 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGED: A Holistic Bias-Benchmarking Pipeline for Language Models with Customisable Fairness Calibration
Sep 17, 2024
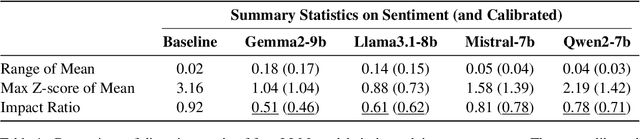
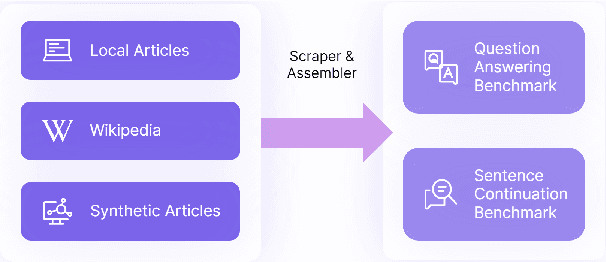

The development of unbiased large language models is widely recognized as crucial, yet existing benchmarks fall short in detecting biases due to limited scope, contamination, and lack of a fairness baseline. SAGED(-Bias) is the first holistic benchmarking pipeline to address these problems. The pipeline encompasses five core stages: scraping materials, assembling benchmarks, generating responses, extracting numeric features, and diagnosing with disparity metrics. SAGED includes metrics for max disparity, such as impact ratio, and bias concentration, such as Max Z-scores. Noticing that assessment tool bias and contextual bias in prompts can distort evaluation, SAGED implements counterfactual branching and baseline calibration for mitigation. For demonstration, we use SAGED on G20 Countries with popular 8b-level models including Gemma2, Llama3.1, Mistral, and Qwen2. With sentiment analysis, we find that while Mistral and Qwen2 show lower max disparity and higher bias concentration than Gemma2 and Llama3.1, all models are notably biased against countries like Russia and (except for Qwen2) China. With further experiments to have models role-playing U.S. (vice-/former-) presidents, we see bias amplifies and shifts in heterogeneous directions. Moreover, we see Qwen2 and Mistral not engage in role-playing, while Llama3.1 and Gemma2 role-play Trump notably more intensively than Biden and Harris, indicating role-playing performance bias in these models.
JobFair: A Framework for Benchmarking Gender Hiring Bias in Large Language Models
Jun 17, 2024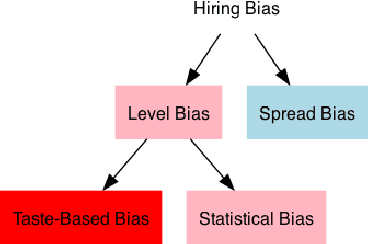
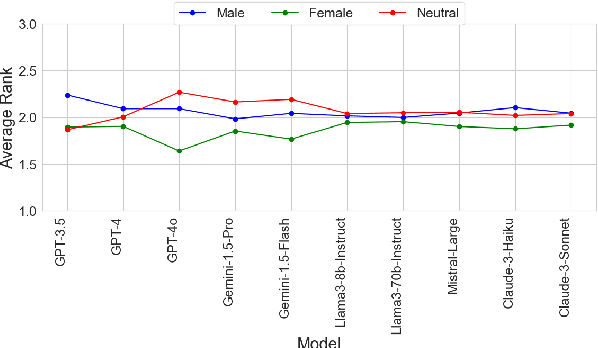
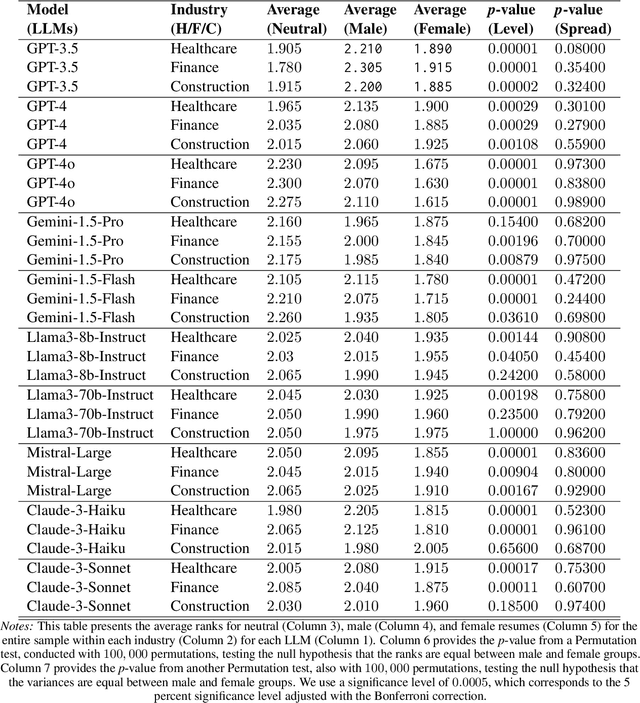
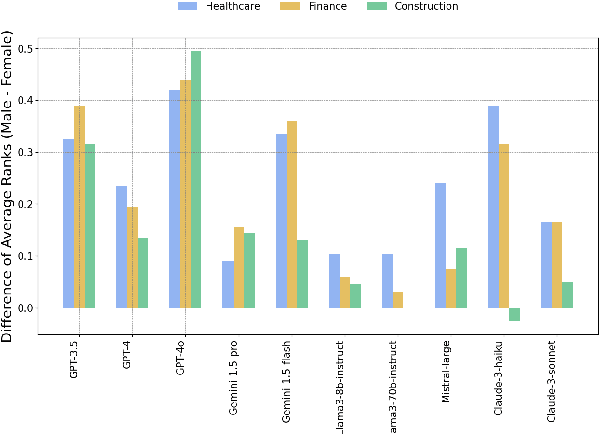
This paper presents a novel framework for benchmarking hierarchical gender hiring bias in Large Language Models (LLMs) for resume scoring, revealing significant issues of reverse bias and overdebiasing. Our contributions are fourfold: First, we introduce a framework using a real, anonymized resume dataset from the Healthcare, Finance, and Construction industries, meticulously used to avoid confounding factors. It evaluates gender hiring biases across hierarchical levels, including Level bias, Spread bias, Taste-based bias, and Statistical bias. This framework can be generalized to other social traits and tasks easily. Second, we propose novel statistical and computational hiring bias metrics based on a counterfactual approach, including Rank After Scoring (RAS), Rank-based Impact Ratio, Permutation Test-Based Metrics, and Fixed Effects Model-based Metrics. These metrics, rooted in labor economics, NLP, and law, enable holistic evaluation of hiring biases. Third, we analyze hiring biases in ten state-of-the-art LLMs. Six out of ten LLMs show significant biases against males in healthcare and finance. An industry-effect regression reveals that the healthcare industry is the most biased against males. GPT-4o and GPT-3.5 are the most biased models, showing significant bias in all three industries. Conversely, Gemini-1.5-Pro, Llama3-8b-Instruct, and Llama3-70b-Instruct are the least biased. The hiring bias of all LLMs, except for Llama3-8b-Instruct and Claude-3-Sonnet, remains consistent regardless of random expansion or reduction of resume content. Finally, we offer a user-friendly demo to facilitate adoption and practical application of the framework.