 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Diffusion Duet: Harmonizing Dual Channels with Wavelet Suppression for Image Separation
Feb 13, 2026Blind image separation (BIS) refers to the inverse problem of simultaneously estimating and restoring multiple independent source images from a single observation image under conditions of unknown mixing mode and without prior knowledge of the source images. Traditional methods relying on statistical independence assumptions or CNN/GAN variants struggle to characterize complex feature distributions in real scenes, leading to estimation bias, texture distortion, and artifact residue under strong noise and nonlinear mixing. This paper innovatively introduces diffusion models into dual-channel BIS, proposing an efficient Dual-Channel Diffusion Separation Model (DCDSM). DCDSM leverages diffusion models' powerful generative capability to learn source image feature distributions and reconstruct feature structures effectively. A novel Wavelet Suppression Module (WSM) is designed within the dual-branch reverse denoising process, forming an interactive separation network that enhances detail separation by exploiting the mutual coupling noise characteristic between source images. Extensive experiments on synthetic datasets containing rain/snow and complex mixtures demonstrate that DCDSM achieves state-of-the-art performance: 1) In image restoration tasks, it obtains PSNR/SSIM values of 35.0023 dB/0.9549 and 29.8108 dB/0.9243 for rain and snow removal respectively, outperforming Histoformer and LDRCNet by 1.2570 dB/0.9272 dB (PSNR) and 0.0262/0.0289 (SSIM) on average; 2) For complex mixture separation, the restored dual-source images achieve average PSNR and SSIM of 25.0049 dB and 0.7997, surpassing comparative methods by 4.1249 dB and 0.0926. Both subjective and objective evaluations confirm DCDSM's superiority in addressing rain/snow residue removal and detail preservation challenges.
Neural Network for Blind Unmixing: a novel MatrixConv Unmixing (MCU) Approach
Mar 11, 2025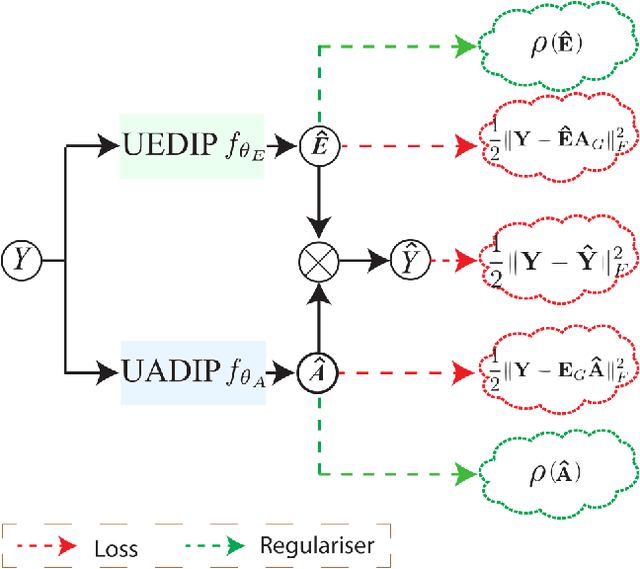
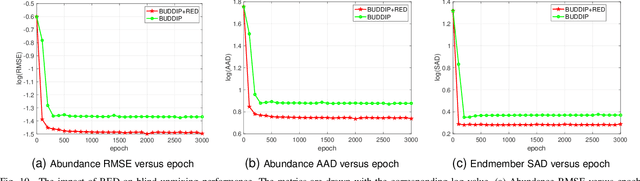
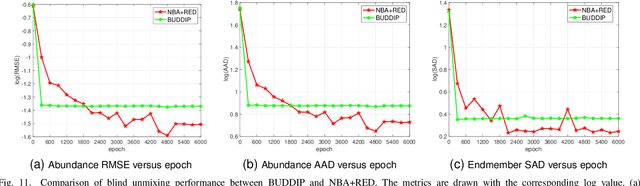
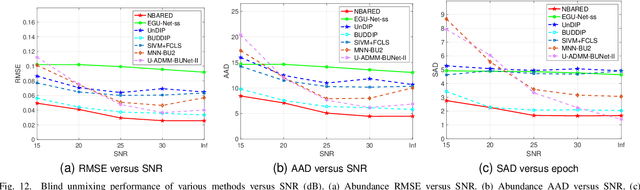
Hyperspectral image (HSI) unmixing is a challenging research problem that tries to identify the constituent components, known as endmembers, and their corresponding proportions, known as abundances, in the scene by analysing images captured by hyperspectral cameras. Recently, many deep learning based unmixing approaches have been proposed with the surge of machine learning techniques, especially convolutional neural networks (CNN). However, these methods face two notable challenges: 1. They frequently yield results lacking physical significance, such as signatures corresponding to unknown or non-existent materials. 2. CNNs, as general-purpose network structures, are not explicitly tailored for unmixing tasks. In response to these concerns, our work draws inspiration from double deep image prior (DIP) techniques and algorithm unrolling, presenting a novel network structure that effectively addresses both issues. Specifically, we first propose a MatrixConv Unmixing (MCU) approach for endmember and abundance estimation, respectively, which can be solved via certain iterative solvers. We then unroll these solvers to build two sub-networks, endmember estimation DIP (UEDIP) and abundance estimation DIP (UADIP), to generate the estimation of endmember and abundance, respectively. The overall network is constructed by assembling these two sub-networks. In order to generate meaningful unmixing results, we also propose a composite loss function. To further improve the unmixing quality, we also add explicitly a regularizer for endmember and abundance estimation, respectively. The proposed methods are tested for effectiveness on both synthetic and real datasets.
