 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic Shrinkage: Learned FPGA Netlist Sparsity for Efficient Neural Network Inference
Paper and Code
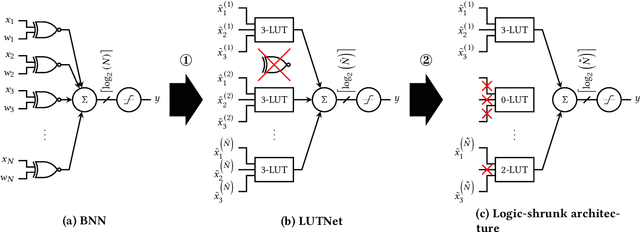
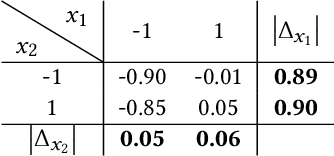
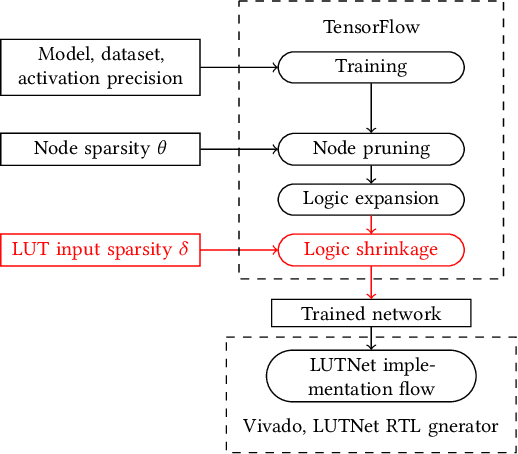

FPGA-specific DNN architectures using the native LUTs as independently trainable inference operators have been shown to achieve favorable area-accuracy and energy-accuracy tradeoffs. The first work in this area, LUTNet, exhibited state-of-the-art performance for standard DNN benchmarks. In this paper, we propose the learned optimization of such LUT-based topologies, resulting in higher-efficiency designs than via the direct use of off-the-shelf, hand-designed networks. Existing implementations of this class of architecture require the manual specification of the number of inputs per LUT, K. Choosing appropriate K a priori is challenging, and doing so at even high granularity, e.g. per layer, is a time-consuming and error-prone process that leaves FPGAs' spatial flexibility underexploited. Furthermore, prior works see LUT inputs connected randomly, which does not guarantee a good choice of network topology. To address these issues, we propose logic shrinkage, a fine-grained netlist pruning methodology enabling K to be automatically learned for every LUT in a neural network targeted for FPGA inference. By removing LUT inputs determined to be of low importance, our method increases the efficiency of the resultant accelerators. Our GPU-friendly solution to LUT input removal is capable of processing large topologies during their training with negligible slowdown. With logic shrinkage, we better the area and energy efficiency of the best-performing LUTNet implementation of the CNV network classifying CIFAR-10 by 1.54x and 1.31x, respectively, while matching its accuracy. This implementation also reaches 2.71x the area efficiency of an equally accurate, heavily pruned BNN. On ImageNet with the Bi-Real Net architecture, employment of logic shrinkage results in a post-synthesis area reduction of 2.67x vs LUTNet, allowing for implementation that was previously impossible on today's largest FPGAs.