 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Modeling to Evaluate the Value of Football Players
Jul 22, 2022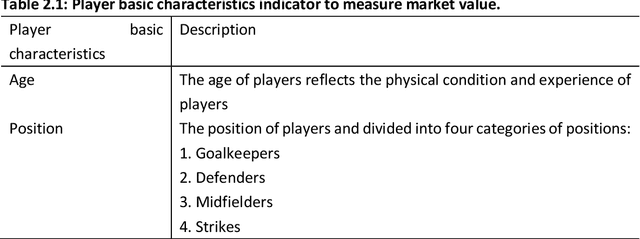

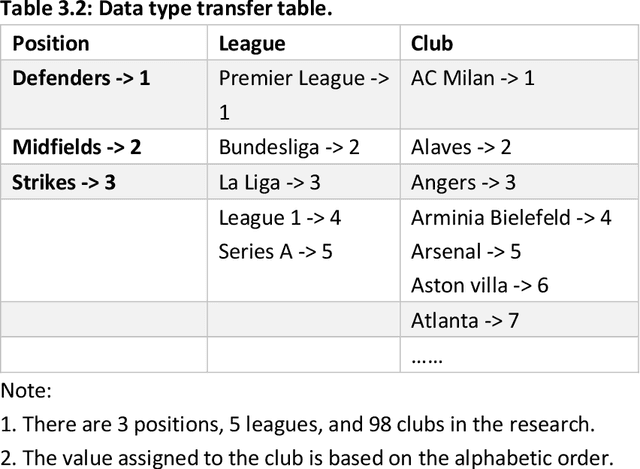
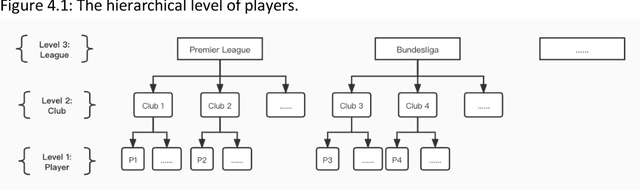
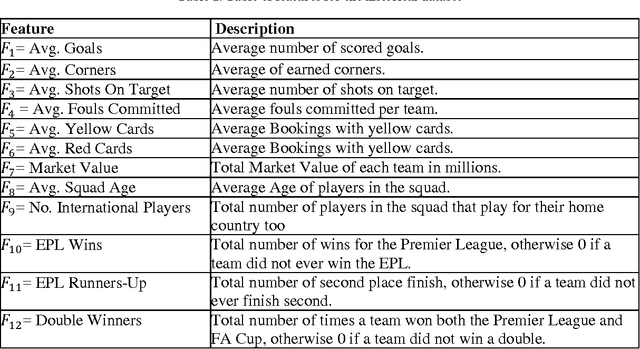
In most sports, especially football, most coaches and analysts search for key performance indicators using notational analysis. This method utilizes a statistical summary of events based on video footage and numerical records of goal scores. Unfortunately, this approach is now obsolete owing to the continuous evolutionary increase in technology that simplifies the analysis of more complex process variables through machine learning (ML). Machine learning, a form of artificial intelligence (AI), uses algorithms to detect meaningful patterns and define a structure based on positional data. This research investigates a new method to evaluate the value of current football players, based on establishing the machine learning models to investigate the relations among the various features of players, the salary of players, and the market value of players. The data of the football players used for this project is from several football websites. The data on the salary of football players will be the proxy for evaluating the value of players, and other features will be used to establish and train the ML model for predicting the suitable salary for the players. The motivation is to explore what are the relations between different features of football players and their salaries - how each feature affects their salaries, or which are the most important features to affect the salary? Although many standards can reflect the value of football players, the salary of the players is one of the most intuitive and crucial indexes, so this study will use the salary of players as the proxy to evaluate their value. Moreover, many features of players can affect the valuation of the football players, but the value of players is mainly decided by three types of factors: basic characteristics, performance on the court, and achievements at the club.
