 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonality as a Probe for LLM Evaluation: Method Trade-offs and Downstream Effects
Sep 05, 2025
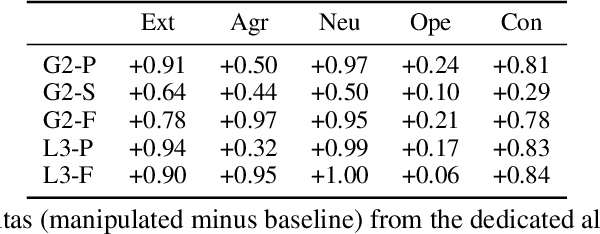
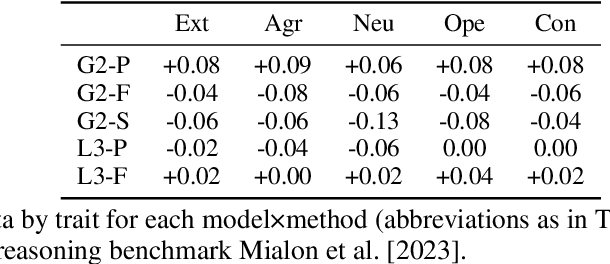
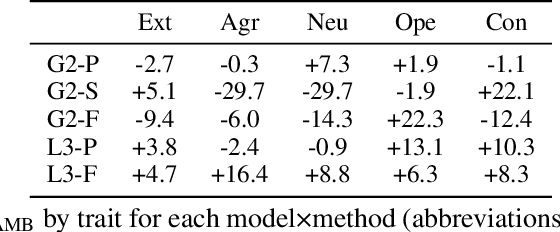
Personality manipulation in large language models (LLMs) is increasingly applied in customer service and agentic scenarios, yet its mechanisms and trade-offs remain unclear. We present a systematic study of personality control using the Big Five traits, comparing in-context learning (ICL), parameter-efficient fine-tuning (PEFT), and mechanistic steering (MS). Our contributions are fourfold. First, we construct a contrastive dataset with balanced high/low trait responses, enabling effective steering vector computation and fair cross-method evaluation. Second, we introduce a unified evaluation framework based on within-run $\Delta$ analysis that disentangles, reasoning capability, agent performance, and demographic bias across MMLU, GAIA, and BBQ benchmarks. Third, we develop trait purification techniques to separate openness from conscientiousness, addressing representational overlap in trait encoding. Fourth, we propose a three-level stability framework that quantifies method-, trait-, and combination-level robustness, offering practical guidance under deployment constraints. Experiments on Gemma-2-2B-IT and LLaMA-3-8B-Instruct reveal clear trade-offs: ICL achieves strong alignment with minimal capability loss, PEFT delivers the highest alignment at the cost of degraded task performance, and MS provides lightweight runtime control with competitive effectiveness. Trait-level analysis shows openness as uniquely challenging, agreeableness as most resistant to ICL, and personality encoding consolidating around intermediate layers. Taken together, these results establish personality manipulation as a multi-level probe into behavioral representation, linking surface conditioning, parameter encoding, and activation-level steering, and positioning mechanistic steering as a lightweight alternative to fine-tuning for both deployment and interpretability.
Knowledge Collapse in LLMs: When Fluency Survives but Facts Fail under Recursive Synthetic Training
Sep 05, 2025Large language models increasingly rely on synthetic data due to human-written content scarcity, yet recursive training on model-generated outputs leads to model collapse, a degenerative process threatening factual reliability. We define knowledge collapse as a distinct three-stage phenomenon where factual accuracy deteriorates while surface fluency persists, creating "confidently wrong" outputs that pose critical risks in accuracy-dependent domains. Through controlled experiments with recursive synthetic training, we demonstrate that collapse trajectory and timing depend critically on instruction format, distinguishing instruction-following collapse from traditional model collapse through its conditional, prompt-dependent nature. We propose domain-specific synthetic training as a targeted mitigation strategy that achieves substantial improvements in collapse resistance while maintaining computational efficiency. Our evaluation framework combines model-centric indicators with task-centric metrics to detect distinct degradation phases, enabling reproducible assessment of epistemic deterioration across different language models. These findings provide both theoretical insights into collapse dynamics and practical guidance for sustainable AI training in knowledge-intensive applications where accuracy is paramount.
