 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Input Search for Large Scale Recommendation Models
Jul 10, 2019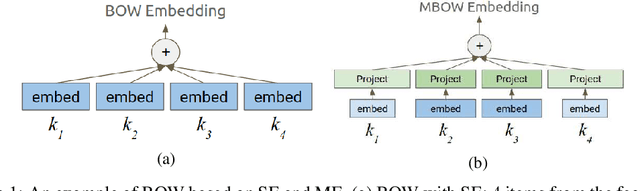

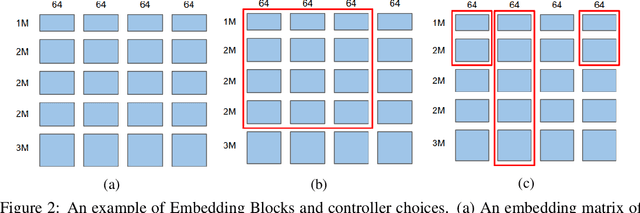
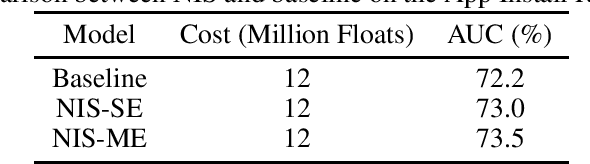
Recommendation problems with large numbers of discrete items, such as products, webpages, or videos, are ubiquitous in the technology industry. Deep neural networks are being increasingly used for these recommendation problems. These models use embeddings to represent discrete items as continuous vectors, and the vocabulary sizes and embedding dimensions, although heavily influence the model's accuracy, are often manually selected in a heuristical manner. We present Neural Input Search (NIS), a technique for learning the optimal vocabulary sizes and embedding dimensions for categorical features. The goal is to maximize prediction accuracy subject to a constraint on the total memory used by all embeddings. Moreover, we argue that the traditional Single-size Embedding (SE), which uses the same embedding dimension for all values of a feature, suffers from inefficient usage of model capacity and training data. We propose a novel type of embedding, namely Multi-size Embedding (ME), which allows the embedding dimension to vary for different values of the feature. During training we use reinforcement learning to find the optimal vocabulary size for each feature and embedding dimension for each value of the feature. In experiments on two common types of large scale recommendation problems, i.e. retrieval and ranking problems, NIS automatically found better vocabulary and embedding sizes that result in $6.8\%$ and $1.8\%$ relative improvements on Recall@1 and ROC-AUC over manually optimized ones.