 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Encoding Temporal Evolution for Real-time Action Prediction
Feb 08, 2018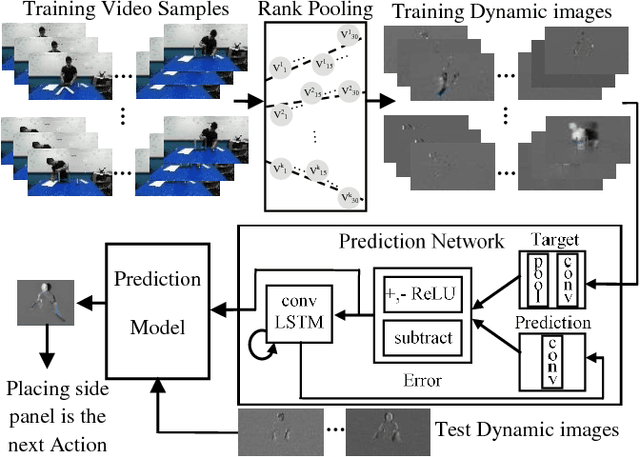
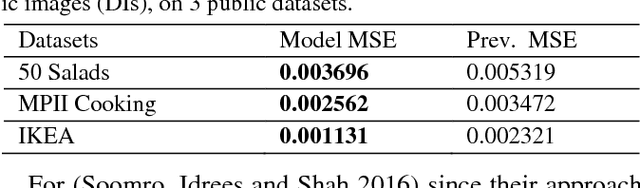

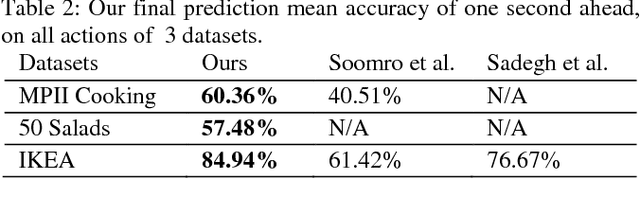
Anticipating future actions is a key component of intelligence, specifically when it applies to real-time systems, such as robots or autonomous cars. While recent works have addressed prediction of raw RGB pixel values, we focus on anticipating the motion evolution in future video frames. To this end, we construct dynamic images (DIs) by summarising moving pixels through a sequence of future frames. We train a convolutional LSTMs to predict the next DIs based on an unsupervised learning process, and then recognise the activity associated with the predicted DI. We demonstrate the effectiveness of our approach on 3 benchmark action datasets showing that despite running on videos with complex activities, our approach is able to anticipate the next human action with high accuracy and obtain better results than the state-of-the-art methods.
Action Recognition: From Static Datasets to Moving Robots
Jan 18, 2017
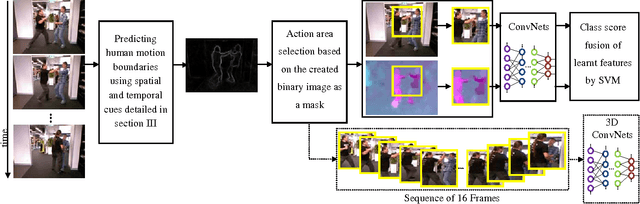
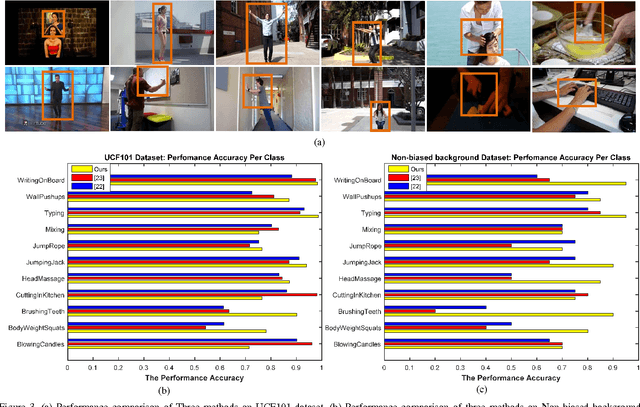

Deep learning models have achieved state-of-the- art performance in recognizing human activities, but often rely on utilizing background cues present in typical computer vision datasets that predominantly have a stationary camera. If these models are to be employed by autonomous robots in real world environments, they must be adapted to perform independently of background cues and camera motion effects. To address these challenges, we propose a new method that firstly generates generic action region proposals with good potential to locate one human action in unconstrained videos regardless of camera motion and then uses action proposals to extract and classify effective shape and motion features by a ConvNet framework. In a range of experiments, we demonstrate that by actively proposing action regions during both training and testing, state-of-the-art or better performance is achieved on benchmarks. We show the outperformance of our approach compared to the state-of-the-art in two new datasets; one emphasizes on irrelevant background, the other highlights the camera motion. We also validate our action recognition method in an abnormal behavior detection scenario to improve workplace safety. The results verify a higher success rate for our method due to the ability of our system to recognize human actions regardless of environment and camera motion.
