end modeling task where the conversational context is represented by an entity repository containing the entity references mentioned so far, their properties and the relationships between them. The repository is updated turn-by-turn, thus making training and inference computationally efficient even for long conversations. This paper lays the groundwork for an investigation of this framework in two ways. First, we release Contrack, a large scale human-human conversation corpus for context tracking with people and location annotations. It contains over 7000 conversations with an average of 11.8 turns, 5.8 entities and 15.2 references per conversation. Second, we open-source a neural network architecture for context tracking. Finally we compare this network to state-of-the-art approaches for the subtasks it subsumes and report results on the involved tradeoffs.
Assessing Post-Disaster Damage from Satellite Imagery using Semi-Supervised Learning Techniques
Nov 24, 2020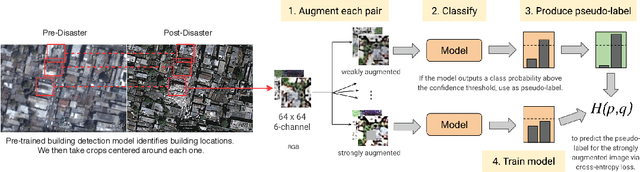
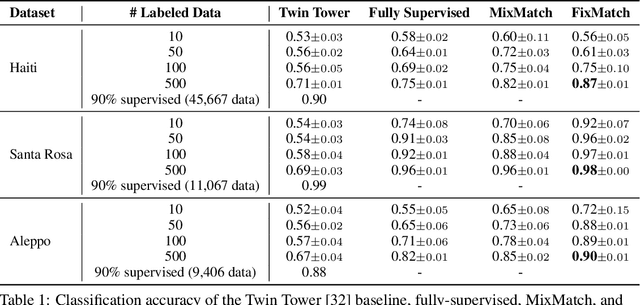
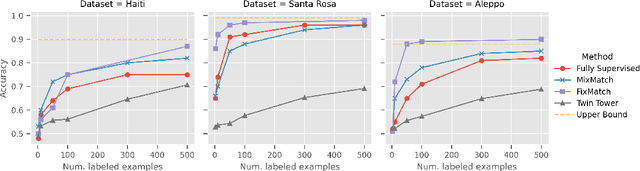
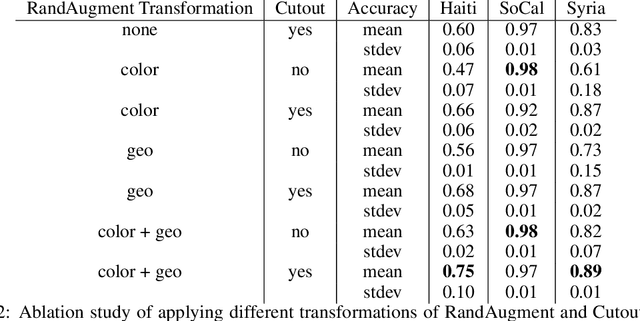
To respond to disasters such as earthquakes, wildfires, and armed conflicts, humanitarian organizations require accurate and timely data in the form of damage assessments, which indicate what buildings and population centers have been most affected. Recent research combines machine learning with remote sensing to automatically extract such information from satellite imagery, reducing manual labor and turn-around time. A major impediment to using machine learning methods in real disaster response scenarios is the difficulty of obtaining a sufficient amount of labeled data to train a model for an unfolding disaster. This paper shows a novel application of semi-supervised learning (SSL) to train models for damage assessment with a minimal amount of labeled data and large amount of unlabeled data. We compare the performance of state-of-the-art SSL methods, including MixMatch and FixMatch, to a supervised baseline for the 2010 Haiti earthquake, 2017 Santa Rosa wildfire, and 2016 armed conflict in Syria. We show how models trained with SSL methods can reach fully supervised performance despite using only a fraction of labeled data and identify areas for further improvements.
