 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Diverse Negations from Affirmative Sentences
Oct 30, 2024Despite the impressive performance of large language models across various tasks, they often struggle with reasoning under negated statements. Negations are important in real-world applications as they encode negative polarity in verb phrases, clauses, or other expressions. Nevertheless, they are underrepresented in current benchmarks, which mainly include basic negation forms and overlook more complex ones, resulting in insufficient data for training a language model. In this work, we propose NegVerse, a method that tackles the lack of negation datasets by producing a diverse range of negation types from affirmative sentences, including verbal, non-verbal, and affixal forms commonly found in English text. We provide new rules for masking parts of sentences where negations are most likely to occur, based on syntactic structure and use a frozen baseline LLM and prompt tuning to generate negated sentences. We also propose a filtering mechanism to identify negation cues and remove degenerate examples, producing a diverse range of meaningful perturbations. Our results show that NegVerse outperforms existing methods and generates negations with higher lexical similarity to the original sentences, better syntactic preservation and negation diversity. The code is available in https://github.com/DarianRodriguez/NegVerse
Federated Fairness without Access to Sensitive Groups
Feb 22, 2024Current approaches to group fairness in federated learning assume the existence of predefined and labeled sensitive groups during training. However, due to factors ranging from emerging regulations to dynamics and location-dependency of protected groups, this assumption may be unsuitable in many real-world scenarios. In this work, we propose a new approach to guarantee group fairness that does not rely on any predefined definition of sensitive groups or additional labels. Our objective allows the federation to learn a Pareto efficient global model ensuring worst-case group fairness and it enables, via a single hyper-parameter, trade-offs between fairness and utility, subject only to a group size constraint. This implies that any sufficiently large subset of the population is guaranteed to receive at least a minimum level of utility performance from the model. The proposed objective encompasses existing approaches as special cases, such as empirical risk minimization and subgroup robustness objectives from centralized machine learning. We provide an algorithm to solve this problem in federation that enjoys convergence and excess risk guarantees. Our empirical results indicate that the proposed approach can effectively improve the worst-performing group that may be present without unnecessarily hurting the average performance, exhibits superior or comparable performance to relevant baselines, and achieves a large set of solutions with different fairness-utility trade-offs.
Minimax Demographic Group Fairness in Federated Learning
Jan 25, 2022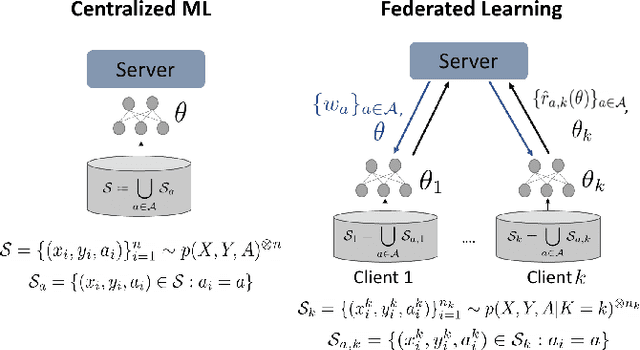
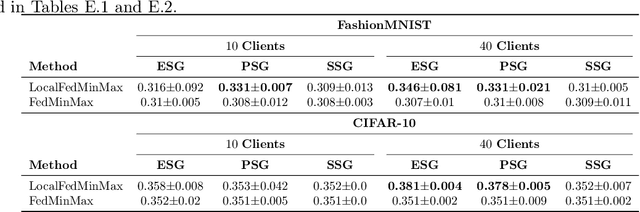
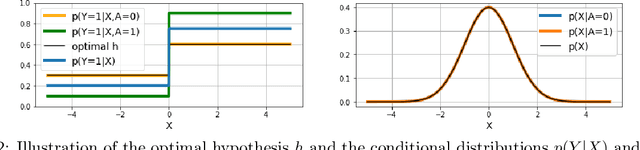
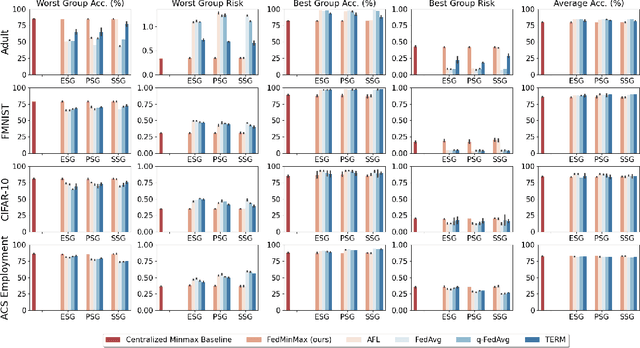
Federated learning is an increasingly popular paradigm that enables a large number of entities to collaboratively learn better models. In this work, we study minimax group fairness in federated learning scenarios where different participating entities may only have access to a subset of the population groups during the training phase. We formally analyze how our proposed group fairness objective differs from existing federated learning fairness criteria that impose similar performance across participants instead of demographic groups. We provide an optimization algorithm -- FedMinMax -- for solving the proposed problem that provably enjoys the performance guarantees of centralized learning algorithms. We experimentally compare the proposed approach against other state-of-the-art methods in terms of group fairness in various federated learning setups, showing that our approach exhibits competitive or superior performance.