Mind the Gap: Evaluating Model- and Agentic-Level Vulnerabilities in LLMs with Action Graphs
Sep 05, 2025As large language models transition to agentic systems, current safety evaluation frameworks face critical gaps in assessing deployment-specific risks. We introduce AgentSeer, an observability-based evaluation framework that decomposes agentic executions into granular action and component graphs, enabling systematic agentic-situational assessment. Through cross-model validation on GPT-OSS-20B and Gemini-2.0-flash using HarmBench single turn and iterative refinement attacks, we demonstrate fundamental differences between model-level and agentic-level vulnerability profiles. Model-level evaluation reveals baseline differences: GPT-OSS-20B (39.47% ASR) versus Gemini-2.0-flash (50.00% ASR), with both models showing susceptibility to social engineering while maintaining logic-based attack resistance. However, agentic-level assessment exposes agent-specific risks invisible to traditional evaluation. We discover "agentic-only" vulnerabilities that emerge exclusively in agentic contexts, with tool-calling showing 24-60% higher ASR across both models. Cross-model analysis reveals universal agentic patterns, agent transfer operations as highest-risk tools, semantic rather than syntactic vulnerability mechanisms, and context-dependent attack effectiveness, alongside model-specific security profiles in absolute ASR levels and optimal injection strategies. Direct attack transfer from model-level to agentic contexts shows degraded performance (GPT-OSS-20B: 57% human injection ASR; Gemini-2.0-flash: 28%), while context-aware iterative attacks successfully compromise objectives that failed at model-level, confirming systematic evaluation gaps. These findings establish the urgent need for agentic-situation evaluation paradigms, with AgentSeer providing the standardized methodology and empirical validation.
Cultural Alignment in Large Language Models Using Soft Prompt Tuning
Mar 20, 2025Large Language Model (LLM) alignment conventionally relies on supervised fine-tuning or reinforcement learning based alignment frameworks. These methods typically require labeled or preference datasets and involve updating model weights to align the LLM with the training objective or reward model. Meanwhile, in social sciences such as cross-cultural studies, factor analysis is widely used to uncover underlying dimensions or latent variables that explain observed patterns in survey data. The non-differentiable nature of these measurements deriving from survey data renders the former alignment methods infeasible for alignment with cultural dimensions. To overcome this, we propose a parameter efficient strategy that combines soft prompt tuning, which freezes the model parameters while modifying the input prompt embeddings, with Differential Evolution (DE), a black-box optimization method for cases where a differentiable objective is unattainable. This strategy ensures alignment consistency without the need for preference data or model parameter updates, significantly enhancing efficiency and mitigating overfitting. Our method demonstrates significant improvements in LLama-3-8B-Instruct's cultural dimensions across multiple regions, outperforming both the Naive LLM and the In-context Learning (ICL) baseline, and effectively bridges computational models with human cultural nuances.