Predictive modelling of football injuries
Sep 20, 2016
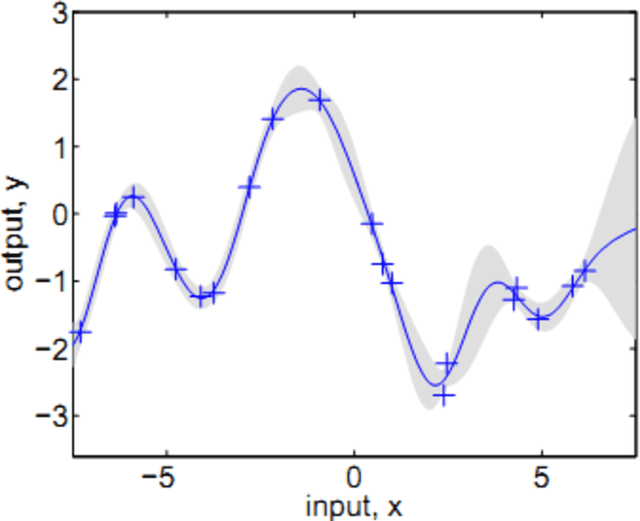
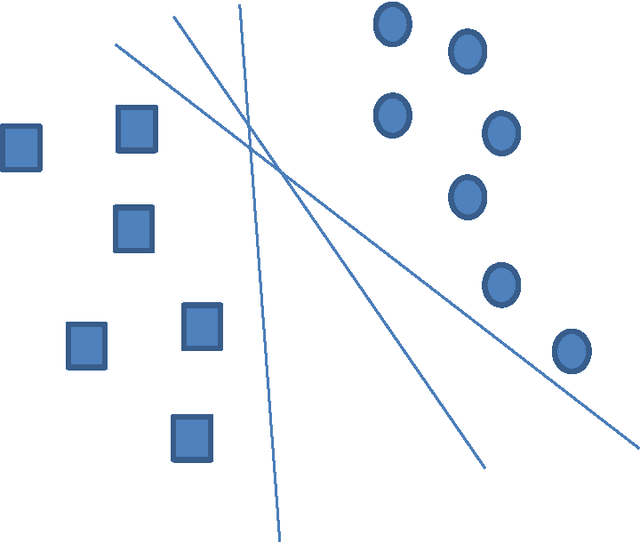
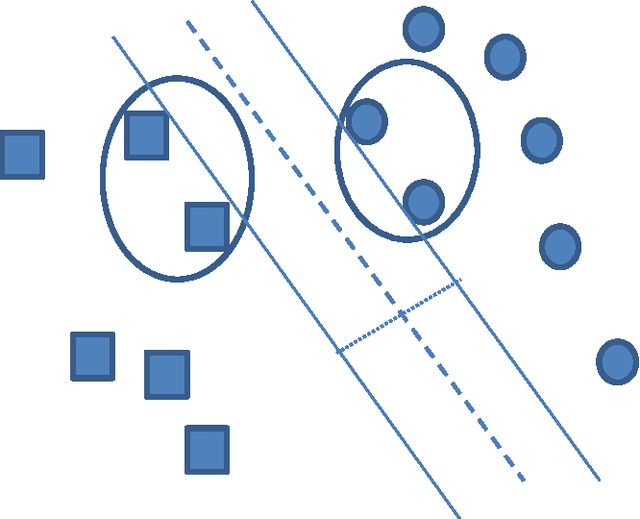
The goal of this thesis is to investigate the potential of predictive modelling for football injuries. This work was conducted in close collaboration with Tottenham Hotspurs FC (THFC), the PGA European tour and the participation of Wolverhampton Wanderers (WW). Three investigations were conducted: 1. Predicting the recovery time of football injuries using the UEFA injury recordings: The UEFA recordings is a common standard for recording injuries in professional football. For this investigation, three datasets of UEFA injury recordings were available. Different machine learning algorithms were used in order to build a predictive model. The performance of the machine learning models is then improved by using feature selection conducted through correlation-based subset feature selection and random forests. 2. Predicting injuries in professional football using exposure records: The relationship between exposure (in training hours and match hours) in professional football athletes and injury incidence was studied. A common problem in football is understanding how the training schedule of an athlete can affect the chance of him getting injured. The task was to predict the number of days a player can train before he gets injured. 3. Predicting intrinsic injury incidence using in-training GPS measurements: A significant percentage of football injuries can be attributed to overtraining and fatigue. GPS data collected during training sessions might provide indicators of fatigue, or might be used to detect very intense training sessions which can lead to overtraining. This research used GPS data gathered during training sessions of the first team of THFC, in order to predict whether an injury would take place during a week.