Federating for Learning Group Fair Models
Oct 07, 2021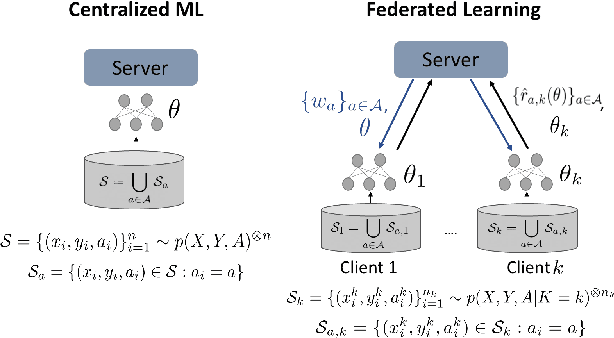
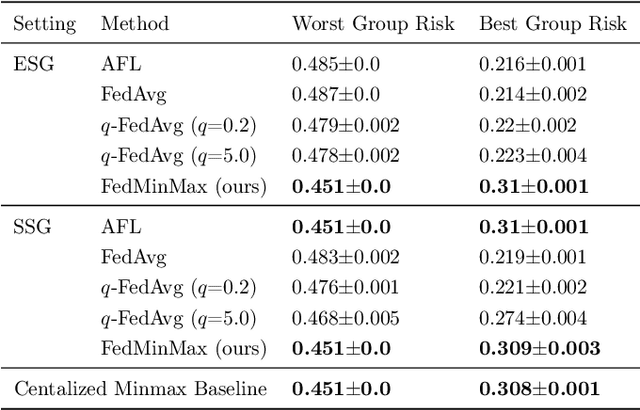
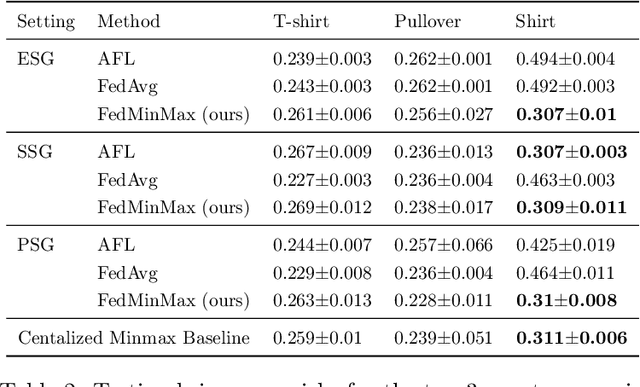
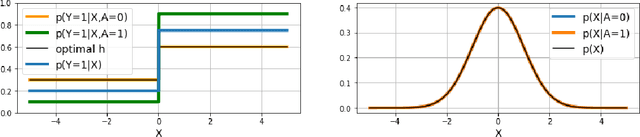
Federated learning is an increasingly popular paradigm that enables a large number of entities to collaboratively learn better models. In this work, we study minmax group fairness in paradigms where different participating entities may only have access to a subset of the population groups during the training phase. We formally analyze how this fairness objective differs from existing federated learning fairness criteria that impose similar performance across participants instead of demographic groups. We provide an optimization algorithm -- FedMinMax -- for solving the proposed problem that provably enjoys the performance guarantees of centralized learning algorithms. We experimentally compare the proposed approach against other methods in terms of group fairness in various federated learning setups.
