 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFFR: Forward-Forward Learning for Regression
Jun 02, 2026The Forward-Forward (FF) algorithm offers a computationally efficient and biologically plausible alternative to backpropagation (BP) by training neural networks through purely local, layer-wise optimization. However, FF is inherently designed for classification via contrastive positive-negative sample pairs, and extending it to regression poses fundamental challenges: continuous target space lack natural "opposites" for contrastive learning, and the standard goodness function carries no information about target magnitude or ordering. We propose FFR (Forward-Forward for Regression), to our knowledge, the first framework to extend FF to real-world regression and demonstrate competitive performance across diverse real-world datasets. FFR introduces three key innovations: (1) an ordinal competitive goodness function that replaces contrastive pairs with competitive learning between partitioned neuron groups under distance-aware ordinal supervision; (2) a stratified ladder architecture where shallow layers learn coarse ordinal discrimination and deeper layers refine into fine-grained regression, with multi-scale feature aggregation for inter-layer collaboration; and (3) hierarchical prediction with uncertainty estimation, where multi-scale predictors jointly provide robust predictions and prediction confidence as a free-lunch. Extensive experimental results show FFR recovers on average 98.6% of BP's accuracy across five real-world regression benchmarks while reducing peak training memory to only 27% of BP's at depth 8 and 8% at depth 32, with per-iteration time around 72% of BP's, and substantially outperforms all BP-free competitors.
HGQ-LUT: Fast LUT-Aware Training and Efficient Architectures for DNN Inference
Apr 24, 2026Lookup-table (LUT) based neural networks can deliver ultra-low latency and excellent hardware efficiency on FPGAs by mapping arithmetic operations directly onto the logic primitives. However, state-of-the-art LUT-aware training (LAT) approaches remain difficult to use in practice: they are often orders of magnitude slower to train than conventional networks, require non-trivial manual tuning for hardware efficiency, and lack an end-to-end workflow. This work presents HGQ-LUT, integrated in https://github.com/calad0i/HGQ2, a new LAT approach that achieves state-of-the-art hardware efficiency while accelerating training by over 100 times on modern GPUs. HGQ-LUT introduces LUT-Dense and LUT-Conv layers that are implemented with regular, accelerator-efficient tensor operations during training, which are then compiled into logic LUTs for hardware. By combining these layers with fine-grained, element-wise heterogeneous quantization (including zero-bit pruning) and a LUT-aware resource surrogate, HGQ-LUT enables the automatic exploration of accuracy-resource trade-offs without manual bit-width tuning. We further integrate HGQ-LUT into open-source toolchains, enabling unified design, compilation, and bit-exact verification of hybrid architectures that mix LUT-based with conventional arithmetic blocks. These features make LAT-based DNNs practical for real-world deployment, such as at the CERN Large Hadron Collider's experiments.
JetFormer: A Scalable and Efficient Transformer for Jet Tagging from Offline Analysis to FPGA Triggers
Jan 23, 2026We present JetFormer, a versatile and scalable encoder-only Transformer architecture for particle jet tagging at the Large Hadron Collider (LHC). Unlike prior approaches that are often tailored to specific deployment regimes, JetFormer is designed to operate effectively across the full spectrum of jet tagging scenarios, from high-accuracy offline analysis to ultra-low-latency online triggering. The model processes variable-length sets of particle features without relying on input of explicit pairwise interactions, yet achieves competitive or superior performance compared to state-of-the-art methods. On the large-scale JetClass dataset, a large-scale JetFormer matches the accuracy of the interaction-rich ParT model (within 0.7%) while using 37.4% fewer FLOPs, demonstrating its computational efficiency and strong generalization. On benchmark HLS4ML 150P datasets, JetFormer consistently outperforms existing models such as MLPs, Deep Sets, and Interaction Networks by 3-4% in accuracy. To bridge the gap to hardware deployment, we further introduce a hardware-aware optimization pipeline based on multi-objective hyperparameter search, yielding compact variants like JetFormer-tiny suitable for FPGA-based trigger systems with sub-microsecond latency requirements. Through structured pruning and quantization, we show that JetFormer can be aggressively compressed with minimal accuracy loss. By unifying high-performance modeling and deployability within a single architectural framework, JetFormer provides a practical pathway for deploying Transformer-based jet taggers in both offline and online environments at the LHC. Code is available at https://github.com/walkieq/JetFormer.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
MetaML-Pro: Cross-Stage Design Flow Automation for Efficient Deep Learning Acceleration
Feb 09, 2025This paper presents a unified framework for codifying and automating optimization strategies to efficiently deploy deep neural networks (DNNs) on resource-constrained hardware, such as FPGAs, while maintaining high performance, accuracy, and resource efficiency. Deploying DNNs on such platforms involves addressing the significant challenge of balancing performance, resource usage (e.g., DSPs and LUTs), and inference accuracy, which often requires extensive manual effort and domain expertise. Our novel approach addresses two key issues: cross-stage co-optimization and optimization search. By seamlessly integrating programmatic DNN optimization techniques with high-level synthesis (HLS)-based metaprogramming and leveraging advanced design space exploration (DSE) strategies like Bayesian optimization, the framework automates both top-down and bottom-up design flows, reducing the need for manual intervention and domain expertise. The proposed framework introduces customizable optimization, transformation, and control blocks to enhance DNN accelerator performance and resource efficiency. Experimental results demonstrate up to a 92\% DSP and 89\% LUT usage reduction for select networks, while preserving accuracy, along with a 15.6-fold reduction in optimization time compared to grid search. These results underscore the novelty and potential of the proposed framework for automated, resource-efficient DNN accelerator designs.