Using Machine Learning to Predict the Outcome of English County twenty over Cricket Matches
Nov 18, 2015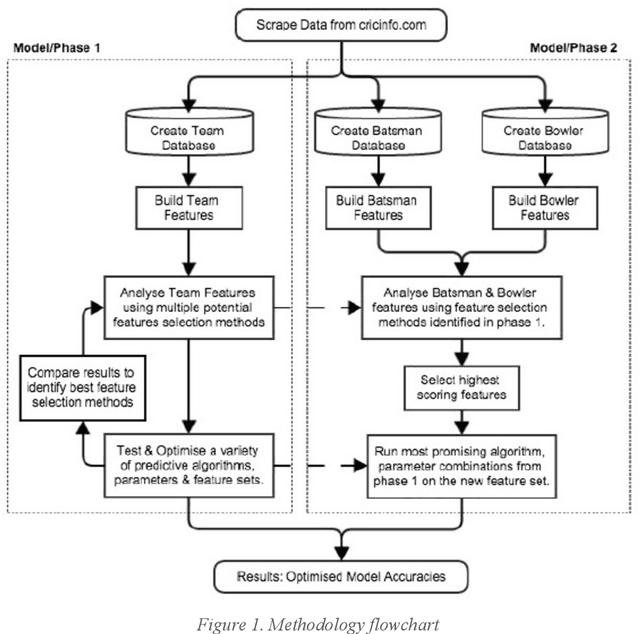
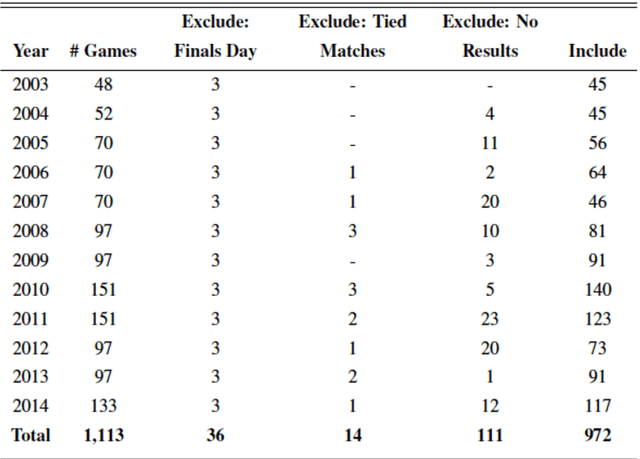
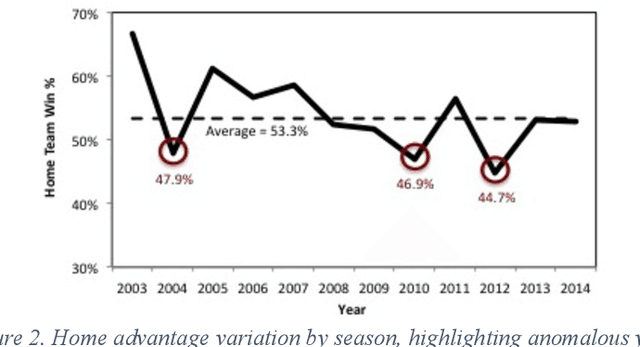
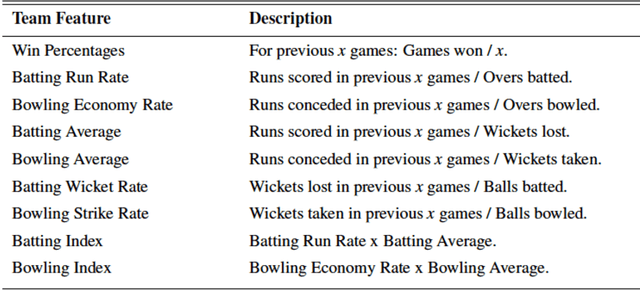
Cricket betting is a multi-billion dollar market. Therefore, there is a strong incentive for models that can predict the outcomes of games and beat the odds provided by bookers. The aim of this study was to investigate to what degree it is possible to predict the outcome of cricket matches. The target competition was the English twenty over county cricket cup. The original features alongside engineered features gave rise to more than 500 team and player statistics. The models were optimized firstly with team features only and then both team and player features. The performance of the models was tested over individual seasons from 2009 to 2014 having been trained over previous season data in each case. The optimal model was a simple prediction method combined with complex hierarchical features and was shown to significantly outperform a gambling industry benchmark.
Using Twitter to predict football outcomes
Nov 05, 2014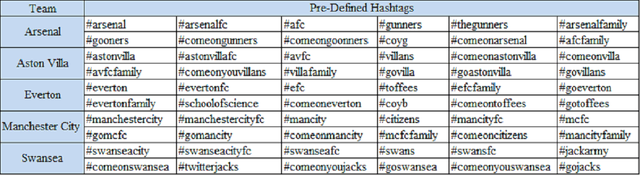
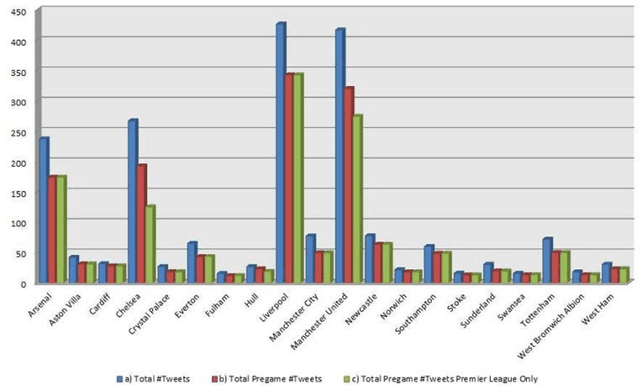
