 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustom Gradient Estimators are Straight-Through Estimators in Disguise
May 08, 2024Quantization-aware training comes with a fundamental challenge: the derivative of quantization functions such as rounding are zero almost everywhere and nonexistent elsewhere. Various differentiable approximations of quantization functions have been proposed to address this issue. In this paper, we prove that when the learning rate is sufficiently small, a large class of weight gradient estimators is equivalent with the straight through estimator (STE). Specifically, after swapping in the STE and adjusting both the weight initialization and the learning rate in SGD, the model will train in almost exactly the same way as it did with the original gradient estimator. Moreover, we show that for adaptive learning rate algorithms like Adam, the same result can be seen without any modifications to the weight initialization and learning rate. We experimentally show that these results hold for both a small convolutional model trained on the MNIST dataset and for a ResNet50 model trained on ImageNet.
MobileNetV4 -- Universal Models for the Mobile Ecosystem
Apr 16, 2024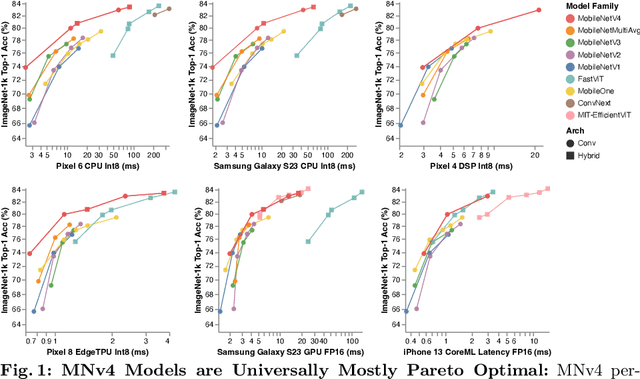
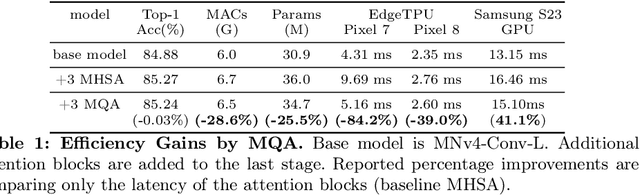
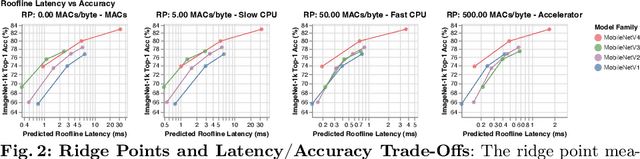
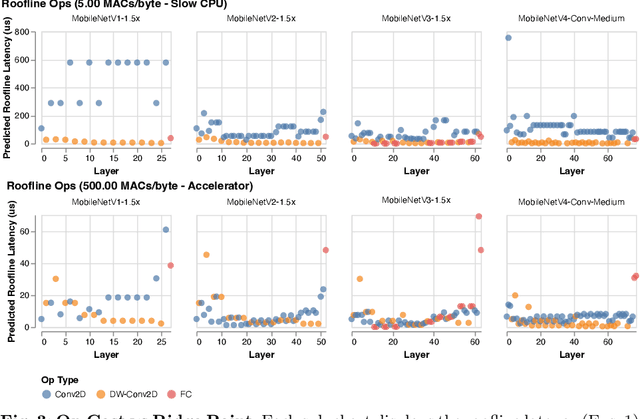
We present the latest generation of MobileNets, known as MobileNetV4 (MNv4), featuring universally efficient architecture designs for mobile devices. At its core, we introduce the Universal Inverted Bottleneck (UIB) search block, a unified and flexible structure that merges Inverted Bottleneck (IB), ConvNext, Feed Forward Network (FFN), and a novel Extra Depthwise (ExtraDW) variant. Alongside UIB, we present Mobile MQA, an attention block tailored for mobile accelerators, delivering a significant 39% speedup. An optimized neural architecture search (NAS) recipe is also introduced which improves MNv4 search effectiveness. The integration of UIB, Mobile MQA and the refined NAS recipe results in a new suite of MNv4 models that are mostly Pareto optimal across mobile CPUs, DSPs, GPUs, as well as specialized accelerators like Apple Neural Engine and Google Pixel EdgeTPU - a characteristic not found in any other models tested. Finally, to further boost accuracy, we introduce a novel distillation technique. Enhanced by this technique, our MNv4-Hybrid-Large model delivers 87% ImageNet-1K accuracy, with a Pixel 8 EdgeTPU runtime of just 3.8ms.
PikeLPN: Mitigating Overlooked Inefficiencies of Low-Precision Neural Networks
Mar 29, 2024Low-precision quantization is recognized for its efficacy in neural network optimization. Our analysis reveals that non-quantized elementwise operations which are prevalent in layers such as parameterized activation functions, batch normalization, and quantization scaling dominate the inference cost of low-precision models. These non-quantized elementwise operations are commonly overlooked in SOTA efficiency metrics such as Arithmetic Computation Effort (ACE). In this paper, we propose ACEv2 - an extended version of ACE which offers a better alignment with the inference cost of quantized models and their energy consumption on ML hardware. Moreover, we introduce PikeLPN, a model that addresses these efficiency issues by applying quantization to both elementwise operations and multiply-accumulate operations. In particular, we present a novel quantization technique for batch normalization layers named QuantNorm which allows for quantizing the batch normalization parameters without compromising the model performance. Additionally, we propose applying Double Quantization where the quantization scaling parameters are quantized. Furthermore, we recognize and resolve the issue of distribution mismatch in Separable Convolution layers by introducing Distribution-Heterogeneous Quantization which enables quantizing them to low-precision. PikeLPN achieves Pareto-optimality in efficiency-accuracy trade-off with up to 3X efficiency improvement compared to SOTA low-precision models.