Learning to Collaborate for User-Controlled Privacy
May 18, 2018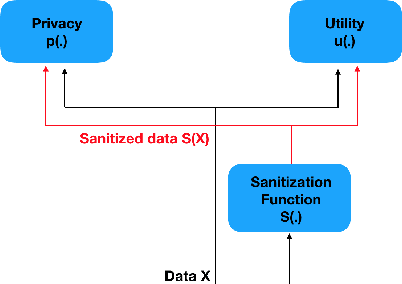
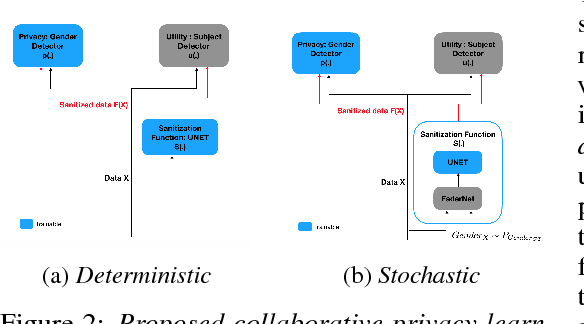
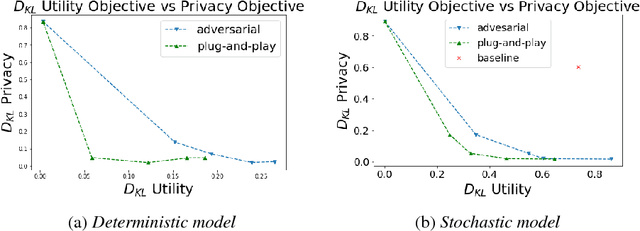
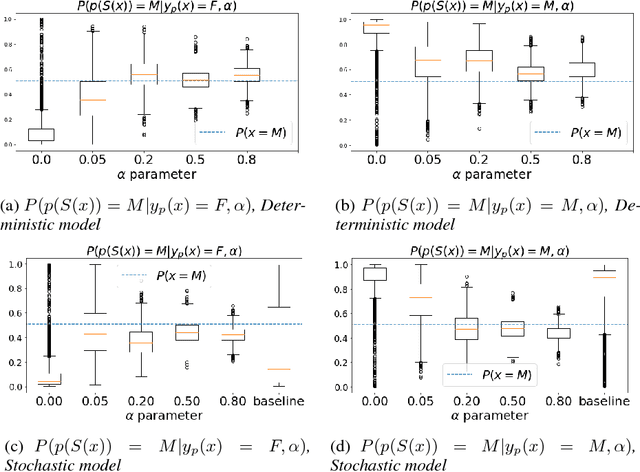
It is becoming increasingly clear that users should own and control their data. Utility providers are also becoming more interested in guaranteeing data privacy. As such, users and utility providers should collaborate in data privacy, a paradigm that has not yet been developed in the privacy research community. We introduce this concept and present explicit architectures where the user controls what characteristics of the data she/he wants to share and what she/he wants to keep private. This is achieved by collaborative learning a sensitization function, either a deterministic or a stochastic one, that retains valuable information for the utility tasks but it also eliminates necessary information for the privacy ones. As illustration examples, we implement them using a plug-and-play approach, where no algorithm is changed at the system provider end, and an adversarial approach, where minor re-training of the privacy inferring engine is allowed. In both cases the learned sanitization function keeps the data in the original domain, thereby allowing the system to use the same algorithms it was using before for both original and privatized data. We show how we can maintain utility while fully protecting private information if the user chooses to do so, even when the first is harder than the second, as in the case here illustrated of identity detection while hiding gender.