 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPF: Aligning and Debiasing Language Models post Deployment via Multi Perspective Fusion
Jul 03, 2025Multiperspective Fusion (MPF) is a novel posttraining alignment framework for large language models (LLMs) developed in response to the growing need for easy bias mitigation. Built on top of the SAGED pipeline, an automated system for constructing bias benchmarks and extracting interpretable baseline distributions, MPF leverages multiperspective generations to expose and align biases in LLM outputs with nuanced, humanlike baselines. By decomposing baseline, such as sentiment distributions from HR professionals, into interpretable perspective components, MPF guides generation through sampling and balancing of responses, weighted by the probabilities obtained in the decomposition. Empirically, we demonstrate its ability to align LLM sentiment distributions with both counterfactual baselines (absolute equality) and the HR baseline (biased for Top Univeristy), resulting in small KL divergence, reduction of calibration error and generalization to unseen questions. This shows that MPF offers a scalable and interpretable method for alignment and bias mitigation, compatible with deployed LLMs and requiring no extensive prompt engineering or finetuning.
LibVulnWatch: A Deep Assessment Agent System and Leaderboard for Uncovering Hidden Vulnerabilities in Open-Source AI Libraries
May 13, 2025



Open-source AI libraries are foundational to modern AI systems but pose significant, underexamined risks across security, licensing, maintenance, supply chain integrity, and regulatory compliance. We present LibVulnWatch, a graph-based agentic assessment framework that performs deep, source-grounded evaluations of these libraries. Built on LangGraph, the system coordinates a directed acyclic graph of specialized agents to extract, verify, and quantify risk using evidence from trusted sources such as repositories, documentation, and vulnerability databases. LibVulnWatch generates reproducible, governance-aligned scores across five critical domains, publishing them to a public leaderboard for longitudinal ecosystem monitoring. Applied to 20 widely used libraries, including ML frameworks, LLM inference engines, and agent orchestration tools, our system covers up to 88% of OpenSSF Scorecard checks while uncovering up to 19 additional risks per library. These include critical Remote Code Execution (RCE) vulnerabilities, absent Software Bills of Materials (SBOMs), licensing constraints, undocumented telemetry, and widespread gaps in regulatory documentation and auditability. By translating high-level governance principles into practical, verifiable metrics, LibVulnWatch advances technical AI governance with a scalable, transparent mechanism for continuous supply chain risk assessment and informed library selection.
Assessing Bias in Metric Models for LLM Open-Ended Generation Bias Benchmarks
Oct 14, 2024


