 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMPLE: Event-Driven Accelerator for Mixed-Precision Inference of Graph Neural Networks
Feb 28, 2025
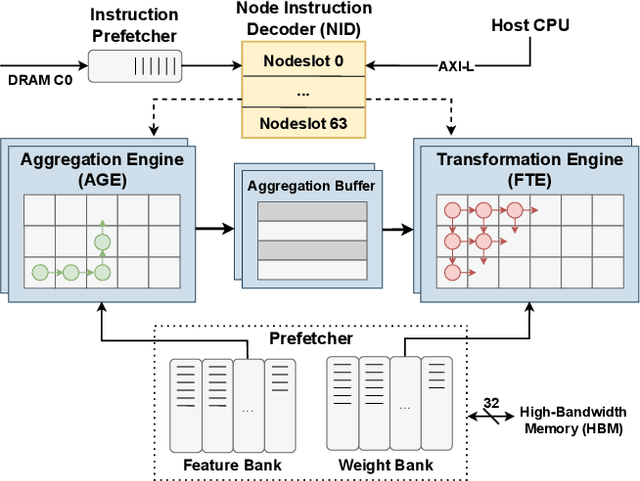

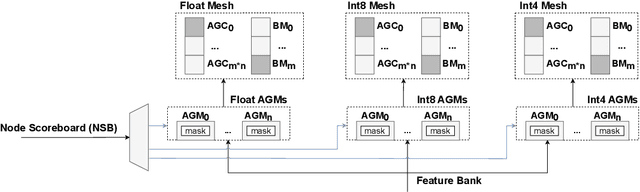
Graph Neural Networks (GNNs) have recently gained attention due to their performance on non-Euclidean data. The use of custom hardware architectures proves particularly beneficial for GNNs due to their irregular memory access patterns, resulting from the sparse structure of graphs. However, existing FPGA accelerators are limited by their double buffering mechanism, which doesn't account for the irregular node distribution in typical graph datasets. To address this, we introduce \textbf{AMPLE} (Accelerated Message Passing Logic Engine), an FPGA accelerator leveraging a new event-driven programming flow. We develop a mixed-arithmetic architecture, enabling GNN inference to be quantized at a node-level granularity. Finally, prefetcher for data and instructions is implemented to optimize off-chip memory access and maximize node parallelism. Evaluation on citation and social media graph datasets ranging from $2$K to $700$K nodes showed a mean speedup of $243\times$ and $7.2\times$ against CPU and GPU counterparts, respectively.
Automatic Generation of Multi-precision Multi-arithmetic CNN Accelerators for FPGAs
Oct 21, 2019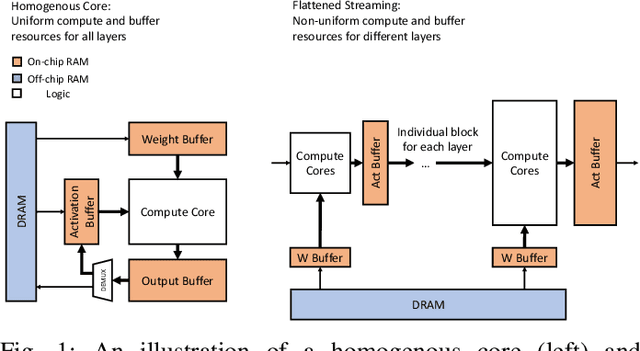
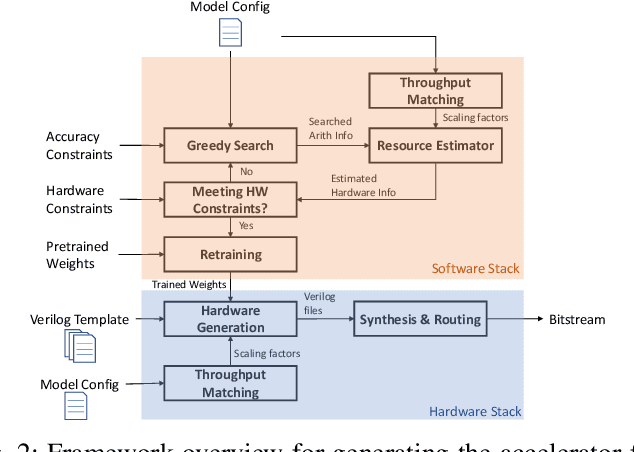
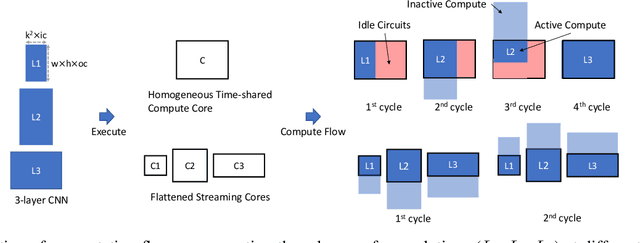
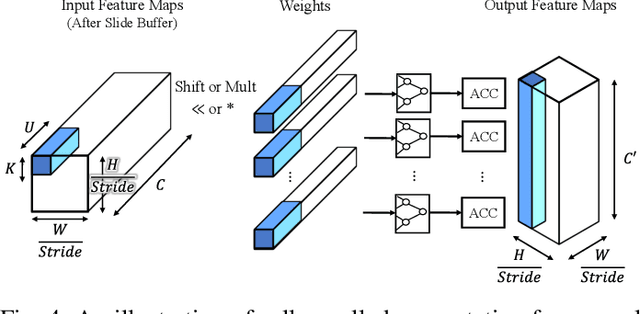
Modern deep Convolutional Neural Networks (CNNs) are computationally demanding, yet real applications often require high throughput and low latency. To help tackle these problems, we propose Tomato, a framework designed to automate the process of generating efficient CNN accelerators. The generated design is pipelined and each convolution layer uses different arithmetics at various precisions. Using Tomato, we showcase state-of-the-art multi-precision multi-arithmetic networks, including MobileNet-V1, running on FPGAs. To our knowledge, this is the first multi-precision multi-arithmetic auto-generation framework for CNNs. In software, Tomato fine-tunes pretrained networks to use a mixture of short powers-of-2 and fixed-point weights with a minimal loss in classification accuracy. The fine-tuned parameters are combined with the templated hardware designs to automatically produce efficient inference circuits in FPGAs. We demonstrate how our approach significantly reduces model sizes and computation complexities, and permits us to pack a complete ImageNet network onto a single FPGA without accessing off-chip memories for the first time. Furthermore, we show how Tomato produces implementations of networks with various sizes running on single or multiple FPGAs. To the best of our knowledge, our automatically generated accelerators outperform closest FPGA-based competitors by at least 2-4x for lantency and throughput; the generated accelerator runs ImageNet classification at a rate of more than 3000 frames per second.