Evaluation of Object Detection Proposals Under Condition Variations
Dec 10, 2015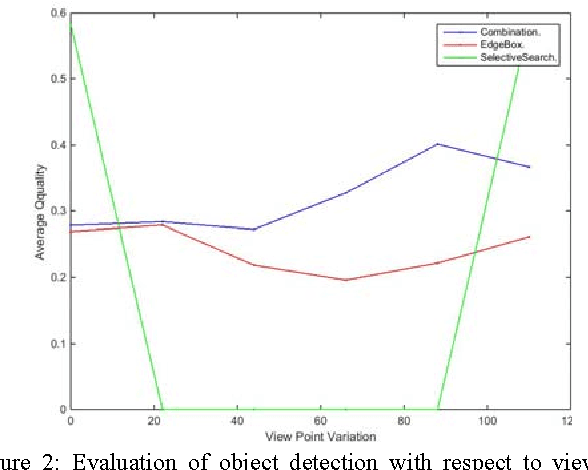
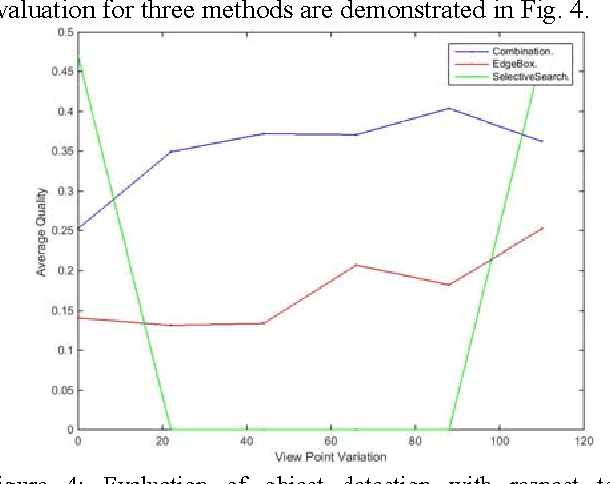
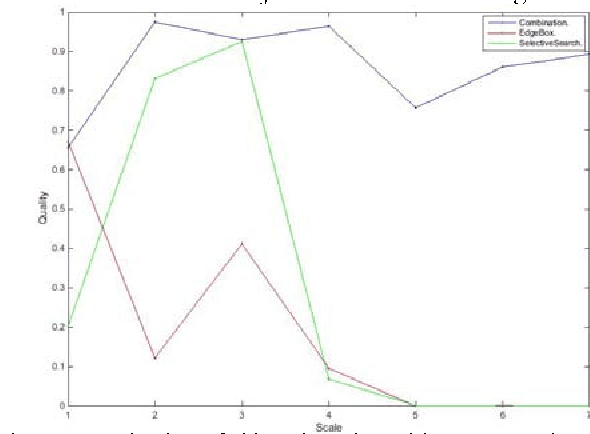
Object detection is a fundamental task in many computer vision applications, therefore the importance of evaluating the quality of object detection is well acknowledged in this domain. This process gives insight into the capabilities of methods in handling environmental changes. In this paper, a new method for object detection is introduced that combines the Selective Search and EdgeBoxes. We tested these three methods under environmental variations. Our experiments demonstrate the outperformance of the combination method under illumination and view point variations.