Schema-Guided Dialogue State Tracking Task at DSTC8
Feb 02, 2020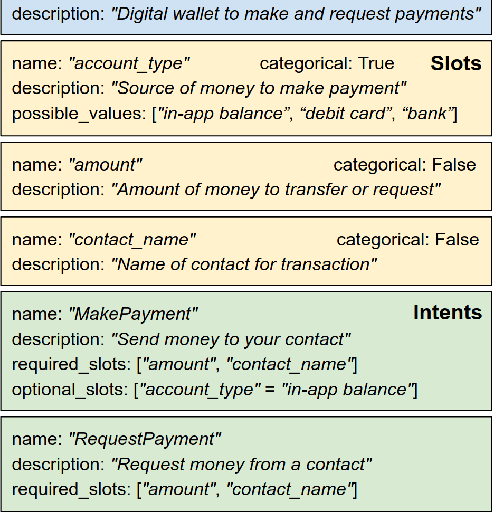



This paper gives an overview of the Schema-Guided Dialogue State Tracking task of the 8th Dialogue System Technology Challenge. The goal of this task is to develop dialogue state tracking models suitable for large-scale virtual assistants, with a focus on data-efficient joint modeling across domains and zero-shot generalization to new APIs. This task provided a new dataset consisting of over 16000 dialogues in the training set spanning 16 domains to highlight these challenges, and a baseline model capable of zero-shot generalization to new APIs. Twenty-five teams participated, developing a range of neural network models, exceeding the performance of the baseline model by a very high margin. The submissions incorporated a variety of pre-trained encoders and data augmentation techniques. This paper describes the task definition, dataset and evaluation methodology. We also summarize the approach and results of the submitted systems to highlight the overall trends in the state-of-the-art.
Building Damage Detection in Satellite Imagery Using Convolutional Neural Networks
Oct 14, 2019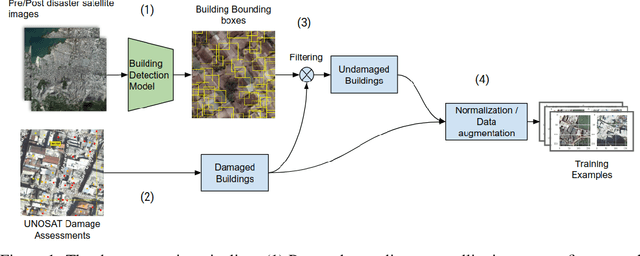

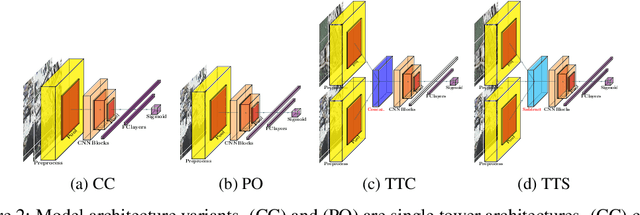
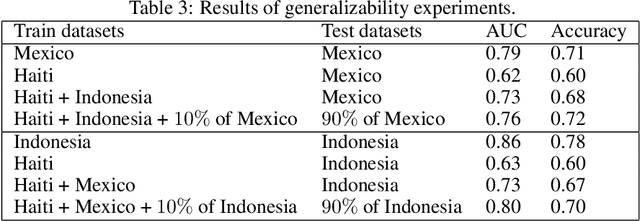
In all types of disasters, from earthquakes to armed conflicts, aid workers need accurate and timely data such as damage to buildings and population displacement to mount an effective response. Remote sensing provides this data at an unprecedented scale, but extracting operationalizable information from satellite images is slow and labor-intensive. In this work, we use machine learning to automate the detection of building damage in satellite imagery. We compare the performance of four different convolutional neural network models in detecting damaged buildings in the 2010 Haiti earthquake. We also quantify how well the models will generalize to future disasters by training and testing models on different disaster events.
Towards Scalable Multi-domain Conversational Agents: The Schema-Guided Dialogue Dataset
Sep 12, 2019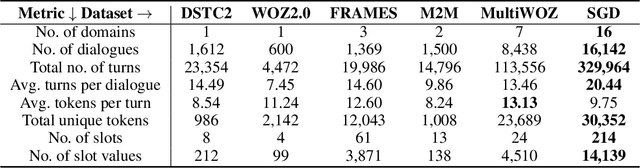
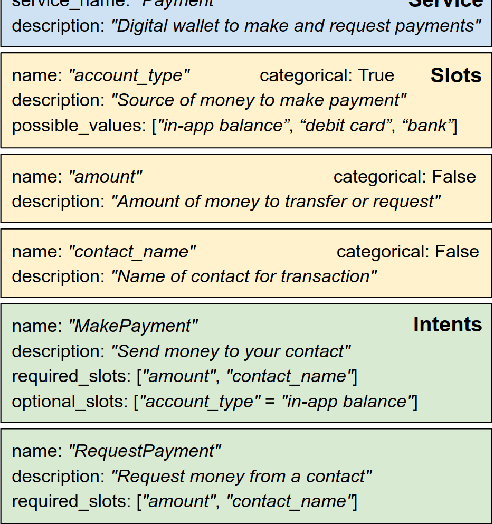
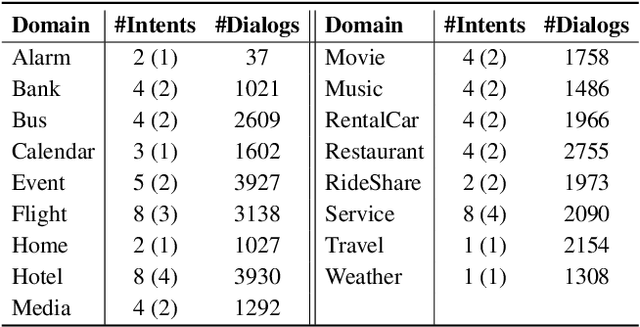
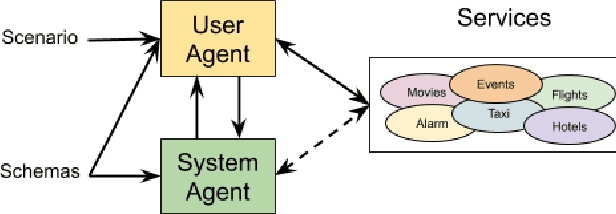
Virtual assistants such as Google Assistant, Alexa and Siri provide a conversational interface to a large number of services and APIs spanning multiple domains. Such systems need to support an ever-increasing number of services with possibly overlapping functionality. Furthermore, some of these services have little to no training data available. Existing public datasets for task-oriented dialogue do not sufficiently capture these challenges since they cover