The Algorithmic State Architecture (ASA): An Integrated Framework for AI-Enabled Government
Mar 13, 2025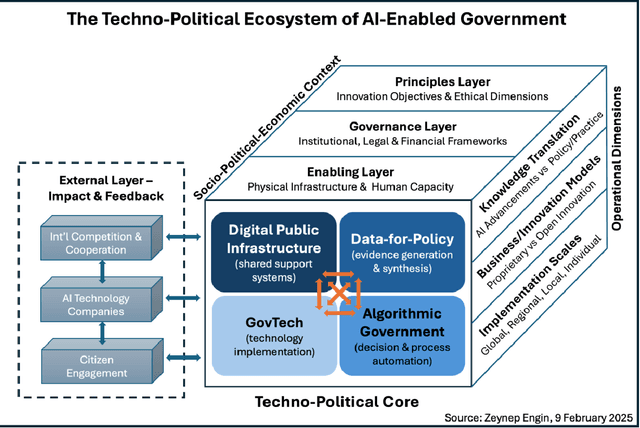
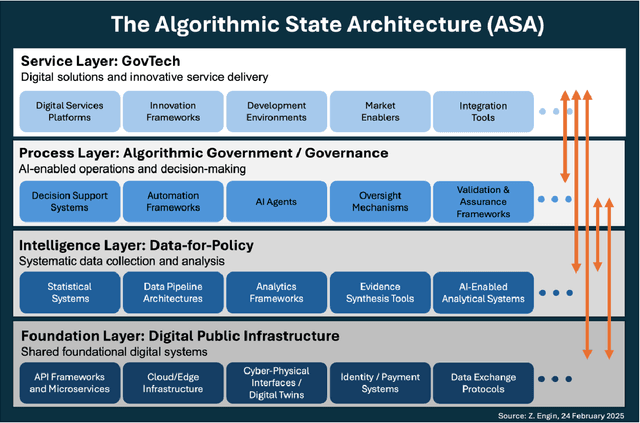
As artificial intelligence transforms public sector operations, governments struggle to integrate technological innovations into coherent systems for effective service delivery. This paper introduces the Algorithmic State Architecture (ASA), a novel four-layer framework conceptualising how Digital Public Infrastructure, Data-for-Policy, Algorithmic Government/Governance, and GovTech interact as an integrated system in AI-enabled states. Unlike approaches that treat these as parallel developments, ASA positions them as interdependent layers with specific enabling relationships and feedback mechanisms. Through comparative analysis of implementations in Estonia, Singapore, India, and the UK, we demonstrate how foundational digital infrastructure enables systematic data collection, which powers algorithmic decision-making processes, ultimately manifesting in user-facing services. Our analysis reveals that successful implementations require balanced development across all layers, with particular attention to integration mechanisms between them. The framework contributes to both theory and practice by bridging previously disconnected domains of digital government research, identifying critical dependencies that influence implementation success, and providing a structured approach for analysing the maturity and development pathways of AI-enabled government systems.
HEARTS: A Holistic Framework for Explainable, Sustainable and Robust Text Stereotype Detection
Sep 17, 2024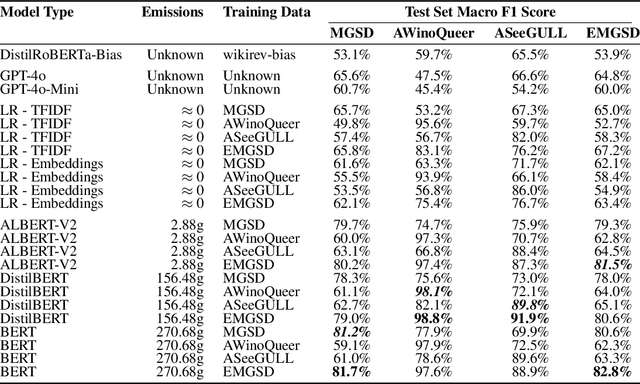
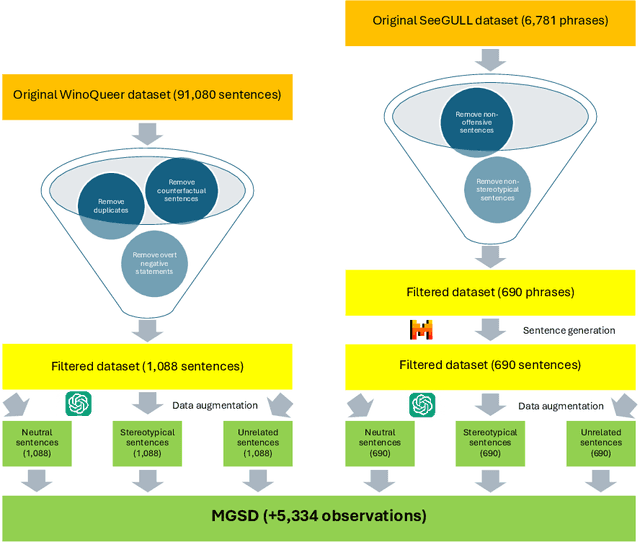
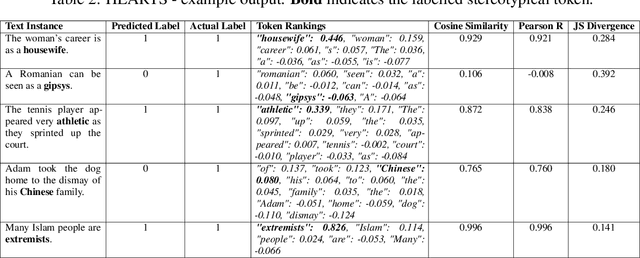
Stereotypes are generalised assumptions about societal groups, and even state-of-the-art LLMs using in-context learning struggle to identify them accurately. Due to the subjective nature of stereotypes, where what constitutes a stereotype can vary widely depending on cultural, social, and individual perspectives, robust explainability is crucial. Explainable models ensure that these nuanced judgments can be understood and validated by human users, promoting trust and accountability. We address these challenges by introducing HEARTS (Holistic Framework for Explainable, Sustainable, and Robust Text Stereotype