 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailored Architectures for Time Series Forecasting: Evaluating Deep Learning Models on Gaussian Process-Generated Data
Jun 10, 2025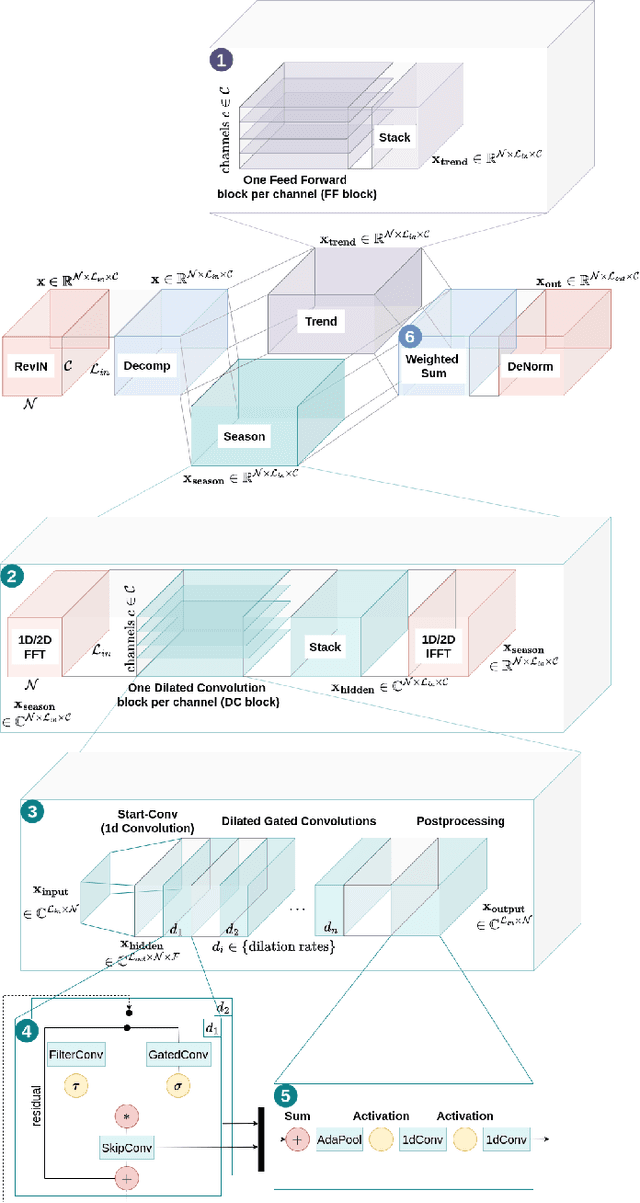
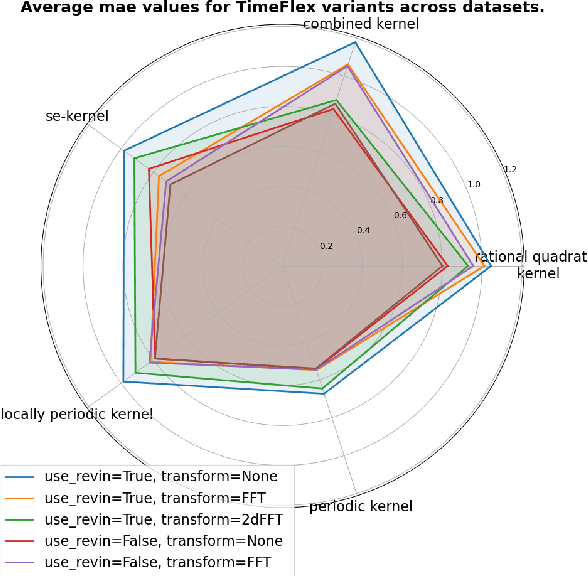
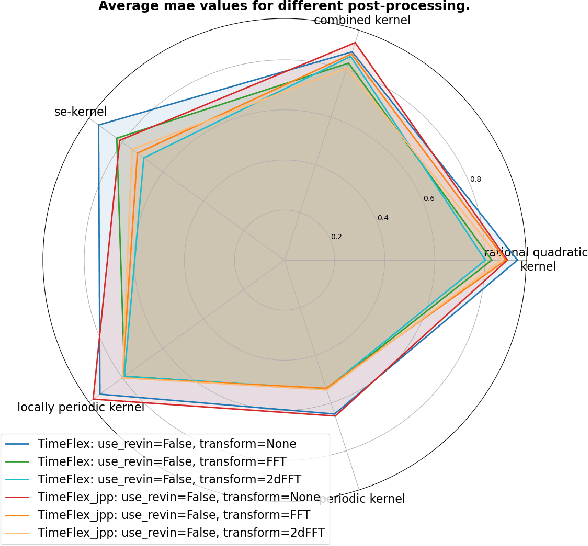
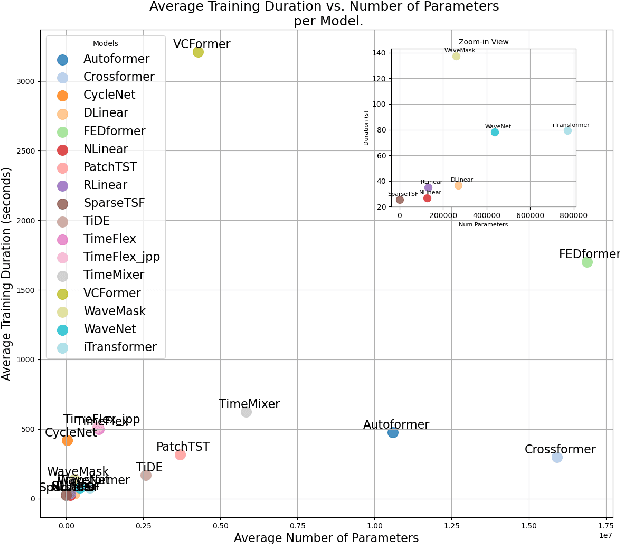
Developments in Deep Learning have significantly improved time series forecasting by enabling more accurate modeling of complex temporal dependencies inherent in sequential data. The effectiveness of such models is often demonstrated on limited sets of specific real-world data. Although this allows for comparative analysis, it still does not demonstrate how specific data characteristics align with the architectural strengths of individual models. Our research aims at uncovering clear connections between time series characteristics and particular models. We introduce a novel dataset generated using Gaussian Processes, specifically designed to display distinct, known characteristics for targeted evaluations of model adaptability to them. Furthermore, we present TimeFlex, a new model that incorporates a modular architecture tailored to handle diverse temporal dynamics, including trends and periodic patterns. This model is compared to current state-of-the-art models, offering a deeper understanding of how models perform under varied time series conditions.
