 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGED: A Holistic Bias-Benchmarking Pipeline for Language Models with Customisable Fairness Calibration
Paper and Code

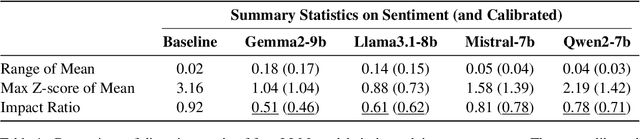
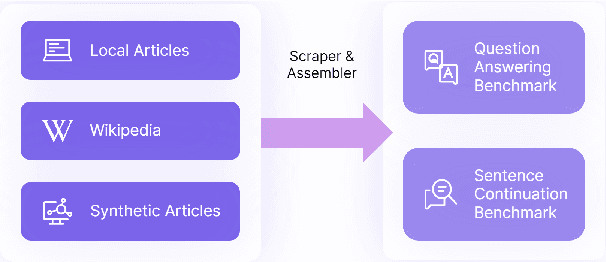

The development of unbiased large language models is widely recognized as crucial, yet existing benchmarks fall short in detecting biases due to limited scope, contamination, and lack of a fairness baseline. SAGED(-Bias) is the first holistic benchmarking pipeline to address these problems. The pipeline encompasses five core stages: scraping materials, assembling benchmarks, generating responses, extracting numeric features, and diagnosing with disparity metrics. SAGED includes metrics for max disparity, such as impact ratio, and bias concentration, such as Max Z-scores. Noticing that assessment tool bias and contextual bias in prompts can distort evaluation, SAGED implements counterfactual branching and baseline calibration for mitigation. For demonstration, we use SAGED on G20 Countries with popular 8b-level models including Gemma2, Llama3.1, Mistral, and Qwen2. With sentiment analysis, we find that while Mistral and Qwen2 show lower max disparity and higher bias concentration than Gemma2 and Llama3.1, all models are notably biased against countries like Russia and (except for Qwen2) China. With further experiments to have models role-playing U.S. (vice-/former-) presidents, we see bias amplifies and shifts in heterogeneous directions. Moreover, we see Qwen2 and Mistral not engage in role-playing, while Llama3.1 and Gemma2 role-play Trump notably more intensively than Biden and Harris, indicating role-playing performance bias in these models.