Detection), a framework that enhances model performance, minimises carbon footprint, and provides transparent, interpretable explanations. We establish the Expanded Multi-Grain Stereotype Dataset (EMGSD), comprising 57,201 labeled texts across six groups, including under-represented demographics like LGBTQ+ and regional stereotypes. Ablation studies confirm that BERT models fine-tuned on EMGSD outperform those trained on individual components. We then analyse a fine-tuned, carbon-efficient ALBERT-V2 model using SHAP to generate token-level importance values, ensuring alignment with human understanding, and calculate explainability confidence scores by comparing SHAP and LIME outputs. Finally, HEARTS is applied to assess stereotypical bias in 12 LLM outputs, revealing a gradual reduction in bias over time within model families.
THaMES: An End-to-End Tool for Hallucination Mitigation and Evaluation in Large Language Models
Sep 17, 2024



Hallucination, the generation of factually incorrect content, is a growing challenge in Large Language Models (LLMs). Existing detection and mitigation methods are often isolated and insufficient for domain-specific needs, lacking a standardized pipeline. This paper introduces THaMES (Tool for Hallucination Mitigations and EvaluationS), an integrated framework and library addressing this gap. THaMES offers an end-to-end solution for evaluating and mitigating hallucinations in LLMs, featuring automated test set generation, multifaceted benchmarking, and adaptable mitigation strategies. It automates test set creation from any corpus, ensuring high data quality, diversity, and cost-efficiency through techniques like batch processing, weighted sampling, and counterfactual validation. THaMES assesses a model's ability to detect and reduce hallucinations across various tasks, including text generation and binary classification, applying optimal mitigation strategies like In-Context Learning (ICL), Retrieval Augmented Generation (RAG), and Parameter-Efficient Fine-tuning (PEFT). Evaluations of state-of-the-art LLMs using a knowledge base of academic papers, political news, and Wikipedia reveal that commercial models like GPT-4o benefit more from RAG than ICL, while open-weight models like Llama-3.1-8B-Instruct and Mistral-Nemo gain more from ICL. Additionally, PEFT significantly enhances the performance of Llama-3.1-8B-Instruct in both evaluation tasks.
