 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUTNet: Rethinking Inference in FPGA Soft Logic
Paper and Code
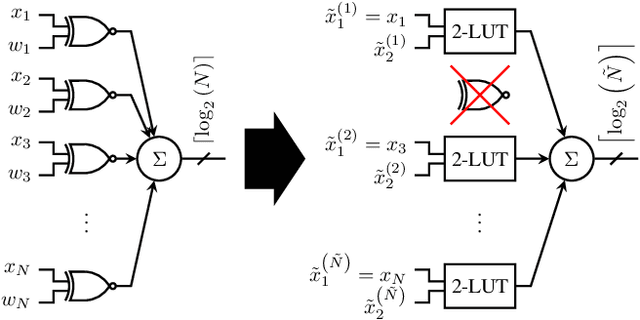
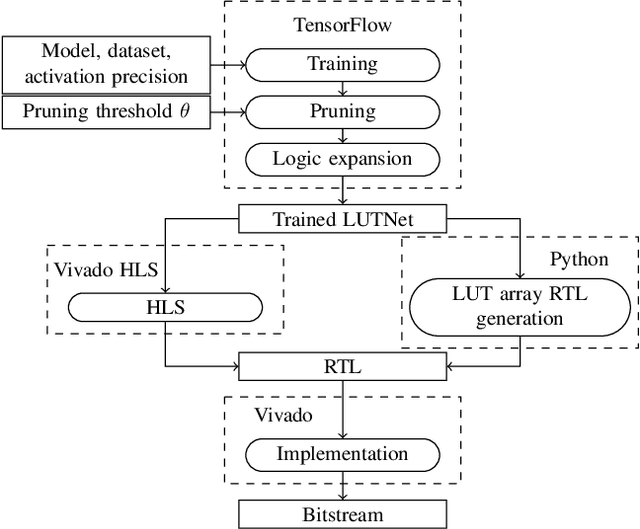
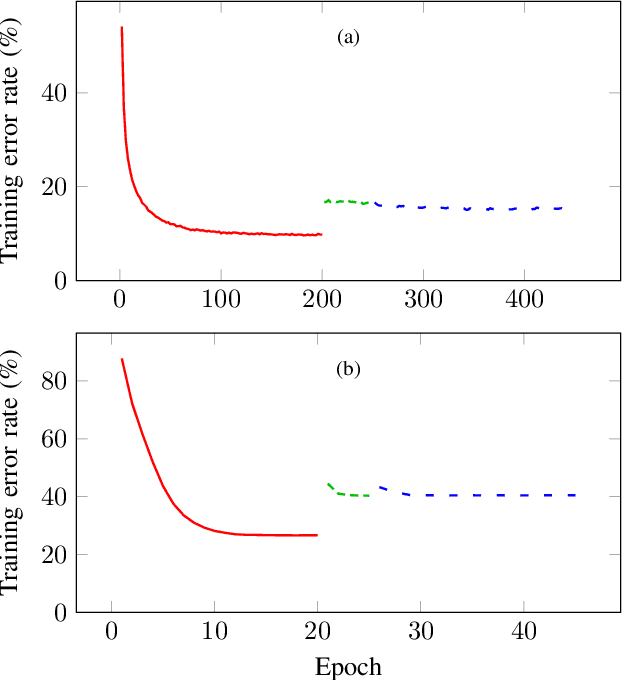
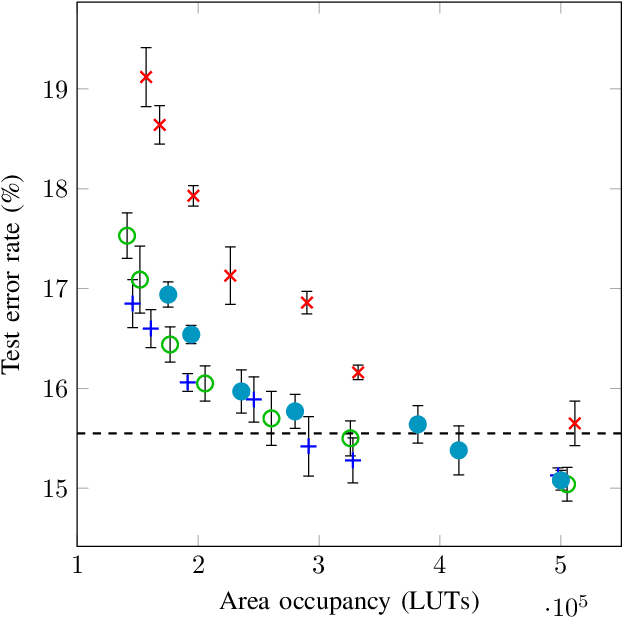
Research has shown that deep neural networks contain significant redundancy, and that high classification accuracies can be achieved even when weights and activations are quantised down to binary values. Network binarisation on FPGAs greatly increases area efficiency by replacing resource-hungry multipliers with lightweight XNOR gates. However, an FPGA's fundamental building block, the K-LUT, is capable of implementing far more than an XNOR: it can perform any K-input Boolean operation. Inspired by this observation, we propose LUTNet, an end-to-end hardware-software framework for the construction of area-efficient FPGA-based neural network accelerators using the native LUTs as inference operators. We demonstrate that the exploitation of LUT flexibility allows for far heavier pruning than possible in prior works, resulting in significant area savings while achieving comparable accuracy. Against the state-of-the-art binarised neural network implementation, we achieve twice the area efficiency for several standard network models when inferencing popular datasets. We also demonstrate that even greater energy efficiency improvements are obtainable.