The HalluRAG Dataset: Detecting Closed-Domain Hallucinations in RAG Applications Using an LLM's Internal States
Dec 22, 2024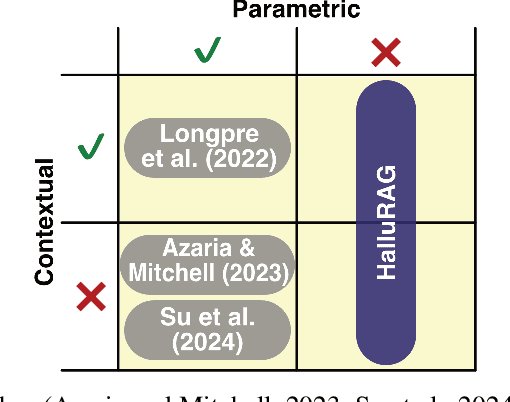
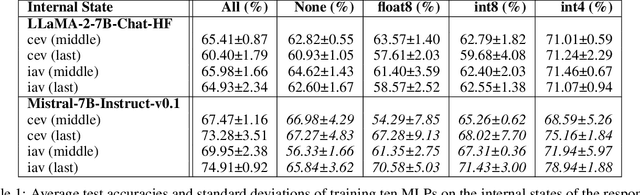
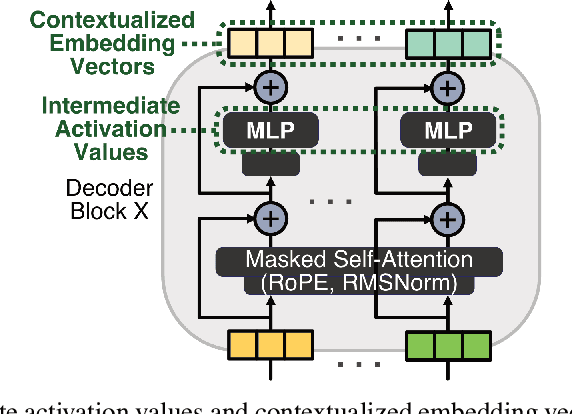
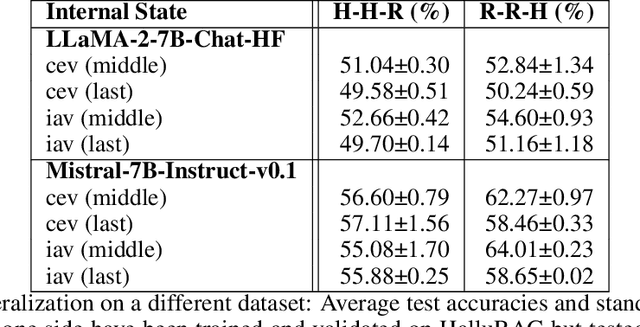
Detecting hallucinations in large language models (LLMs) is critical for enhancing their reliability and trustworthiness. Most research focuses on hallucinations as deviations from information seen during training. However, the opaque nature of an LLM's parametric knowledge complicates the understanding of why generated texts appear ungrounded: The LLM might not have picked up the necessary knowledge from large and often inaccessible datasets, or the information might have been changed or contradicted during further training. Our focus is on hallucinations involving information not used in training, which we determine by using recency to ensure the information emerged after a cut-off date. This study investigates these hallucinations by detecting them at sentence level using different internal states of various LLMs. We present HalluRAG, a dataset designed to train classifiers on these hallucinations. Depending on the model and quantization, MLPs trained on HalluRAG detect hallucinations with test accuracies ranging up to 75 %, with Mistral-7B-Instruct-v0.1 achieving the highest test accuracies. Our results show that IAVs detect hallucinations as effectively as CEVs and reveal that answerable and unanswerable prompts are encoded differently as separate classifiers for these categories improved accuracy. However, HalluRAG showed some limited generalizability, advocating for more diversity in datasets on hallucinations.
Evaluating the Impact of Advanced LLM Techniques on AI-Lecture Tutors for a Robotics Course
Aug 02, 2024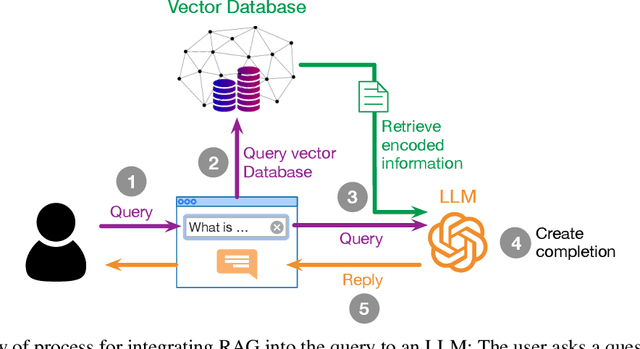

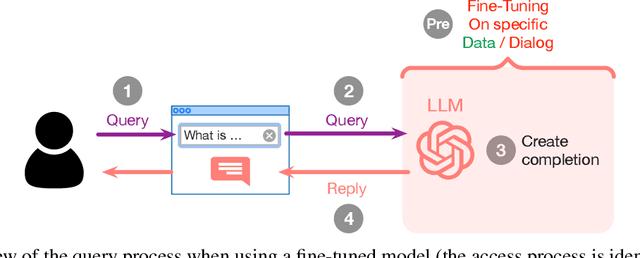
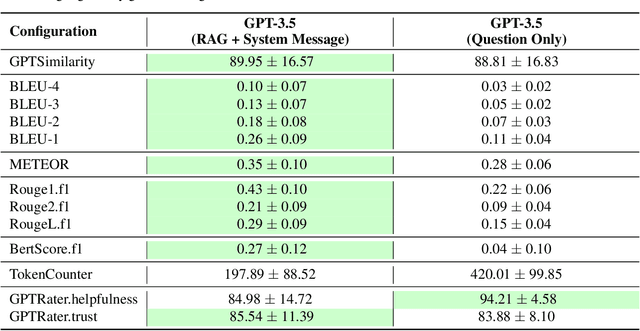