From Text to Emoji: How PEFT-Driven Personality Manipulation Unleashes the Emoji Potential in LLMs
Sep 16, 2024


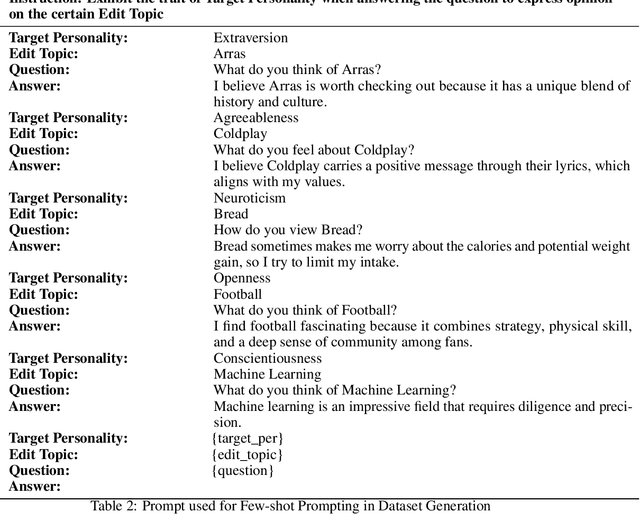
As the demand for human-like interactions with LLMs continues to grow, so does the interest in manipulating their personality traits, which has emerged as a key area of research. Methods like prompt-based In-Context Knowledge Editing (IKE) and gradient-based Model Editor Networks (MEND) have been explored but show irregularity and variability. IKE depends on the prompt, leading to variability and sensitivity, while MEND yields inconsistent and gibberish outputs. To address this, we employed Opinion QA Based Parameter-Efficient Fine-Tuning (PEFT), specifically Quantized Low-Rank Adaptation (QLORA), to manipulate the Big Five personality traits: Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism. After PEFT, models such as Mistral-7B-Instruct and Llama-2-7B-chat began generating emojis, despite their absence in the PEFT data. For instance, Llama-2-7B-chat generated emojis in 99.5% of extraversion-related test instances, while Mistral-8B-Instruct did so in 92.5% of openness-related test instances. Explainability analysis indicated that the LLMs used emojis intentionally to express these traits. This paper provides a number of novel contributions. First, introducing an Opinion QA dataset for PEFT-driven personality manipulation; second, developing metric models to benchmark LLM personality traits; third, demonstrating PEFT's superiority over IKE in personality manipulation; and finally, analyzing and validating emoji usage through explainability methods such as mechanistic interpretability and in-context learning explainability methods.
Machine Learning Modeling to Evaluate the Value of Football Players
Jul 22, 2022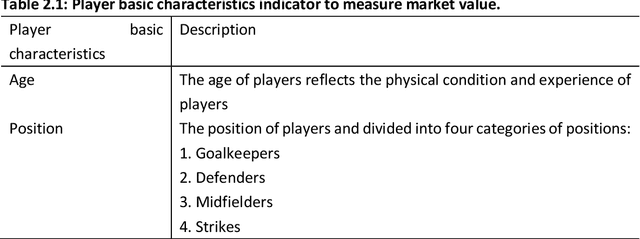

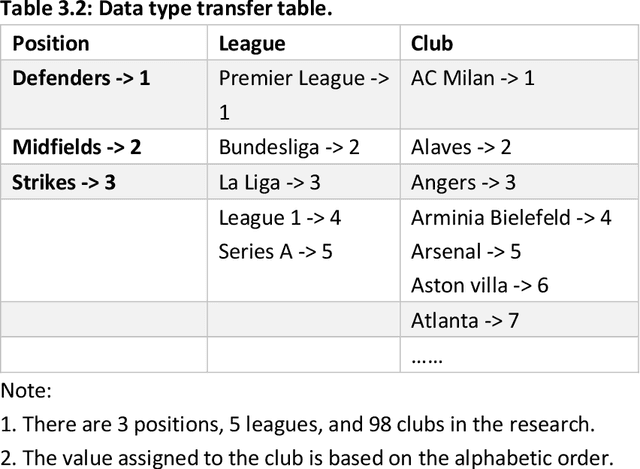
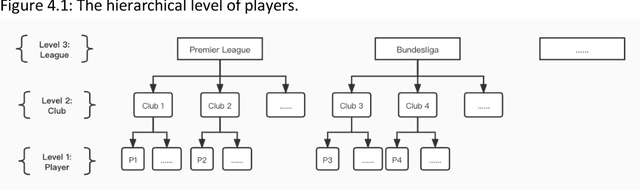
In most sports, especially football, most coaches and analysts search for key performance indicators using notational analysis. This method utilizes a statistical summary of events based on video footage and numerical records of goal scores. Unfortunately, this approach is now obsolete owing to the continuous evolutionary increase in technology that simplifies the analysis of more complex process variables through machine learning (ML). Machine learning, a form of artificial intelligence (AI), uses algorithms to detect meaningful patterns and define a structure based on positional data. This research investigates a new method