Sets are all you need: Ultrafast jet classification on FPGAs for HL-LHC
Feb 02, 2024
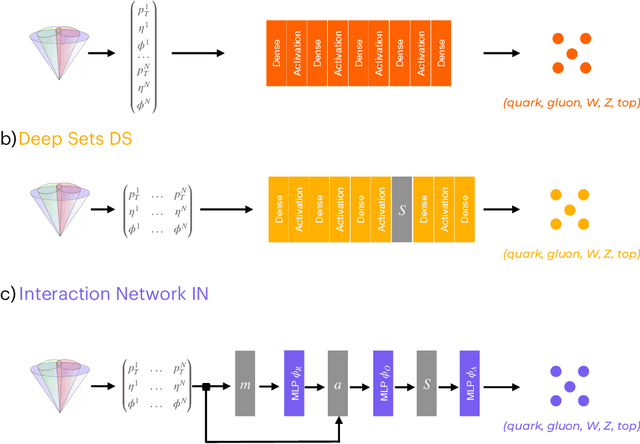
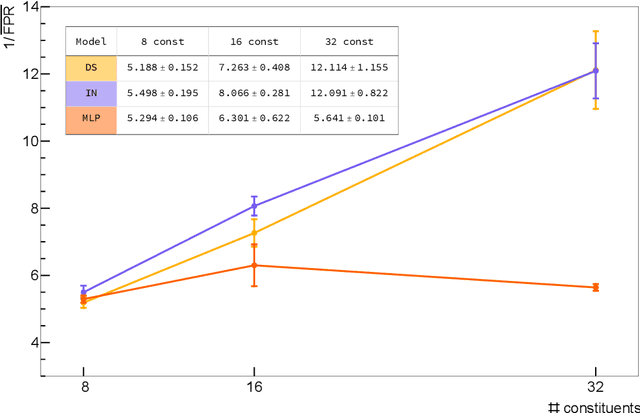

We study various machine learning based algorithms for performing accurate jet flavor classification on field-programmable gate arrays and demonstrate how latency and resource consumption scale with the input size and choice of algorithm. These architectures provide an initial design for models that could be used for tagging at the CERN LHC during its high-luminosity phase. The high-luminosity upgrade will lead to a five-fold increase in its instantaneous luminosity for proton-proton collisions and, in turn, higher data volume and complexity, such as the availability of jet constituents. Through quantization-aware training and efficient hardware implementations, we show that O(100) ns inference of complex architectures such as deep sets and interaction networks is feasible at a low computational resource cost.
When Monte-Carlo Dropout Meets Multi-Exit: Optimizing Bayesian Neural Networks on FPGA
Aug 13, 2023Bayesian Neural Networks (BayesNNs) have demonstrated their capability of providing calibrated prediction for safety-critical applications such as medical imaging and autonomous driving. However, the high algorithmic complexity and the poor hardware performance of BayesNNs hinder their deployment in real-life applications. To bridge this gap, this paper proposes a novel multi-exit Monte-Carlo Dropout (MCD)-based BayesNN that achieves well-calibrated predictions with low algorithmic complexity. To further reduce the barrier to adopting BayesNNs, we propose a transformation framework that can generate FPGA-based accelerators for multi-exit MCD-based BayesNNs. Several novel optimization techniques are introduced to improve hardware performance. Our experiments demonstrate that our auto-generated accelerator achieves higher energy efficiency than CPU, GPU, and other state-of-the-art hardware implementations.