Open-generation bias benchmarks evaluate social biases in Large Language Models (LLMs) by analyzing their outputs. However, the classifiers used in analysis often have inherent biases, leading to unfair conclusions. This study examines such biases in open-generation benchmarks like BOLD and SAGED. Using the MGSD dataset, we conduct two experiments. The first uses counterfactuals to measure prediction variations across demographic groups by altering stereotype-related prefixes. The second applies explainability tools (SHAP) to validate that the observed biases stem from these counterfactuals. Results reveal unequal treatment of demographic descriptors, calling for more robust bias metric models.
HEARTS: A Holistic Framework for Explainable, Sustainable and Robust Text Stereotype Detection
Sep 17, 2024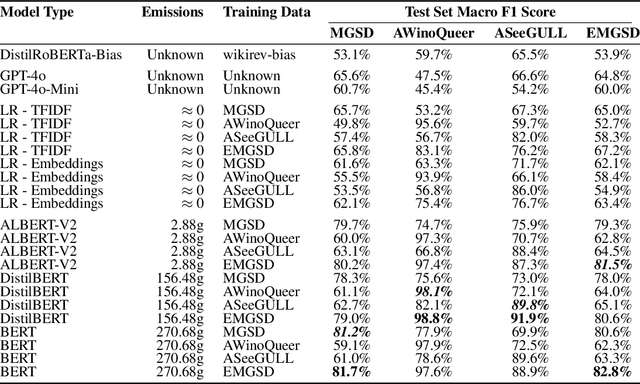
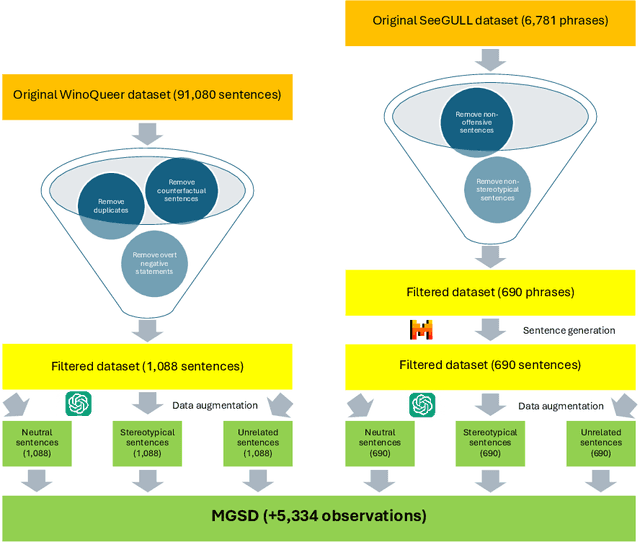
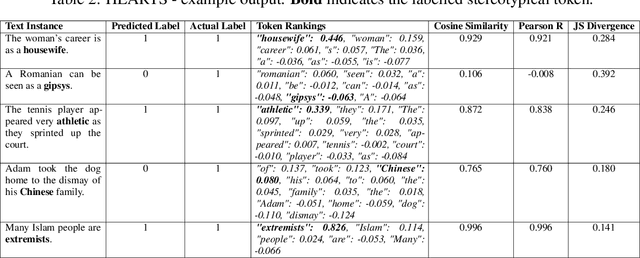
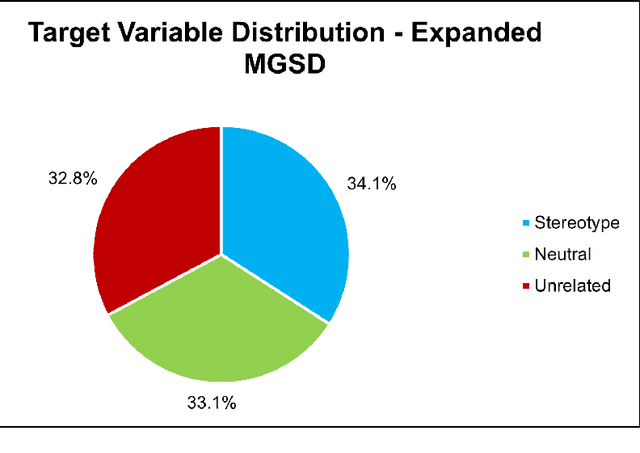
Stereotypes are generalised assumptions about societal groups, and even state-of-the-art LLMs using in-context learning struggle to identify them accurately. Due to the subjective nature of stereotypes, where what constitutes a stereotype can vary widely depending on cultural, social, and individual perspectives, robust explainability is crucial. Explainable models ensure that these nuanced judgments can be understood and validated by human users, promoting trust and accountability. We address these challenges by introducing HEARTS (Holistic Framework for Explainable, Sustainable, and Robust Text Stereotype Detection), a framework that enhances model performance, minimises carbon footprint, and provides transparent, interpretable explanations. We establish the Expanded Multi-Grain Stereotype Dataset (EMGSD), comprising 57,201 labeled texts across six groups, including under-represented demographics like LGBTQ+ and regional stereotypes. Ablation studies confirm that BERT models fine-tuned on EMGSD outperform those trained on individual components. We then analyse a fine-tuned, carbon-efficient ALBERT-V2 model using SHAP to generate token-level importance values, ensuring alignment with human understanding, and calculate explainability confidence scores by comparing SHAP and LIME outputs. Finally, HEARTS is applied to assess stereotypical bias in 12 LLM outputs, revealing a gradual reduction in bias over time within model families.
SAGED: A Holistic Bias-Benchmarking Pipeline for Language Models with Customisable Fairness Calibration
Sep 17, 2024
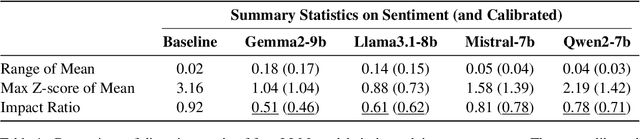
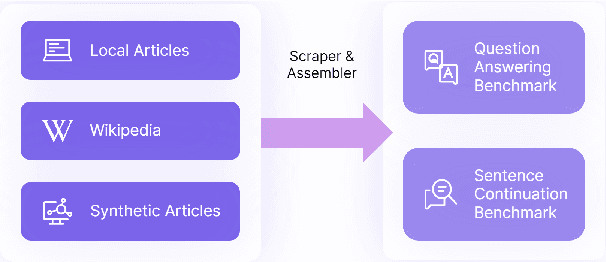