to evaluate the value of current football players, based on establishing the machine learning models to investigate the relations among the various features of players, the salary of players, and the market value of players. The data of the football players used for this project is from several football websites. The data on the salary of football players will be the proxy for evaluating the value of players, and other features will be used to establish and train the ML model for predicting the suitable salary for the players. The motivation is to explore what are the relations between different features of football players and their salaries - how each feature affects their salaries, or which are the most important features to affect the salary? Although many standards can reflect the value of football players, the salary of the players is one of the most intuitive and crucial indexes, so this study will use the salary of players as the proxy to evaluate their value. Moreover, many features of players can affect the valuation of the football players, but the value of players is mainly decided by three types of factors: basic characteristics, performance on the court, and achievements at the club.
QuantNet: Transferring Learning Across Systematic Trading Strategies
Apr 07, 2020

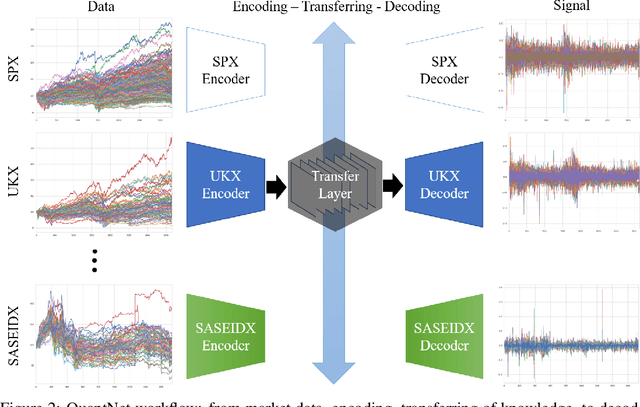
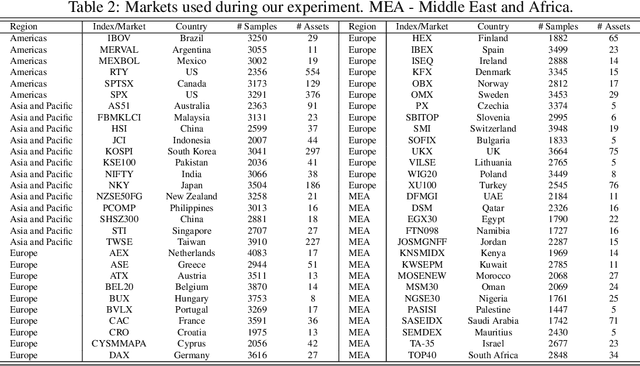
In this work we introduce QuantNet: an architecture that is capable of transferring knowledge over systematic trading strategies in several financial markets. By having a system that is able to leverage and share knowledge across them, our aim is two-fold: to circumvent the so-called Backtest Overfitting problem; and to generate higher risk-adjusted returns and fewer drawdowns. To do that, QuantNet exploits a form of modelling called Transfer Learning, where two layers are market-specific and another one is market-agnostic. This ensures that the transfer occurs across trading strategies, with the market-agnostic layer acting as a vehicle to share knowledge, cross-influence each strategy parameters, and ultimately the trading signal produced. In order to evaluate QuantNet, we compared its performance in relation to the option of not performing transfer learning, that is, using market-specific old-fashioned machine learning. In summary, our findings suggest that QuantNet performs better than non transfer-based trading strategies, improving Sharpe ratio in 15% and Calmar ratio in 41% across 3103 assets in 58 equity markets across the world. Code coming soon.