This study evaluates the performance of Large Language Models (LLMs) as an Artificial Intelligence-based tutor for a university course. In particular, different advanced techniques are utilized, such as prompt engineering, Retrieval-Augmented-Generation (RAG), and fine-tuning. We assessed the different models and applied techniques using common similarity metrics like BLEU-4, ROUGE, and BERTScore, complemented by a small human evaluation of helpfulness and trustworthiness. Our findings indicate that RAG combined with prompt engineering significantly enhances model responses and produces better factual answers. In the context of education, RAG appears as an ideal technique as it is based on enriching the input of the model with additional information and material which usually is already present for a university course. Fine-tuning, on the other hand, can produce quite small, still strong expert models, but poses the danger of overfitting. Our study further asks how we measure performance of LLMs and how well current measurements represent correctness or relevance? We find high correlation on similarity metrics and a bias of most of these metrics towards shorter responses. Overall, our research points to both the potential and challenges of integrating LLMs in educational settings, suggesting a need for balanced training approaches and advanced evaluation frameworks.
Traffic4cast at NeurIPS 2021 -- Temporal and Spatial Few-Shot Transfer Learning in Gridded Geo-Spatial Processes
Apr 01, 2022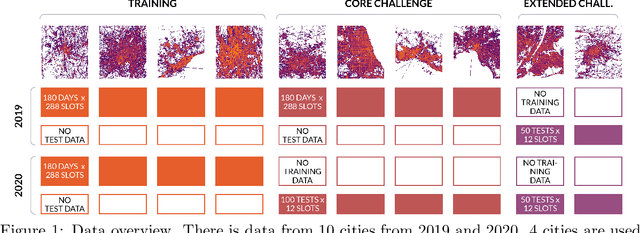
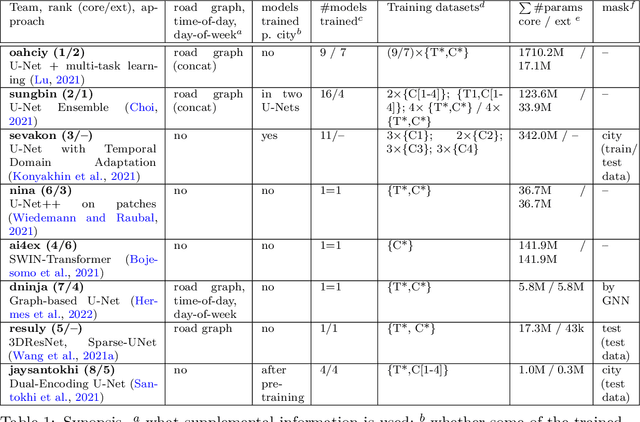
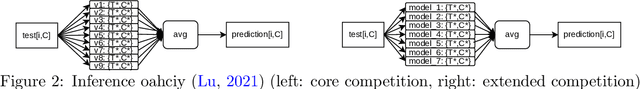
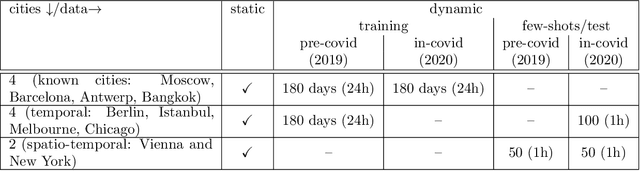