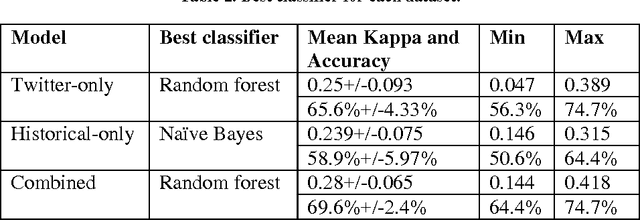
Twitter has been proven to be a notable source for predictive modelling on various domains such as the stock market, the dissemination of diseases or sports outcomes. However, such a study has not been conducted in football (soccer) so far. The purpose of this research was to study whether data mined from Twitter can be used for this purpose. We built a set of predictive models for the outcome of football games of the English Premier League for a 3 month period based on tweets and we studied whether these models can overcome predictive models which use only historical data and simple football statistics. Moreover, combined models are constructed using both Twitter and historical data. The final results indicate that data mined from Twitter can indeed be a useful source for predicting games in the Premier League. The final Twitter-based model performs significantly better than chance when measured by Cohen's kappa and is comparable to the model that uses simple statistics and historical data. Combining both models raises the performance higher than it was achieved by each individual model. Thereby, this study provides evidence that Twitter derived features can indeed provide useful information for the prediction of football (soccer) outcomes.