Enabling Binary Neural Network Training on the Edge
Feb 10, 2021
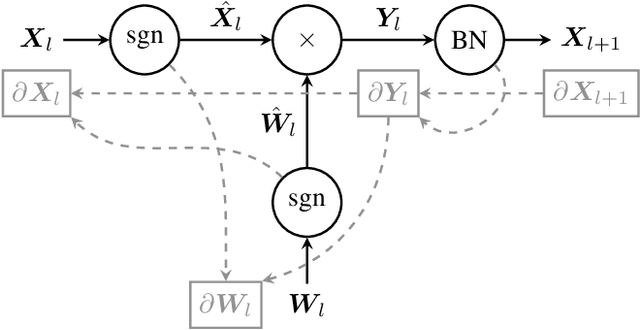
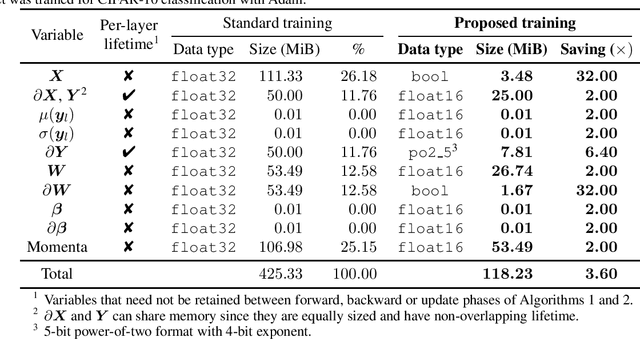
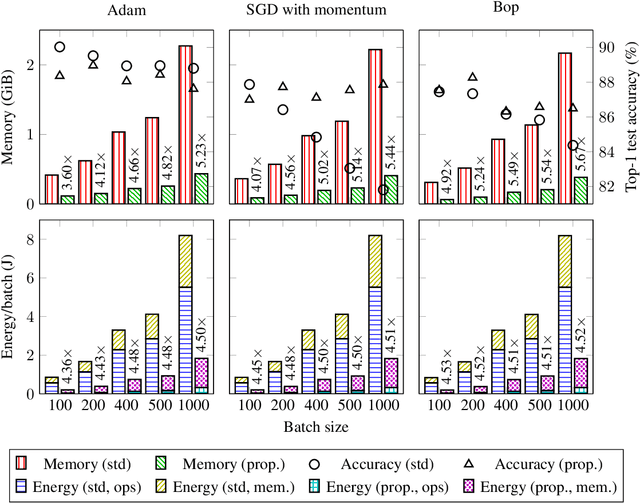
The ever-growing computational demands of increasingly complex machine learning models frequently necessitate the use of powerful cloud-based infrastructure for their training. Binary neural networks are known to be promising candidates for on-device inference due to their extreme compute and memory savings over higher-precision alternatives. In this paper, we demonstrate that they are also strongly robust to gradient quantization, thereby making the training of modern models on the edge a practical reality. We introduce a low-cost binary neural network training strategy exhibiting sizable memory footprint reductions and energy savings vs Courbariaux & Bengio's standard approach. Against the latter, we see coincident memory requirement and energy consumption drops of 2--6$\times$, while reaching similar test accuracy in comparable time, across a range of small-scale models trained to classify popular datasets. We also showcase ImageNet training of ResNetE-18, achieving a 3.12$\times$ memory reduction over the aforementioned standard. Such savings will allow for unnecessary cloud offloading to be avoided, reducing latency, increasing energy efficiency and safeguarding privacy.
Composing and Embedding the Words-as-Classifiers Model of Grounded Semantics
Nov 08, 2019
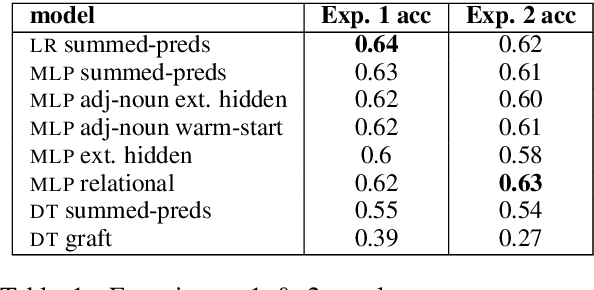


The words-as-classifiers model of grounded lexical semantics learns a semantic fitness score between physical entities and the words that are used to denote those entities. In this paper, we explore how such a model can incrementally perform composition and how the model can be unified with a distributional representation. For the latter, we leverage the classifier coefficients as an embedding. For composition, we leverage the underlying mechanics of three different classifier types (i.e., logistic regression, decision trees, and multi-layer perceptrons) to arrive at a several systematic approaches to composition unique to each classifier including both denotational and connotational methods of composition. We compare these approaches to each other and to prior work in a visual reference resolution task using the refCOCO dataset. Our results demonstrate the need to expand upon existing composition strategies and bring together grounded and distributional representations.