The IARAI Traffic4cast competitions at NeurIPS 2019 and 2020 showed that neural networks can successfully predict future traffic conditions 1 hour into the future on simply aggregated GPS probe data in time and space bins. We thus reinterpreted the challenge of forecasting traffic conditions as a movie completion task. U-Nets proved to be the winning architecture, demonstrating an ability to extract relevant features in this complex real-world geo-spatial process. Building on the previous competitions, Traffic4cast 2021 now focuses on the question of model robustness and generalizability across time and space. Moving from one city to an entirely different city, or moving from pre-COVID times to times after COVID hit the world thus introduces a clear domain shift. We thus, for the first time, release data featuring such domain shifts. The competition now covers ten cities over 2 years, providing data compiled from over 10^12 GPS probe data. Winning solutions captured traffic dynamics sufficiently well to even cope with these complex domain shifts. Surprisingly, this seemed to require only the previous 1h traffic dynamic history and static road graph as input.
A Graph-based U-Net Model for Predicting Traffic in unseen Cities
Mar 01, 2022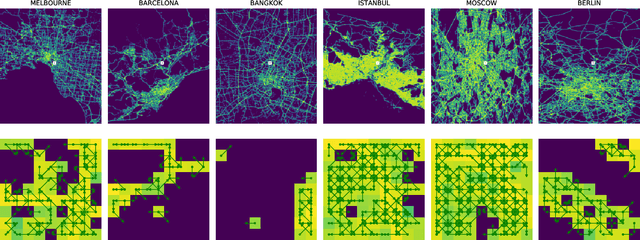
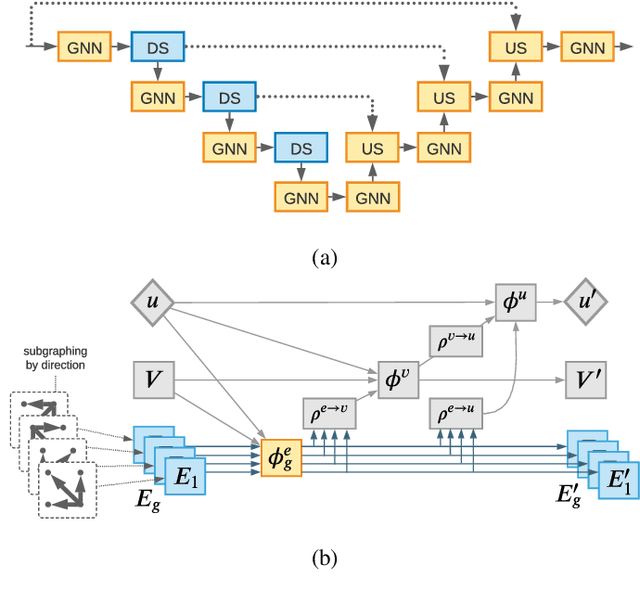
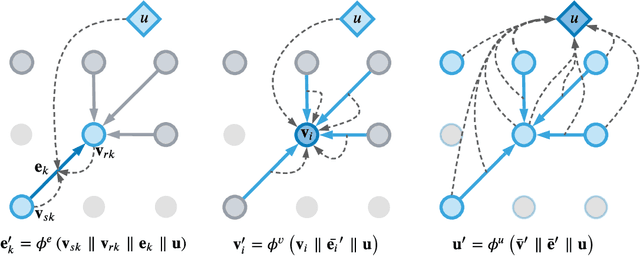
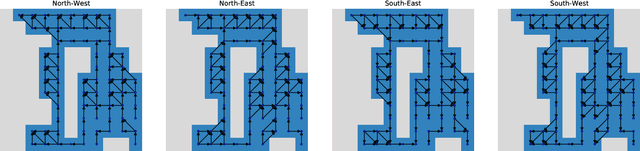
Accurate traffic prediction is a key ingredient to enable traffic management like rerouting cars to reduce road congestion or regulating traffic via dynamic speed limits to maintain a steady flow. A way to represent traffic data is in the form of temporally changing heatmaps visualizing attributes of traffic, such as speed and volume. In recent works, U-Net models have shown SOTA performance on traffic forecasting from heatmaps. We propose to combine the U-Net architecture with graph layers which improves spatial generalization to unseen road networks compared to a Vanilla U-Net. In particular, we specialize existing graph operations to be sensitive to geographical topology and generalize pooling and upsampling operations to be applicable to graphs.
