 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scalable Multi-domain Conversational Agents: The Schema-Guided Dialogue Dataset
Paper and Code
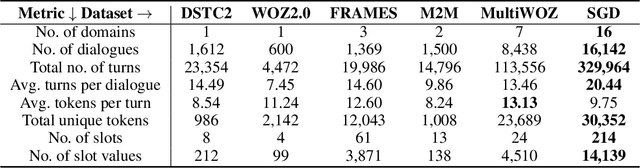
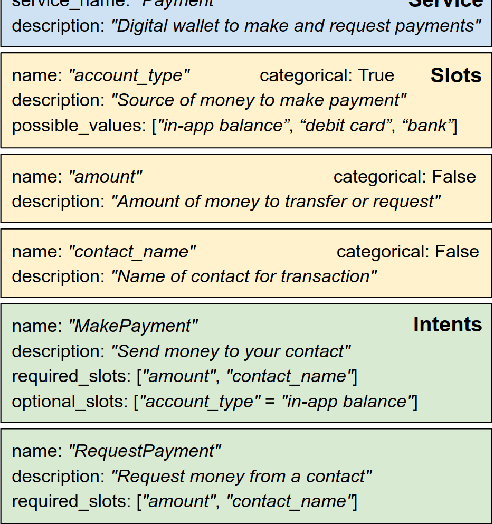
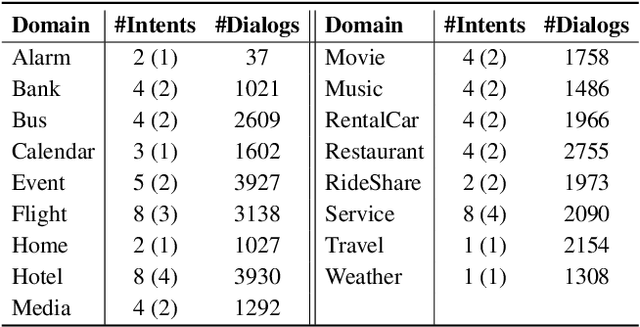
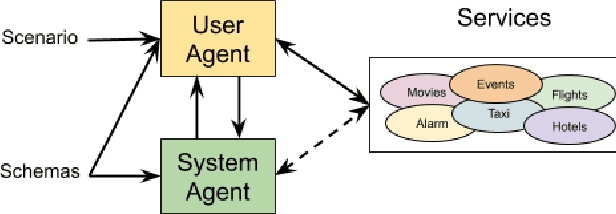
Virtual assistants such as Google Assistant, Alexa and Siri provide a conversational interface to a large number of services and APIs spanning multiple domains. Such systems need to support an ever-increasing number of services with possibly overlapping functionality. Furthermore, some of these services have little to no training data available. Existing public datasets for task-oriented dialogue do not sufficiently capture these challenges since they cover few domains and assume a single static ontology per domain. In this work, we introduce the the Schema-Guided Dialogue (SGD) dataset, containing over 16k multi-domain conversations spanning 16 domains. Our dataset exceeds the existing task-oriented dialogue corpora in scale, while also highlighting the challenges associated with building large-scale virtual assistants. It provides a challenging testbed for a number of tasks including language understanding, slot filling, dialogue state tracking and response generation. Along the same lines, we present a schema-guided paradigm for task-oriented dialogue, in which predictions are made over a dynamic set of intents and slots, provided as input, using their natural language descriptions. This allows a single dialogue system to easily support a large number of services and facilitates simple integration of new services without requiring additional training data. Building upon the proposed paradigm, we release a zero-shot dialogue state tracking model that achieves state-of-the-art performance on recent benchmark datasets.