MetaML: Automating Customizable Cross-Stage Design-Flow for Deep Learning Acceleration
Jun 14, 2023This paper introduces a novel optimization framework for deep neural network (DNN) hardware accelerators, enabling the rapid development of customized and automated design flows. More specifically, our approach aims to automate the selection and configuration of low-level optimization techniques, encompassing DNN and FPGA low-level optimizations. We introduce novel optimization and transformation tasks for building design-flow architectures, which are highly customizable and flexible, thereby enhancing the performance and efficiency of DNN accelerators. Our results demonstrate considerable reductions of up to 92\% in DSP usage and 89\% in LUT usage for two networks, while maintaining accuracy and eliminating the need for human effort or domain expertise. In comparison to state-of-the-art approaches, our design achieves higher accuracy and utilizes three times fewer DSP resources, underscoring the advantages of our proposed framework.
LL-GNN: Low Latency Graph Neural Networks on FPGAs for Particle Detectors
Oct 11, 2022
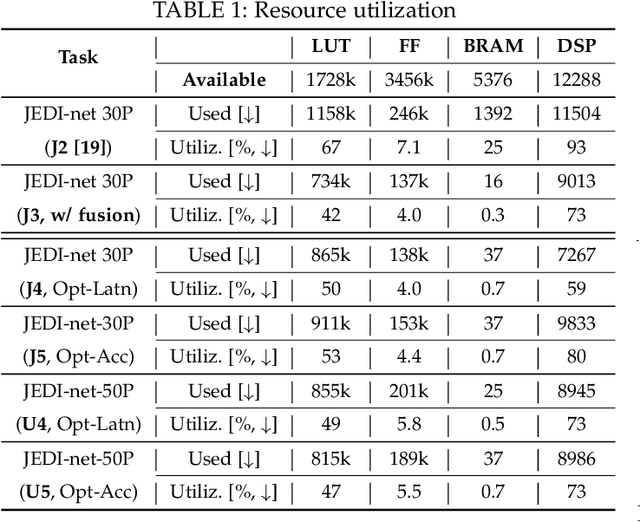
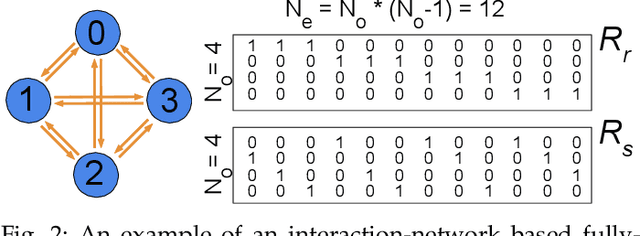
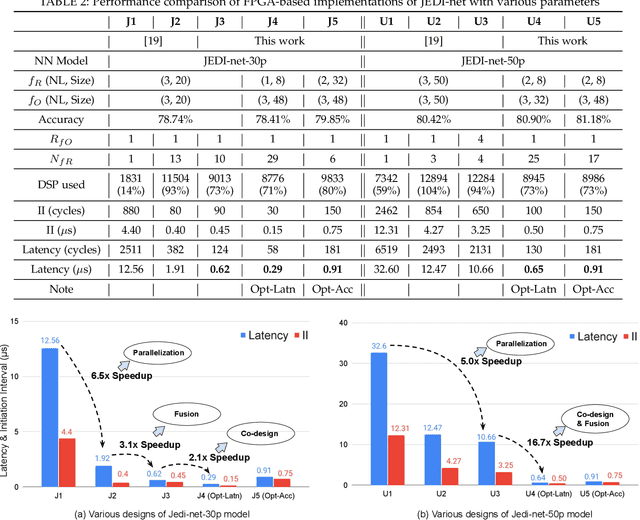
This work proposes a novel reconfigurable architecture for low latency Graph Neural Network (GNN) design specifically for particle detectors. Adopting FPGA-based GNNs for particle detectors is challenging since it requires sub-microsecond latency to deploy the networks for online event selection in the Level-1 triggers for the CERN Large Hadron Collider experiments. This paper proposes a custom code transformation with strength reduction for the matrix multiplication operations in the interaction-network based GNNs with fully connected graphs, which avoids the costly multiplication. It exploits sparsity patterns as well as binary adjacency matrices, and avoids irregular memory access, leading to a reduction in latency and improvement in hardware efficiency. In addition, we introduce an outer-product based matrix multiplication approach which is enhanced by the strength reduction for low latency design. Also, a fusion step is introduced to further reduce the design latency. Furthermore, an GNN-specific algorithm-hardware co-design approach is presented which not only finds a design with a much better latency but also finds a high accuracy design under a given latency constraint. Finally, a customizable template for this low latency GNN hardware architecture has been designed and open-sourced, which enables the generation of low-latency FPGA designs with efficient resource utilization using a high-level synthesis tool. Evaluation results show that our FPGA implementation is up to 24 times faster and consumes up to 45 times less power than a GPU implementation. Compared to our previous FPGA implementations, this work achieves 6.51 to 16.7 times lower latency. Moreover, the latency of our FPGA design is sufficiently low to enable deployment of GNNs in a sub-microsecond, real-time collider trigger system, enabling it to benefit from improved accuracy.