Application of Graph Convolutions in a Lightweight Model for Skeletal Human Motion Forecasting
Oct 10, 2021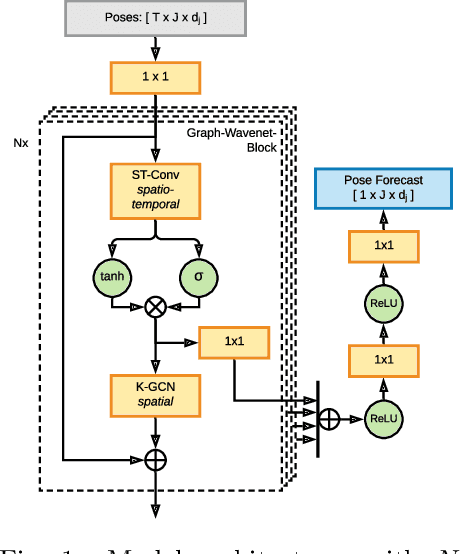
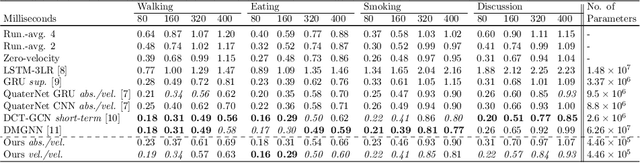
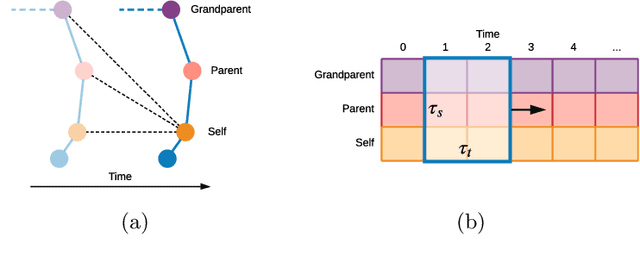
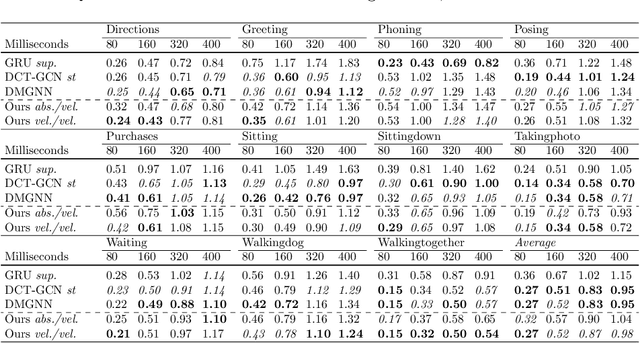
Prediction of movements is essential for successful cooperation with intelligent systems. We propose a model that integrates organized spatial information as given through the moving body's skeletal structure. This inherent structure is exploited in our model through application of Graph Convolutions and we demonstrate how this allows leveraging the structured spatial information into competitive predictions that are based on a lightweight model that requires a comparatively small number of parameters.