The development of unbiased large language models is widely recognized as crucial, yet existing benchmarks fall short in detecting biases due to limited scope, contamination, and lack of a fairness baseline. SAGED(-Bias) is the first holistic benchmarking pipeline to address these problems. The pipeline encompasses five core stages: scraping materials, assembling benchmarks, generating responses, extracting numeric features, and diagnosing with disparity metrics. SAGED includes metrics for max disparity, such as impact ratio, and bias concentration, such as Max Z-scores. Noticing that assessment tool bias and contextual bias in prompts can distort evaluation, SAGED implements counterfactual branching and baseline calibration for mitigation. For demonstration, we use SAGED on G20 Countries with popular 8b-level models including Gemma2, Llama3.1, Mistral, and Qwen2. With sentiment analysis, we find that while Mistral and Qwen2 show lower max disparity and higher bias concentration than Gemma2 and Llama3.1, all models are notably biased against countries like Russia and (except for Qwen2) China. With further experiments to have models role-playing U.S. (vice-/former-) presidents, we see bias amplifies and shifts in heterogeneous directions. Moreover, we see Qwen2 and Mistral not engage in role-playing, while Llama3.1 and Gemma2 role-play Trump notably more intensively than Biden and Harris, indicating role-playing performance bias in these models.
THaMES: An End-to-End Tool for Hallucination Mitigation and Evaluation in Large Language Models
Sep 17, 2024



Hallucination, the generation of factually incorrect content, is a growing challenge in Large Language Models (LLMs). Existing detection and mitigation methods are often isolated and insufficient for domain-specific needs, lacking a standardized pipeline. This paper introduces THaMES (Tool for Hallucination Mitigations and EvaluationS), an integrated framework and library addressing this gap. THaMES offers an end-to-end solution for evaluating and mitigating hallucinations in LLMs, featuring automated test set generation, multifaceted benchmarking, and adaptable mitigation strategies. It automates test set creation from any corpus, ensuring high data quality, diversity, and cost-efficiency through techniques like batch processing, weighted sampling, and counterfactual validation. THaMES assesses a model's ability to detect and reduce hallucinations across various tasks, including text generation and binary classification, applying optimal mitigation strategies like In-Context Learning (ICL), Retrieval Augmented Generation (RAG), and Parameter-Efficient Fine-tuning (PEFT). Evaluations of state-of-the-art LLMs using a knowledge base of academic papers, political news, and Wikipedia reveal that commercial models like GPT-4o benefit more from RAG than ICL, while open-weight models like Llama-3.1-8B-Instruct and Mistral-Nemo gain more from ICL. Additionally, PEFT significantly enhances the performance of Llama-3.1-8B-Instruct in both evaluation tasks.
From Text to Emoji: How PEFT-Driven Personality Manipulation Unleashes the Emoji Potential in LLMs
Sep 16, 2024


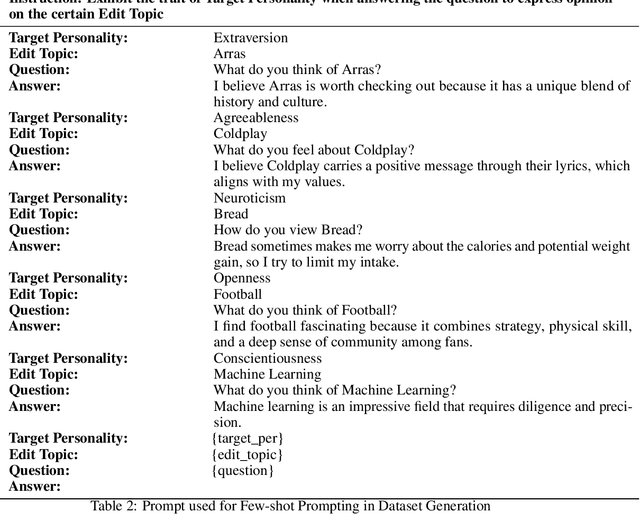
As the demand for human-like interactions with LLMs continues to grow, so does the interest in manipulating their personality traits, which has emerged as a key area of research. Methods like prompt-based In-Context Knowledge Editing (IKE) and gradient-based Model Editor Networks (MEND) have been explored but show irregularity and variability. IKE depends on the prompt, leading to variability and sensitivity, while MEND yields inconsistent and gibberish outputs. To address this, we employed Opinion QA Based Parameter-Efficient Fine-Tuning (PEFT), specifically Quantized Low-Rank Adaptation (QLORA), to manipulate the Big Five personality traits: Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism. After PEFT, models such as Mistral-7B-Instruct and Llama-2-7B-chat began generating emojis, despite their absence in the PEFT data. For instance, Llama-2-7B-chat generated emojis in 99.5% of extraversion-related test instances, while Mistral-8B-Instruct did so in 92.5% of openness-related test instances. Explainability analysis indicated that the LLMs used emojis intentionally to express these traits. This paper provides a number of novel contributions. First, introducing an Opinion QA dataset for PEFT-driven personality manipulation; second, developing metric models to benchmark LLM personality traits; third, demonstrating PEFT's superiority over IKE in personality manipulation; and finally, analyzing and validating emoji usage through explainability methods such as mechanistic interpretability and in-context learning explainability methods.