 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposing and Embedding the Words-as-Classifiers Model of Grounded Semantics
Nov 08, 2019
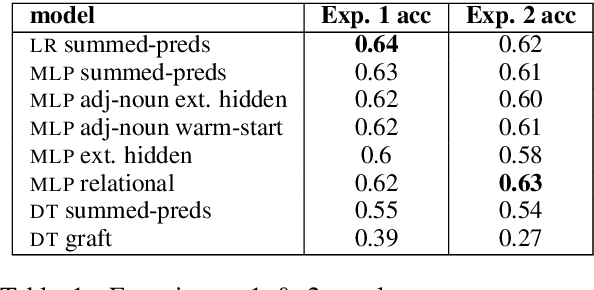


The words-as-classifiers model of grounded lexical semantics learns a semantic fitness score between physical entities and the words that are used to denote those entities. In this paper, we explore how such a model can incrementally perform composition and how the model can be unified with a distributional representation. For the latter, we leverage the classifier coefficients as an embedding. For composition, we leverage the underlying mechanics of three different classifier types (i.e., logistic regression, decision trees, and multi-layer perceptrons) to arrive at a several systematic approaches to composition unique to each classifier including both denotational and connotational methods of composition. We compare these approaches to each other and to prior work in a visual reference resolution task using the refCOCO dataset. Our results demonstrate the need to expand upon existing composition strategies and bring together grounded and distributional representations.