Decentralized Deep Reinforcement Learning for a Distributed and Adaptive Locomotion Controller of a Hexapod Robot
May 21, 2020
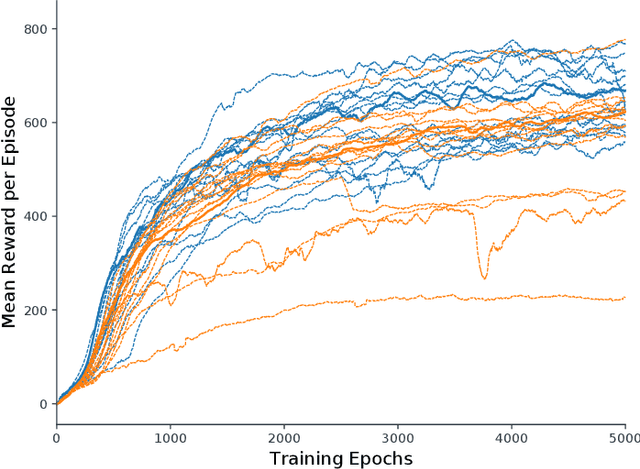
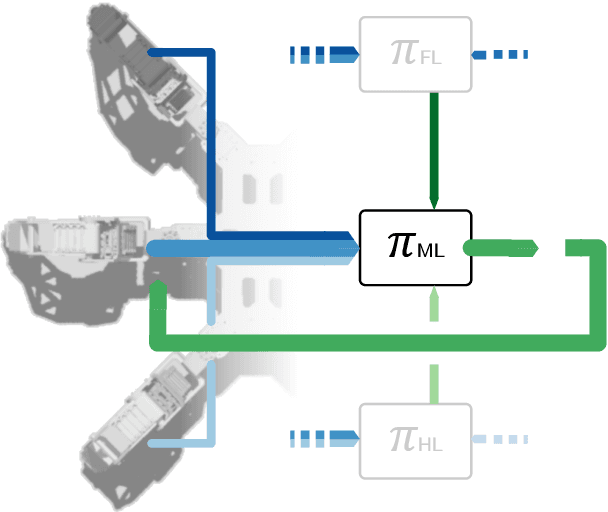
Locomotion is a prime example for adaptive behavior in animals and biological control principles have inspired control architectures for legged robots. While machine learning has been successfully applied to many tasks in recent years, Deep Reinforcement Learning approaches still appear to struggle when applied to real world robots in continuous control tasks and in particular do not appear as robust solutions that can handle uncertainties well. Therefore, there is a new interest in incorporating biological principles into such learning architectures. While inducing a hierarchical organization as found in motor control has shown already some success, we here propose a decentralized organization as found in insect motor control for coordination of different legs. A decentralized and distributed architecture is introduced on a simulated hexapod robot and the details of the controller are learned through Deep Reinforcement Learning. We first show that such a concurrent local structure is able to learn better walking behavior. Secondly, that the simpler organization is learned faster compared to holistic approaches.
A Perceived Environment Design using a Multi-Modal Variational Autoencoder for learning Active-Sensing
Nov 01, 2019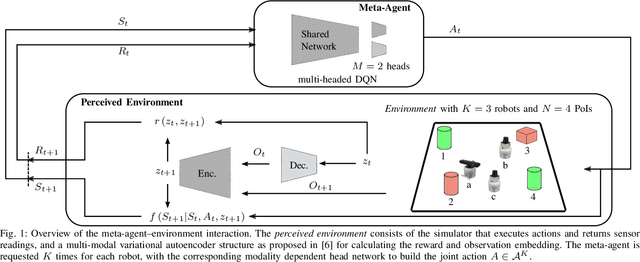
This contribution comprises the interplay between a multi-modal variational autoencoder and an environment to a perceived environment, on which an agent can act. Furthermore, we conclude our work with a comparison to curiosity-driven learning.
