 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe HalluRAG Dataset: Detecting Closed-Domain Hallucinations in RAG Applications Using an LLM's Internal States
Dec 22, 2024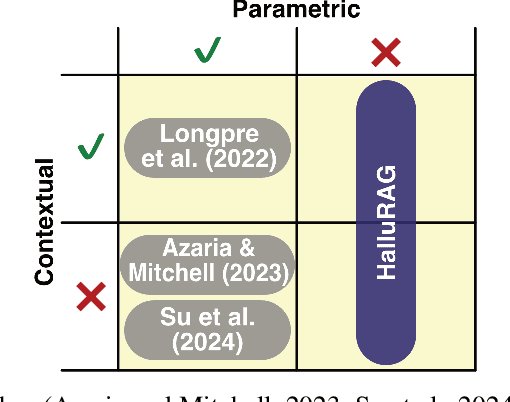
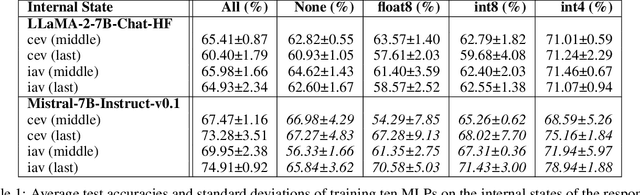
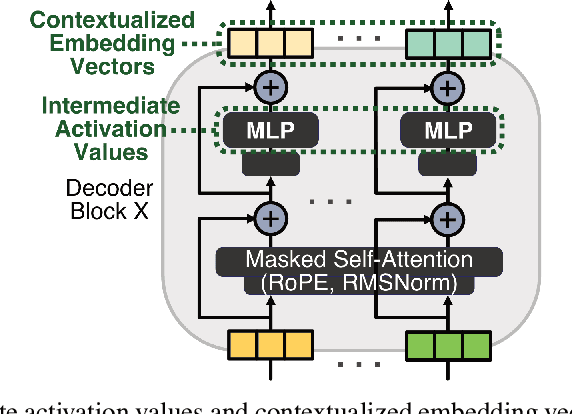
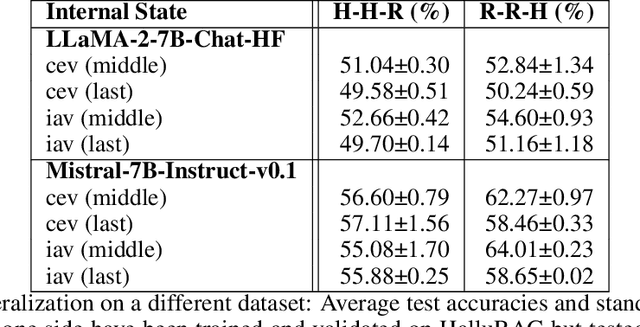
Detecting hallucinations in large language models (LLMs) is critical for enhancing their reliability and trustworthiness. Most research focuses on hallucinations as deviations from information seen during training. However, the opaque nature of an LLM's parametric knowledge complicates the understanding of why generated texts appear ungrounded: The LLM might not have picked up the necessary knowledge from large and often inaccessible datasets, or the information might have been changed or contradicted during further training. Our focus is on hallucinations involving information not used in training, which we determine by using recency to ensure the information emerged after a cut-off date. This study investigates these hallucinations by detecting them at sentence level using different internal states of various LLMs. We present HalluRAG, a dataset designed to train classifiers on these hallucinations. Depending on the model and quantization, MLPs trained on HalluRAG detect hallucinations with test accuracies ranging up to 75 %, with Mistral-7B-Instruct-v0.1 achieving the highest test accuracies. Our results show that IAVs detect hallucinations as effectively as CEVs and reveal that answerable and unanswerable prompts are encoded differently as separate classifiers for these categories improved accuracy. However, HalluRAG showed some limited generalizability, advocating for more diversity in datasets on hallucinations.
Evaluating the Impact of Advanced LLM Techniques on AI-Lecture Tutors for a Robotics Course
Aug 02, 2024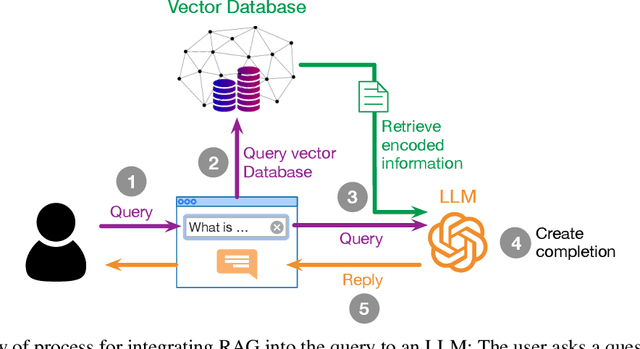

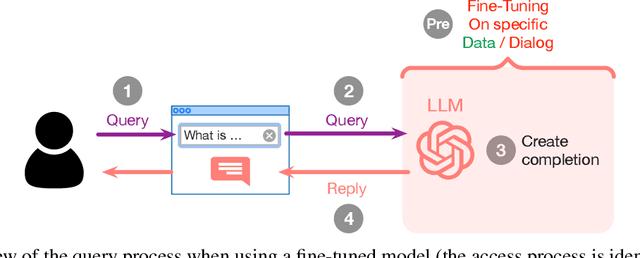
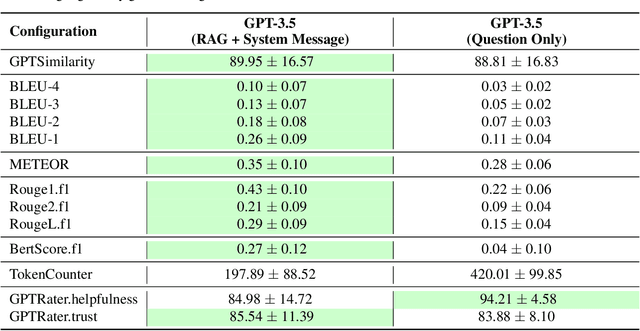
This study evaluates the performance of Large Language Models (LLMs) as an Artificial Intelligence-based tutor for a university course. In particular, different advanced techniques are utilized, such as prompt engineering, Retrieval-Augmented-Generation (RAG), and fine-tuning. We assessed the different models and applied techniques using common similarity metrics like BLEU-4, ROUGE, and BERTScore, complemented by a small human evaluation of helpfulness and trustworthiness. Our findings indicate that RAG combined with prompt engineering significantly enhances model responses and produces better factual answers. In the context of education, RAG appears as an ideal technique as it is based on enriching the input of the model with additional information and material which usually is already present for a university course. Fine-tuning, on the other hand, can produce quite small, still strong expert models, but poses the danger of overfitting. Our study further asks how we measure performance of LLMs and how well current measurements represent correctness or relevance? We find high correlation on similarity metrics and a bias of most of these metrics towards shorter responses. Overall, our research points to both the potential and challenges of integrating LLMs in educational settings, suggesting a need for balanced training approaches and advanced evaluation frameworks.