few domains and assume a single static ontology per domain. In this work, we introduce the the Schema-Guided Dialogue (SGD) dataset, containing over 16k multi-domain conversations spanning 16 domains. Our dataset exceeds the existing task-oriented dialogue corpora in scale, while also highlighting the challenges associated with building large-scale virtual assistants. It provides a challenging testbed for a number of tasks including language understanding, slot filling, dialogue state tracking and response generation. Along the same lines, we present a schema-guided paradigm for task-oriented dialogue, in which predictions are made over a dynamic set of intents and slots, provided as input, using their natural language descriptions. This allows a single dialogue system to easily support a large number of services and facilitates simple integration of new services without requiring additional training data. Building upon the proposed paradigm, we release a zero-shot dialogue state tracking model that achieves state-of-the-art performance on recent benchmark datasets.
Neural Input Search for Large Scale Recommendation Models
Jul 10, 2019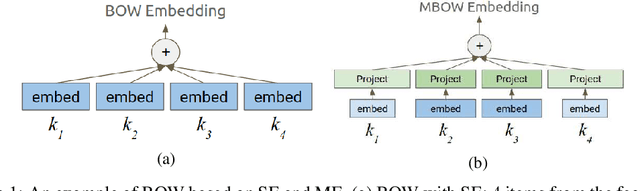

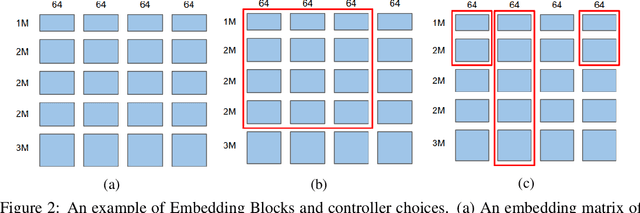
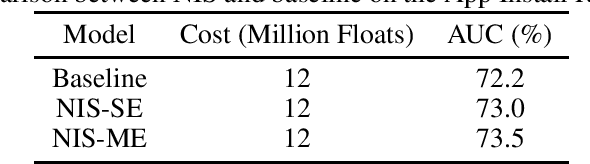
Recommendation problems with large numbers of discrete items, such as products, webpages, or videos, are ubiquitous in the technology industry. Deep neural networks are being increasingly used for these recommendation problems. These models use embeddings to represent discrete items as continuous vectors, and the vocabulary sizes and embedding dimensions, although heavily influence the model's accuracy, are often manually selected in a heuristical manner. We present Neural Input Search (NIS), a technique for learning the optimal vocabulary sizes and embedding dimensions for categorical features. The goal is to maximize prediction accuracy subject to a constraint on the total memory used by all embeddings. Moreover, we argue that the traditional Single-size Embedding (SE), which uses the same embedding dimension for all values of a feature, suffers from inefficient usage of model capacity and training data. We propose a novel type of embedding, namely Multi-size Embedding (ME), which allows the embedding dimension to vary for different values of the feature. During training we use reinforcement learning to find the optimal vocabulary size for each feature and embedding dimension for each value of the feature. In experiments on two common types of large scale recommendation problems, i.e. retrieval and ranking problems, NIS automatically found better vocabulary and embedding sizes that result in $6.8\%$ and $1.8\%$ relative improvements on Recall@1 and ROC-AUC over manually optimized ones.