Algorithm and Hardware Co-design for Reconfigurable CNN Accelerator
Nov 24, 2021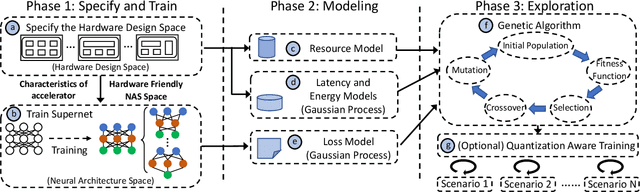
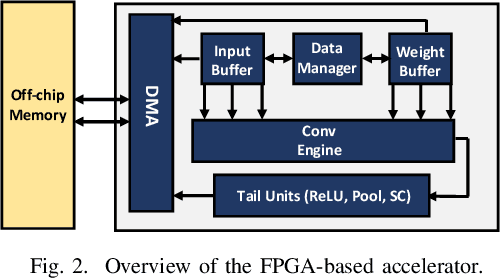
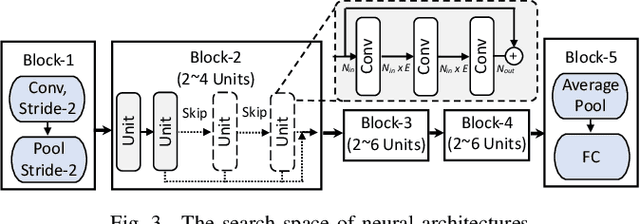
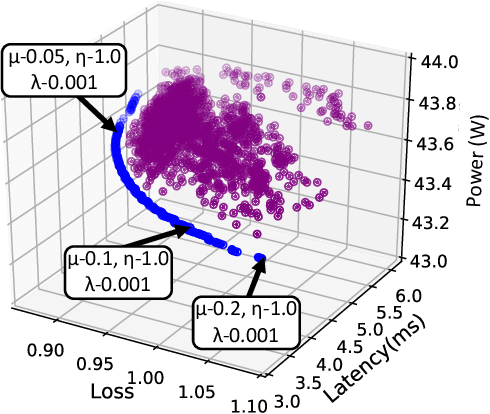
Recent advances in algorithm-hardware co-design for deep neural networks (DNNs) have demonstrated their potential in automatically designing neural architectures and hardware designs. Nevertheless, it is still a challenging optimization problem due to the expensive training cost and the time-consuming hardware implementation, which makes the exploration on the vast design space of neural architecture and hardware design intractable. In this paper, we demonstrate that our proposed approach is capable of locating designs on the Pareto frontier. This capability is enabled by a novel three-phase co-design framework, with the following new features: (a) decoupling DNN training from the design space exploration of hardware architecture and neural architecture, (b) providing a hardware-friendly neural architecture space by considering hardware characteristics in constructing the search cells, (c) adopting Gaussian process to predict accuracy, latency and power consumption to avoid time-consuming synthesis and place-and-route processes. In comparison with the manually-designed ResNet101, InceptionV2 and MobileNetV2, we can achieve up to 5% higher accuracy with up to 3x speed up on the ImageNet dataset. Compared with other state-of-the-art co-design frameworks, our found network and hardware configuration can achieve 2% ~ 6% higher accuracy, 2x ~ 26x smaller latency and 8.5x higher energy efficiency.