From Crystallized Adaptivity to Fluid Adaptivity in Deep Reinforcement Learning -- Insights from Biological Systems on Adaptive Flexibility
Aug 13, 2019
Recent developments in machine-learning algorithms have led to impressive performance increases in many traditional application scenarios of artificial intelligence research. In the area of deep reinforcement learning, deep learning functional architectures are combined with incremental learning schemes for sequential tasks that include interaction-based, but often delayed feedback. Despite their impressive successes, modern machine-learning approaches, including deep reinforcement learning, still perform weakly when compared to flexibly adaptive biological systems in certain naturally occurring scenarios. Such scenarios include transfers to environments different than the ones in which the training took place or environments that dynamically change, both of which are often mastered by biological systems through a capability that we here term "fluid adaptivity" to contrast it from the much slower adaptivity ("crystallized adaptivity") of the prior learning from which the behavior emerged. In this article, we derive and discuss research strategies, based on analyzes of fluid adaptivity in biological systems and its neuronal modeling, that might aid in equipping future artificially intelligent systems with capabilities of fluid adaptivity more similar to those seen in some biologically intelligent systems. A key component of this research strategy is the dynamization of the problem space itself and the implementation of this dynamization by suitably designed flexibly interacting modules.
Setup of a Recurrent Neural Network as a Body Model for Solving Inverse and Forward Kinematics as well as Dynamics for a Redundant Manipulator
Apr 12, 2019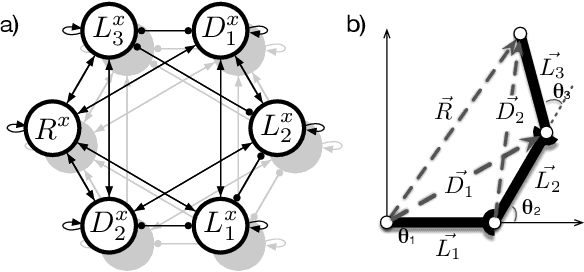
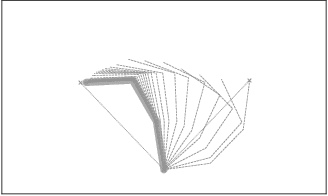
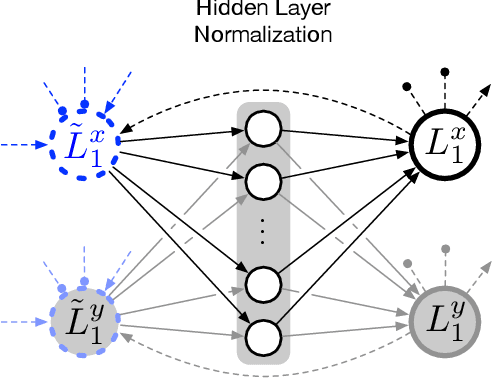
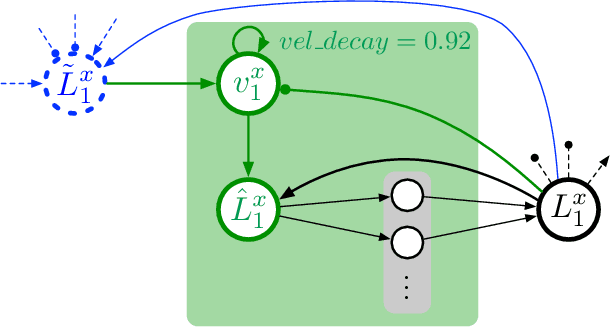
An internal model of the own body can be assumed a fundamental and evolutionary-early representation as it is present throughout the animal kingdom. Such functional models are, on the one hand, required in motor control, for example solving the inverse kinematic or dynamic task in goal-directed movements or a forward task in ballistic movements. On the other hand, such models are recruited in cognitive tasks as are planning ahead or observation of actions of a conspecific. Here, we present a functional internal body model that is based on the Mean of Multiple Computations principle. For the first time such a model is completely realized in a recurrent neural network as necessary normalization steps are integrated into the neural model itself. Secondly, a dynamic extension is applied to the model. It is shown how the neural network solves a series of inverse tasks. Furthermore, emerging representation in transformational layers are analyzed that show a form of prototypical population-coding as found in place or direction cells.