 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Impact of Advanced LLM Techniques on AI-Lecture Tutors for a Robotics Course
Aug 02, 2024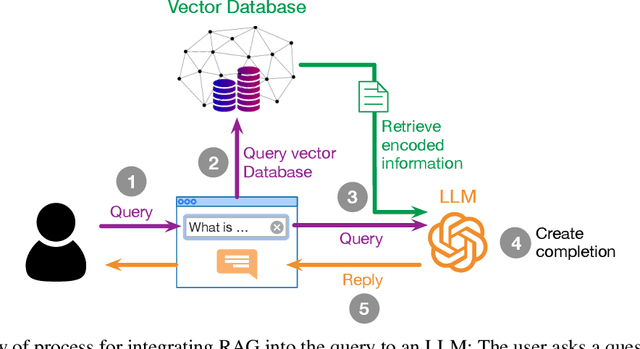

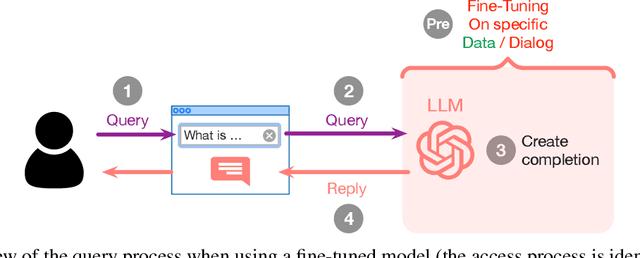
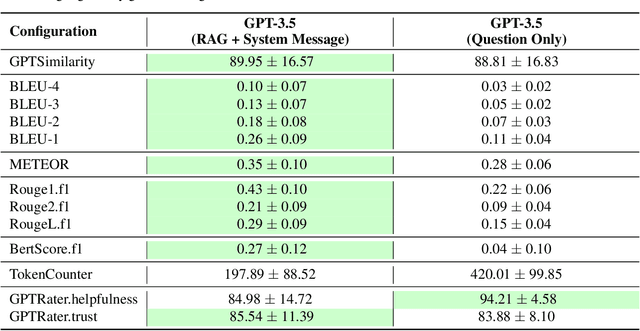
This study evaluates the performance of Large Language Models (LLMs) as an Artificial Intelligence-based tutor for a university course. In particular, different advanced techniques are utilized, such as prompt engineering, Retrieval-Augmented-Generation (RAG), and fine-tuning. We assessed the different models and applied techniques using common similarity metrics like BLEU-4, ROUGE, and BERTScore, complemented by a small human evaluation of helpfulness and trustworthiness. Our findings indicate that RAG combined with prompt engineering significantly enhances model responses and produces better factual answers. In the context of education, RAG appears as an ideal technique as it is based on enriching the input of the model with additional information and material which usually is already present for a university course. Fine-tuning, on the other hand, can produce quite small, still strong expert models, but poses the danger of overfitting. Our study further asks how we measure performance of LLMs and how well current measurements represent correctness or relevance? We find high correlation on similarity metrics and a bias of most of these metrics towards shorter responses. Overall, our research points to both the potential and challenges of integrating LLMs in educational settings, suggesting a need for balanced training approaches and advanced evaluation frameworks.