Optimization Guarantees of Unfolded ISTA and ADMM Networks With Smooth Soft-Thresholding
Sep 12, 2023



Solving linear inverse problems plays a crucial role in numerous applications. Algorithm unfolding based, model-aware data-driven approaches have gained significant attention for effectively addressing these problems. Learned iterative soft-thresholding algorithm (LISTA) and alternating direction method of multipliers compressive sensing network (ADMM-CSNet) are two widely used such approaches, based on ISTA and ADMM algorithms, respectively. In this work, we study optimization guarantees, i.e., achieving near-zero training loss with the increase in the number of learning epochs, for finite-layer unfolded networks such as LISTA and ADMM-CSNet with smooth soft-thresholding in an over-parameterized (OP) regime. We achieve this by leveraging a modified version of the Polyak-Lojasiewicz, denoted PL$^*$, condition. Satisfying the PL$^*$ condition within a specific region of the loss landscape ensures the existence of a global minimum and exponential convergence from initialization using gradient descent based methods. Hence, we provide conditions, in terms of the network width and the number of training samples, on these unfolded networks for the PL$^*$ condition to hold. We achieve this by deriving the Hessian spectral norm of these networks. Additionally, we show that the threshold on the number of training samples increases with the increase in the network width. Furthermore, we compare the threshold on training samples of unfolded networks with that of a standard fully-connected feed-forward network (FFNN) with smooth soft-thresholding non-linearity. We prove that unfolded networks have a higher threshold value than FFNN. Consequently, one can expect a better expected error for unfolded networks than FFNN.
Mixed X-Ray Image Separation for Artworks with Concealed Designs
Jan 23, 2022
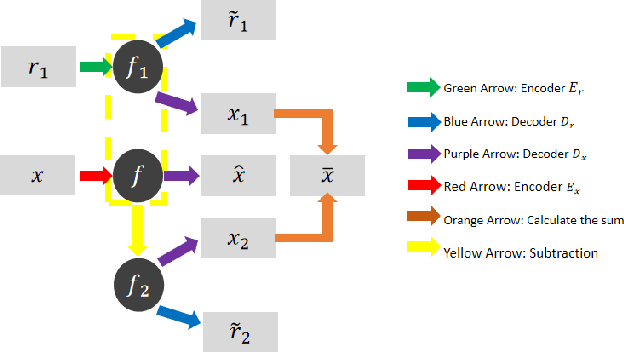
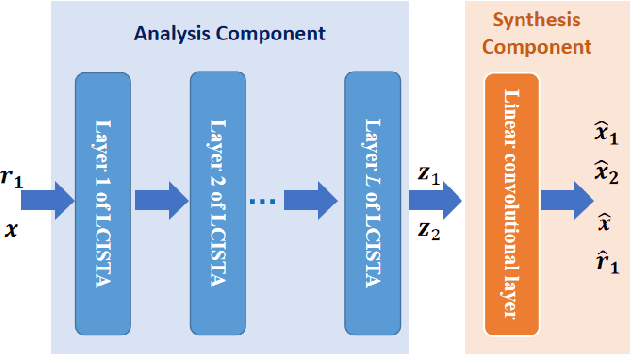
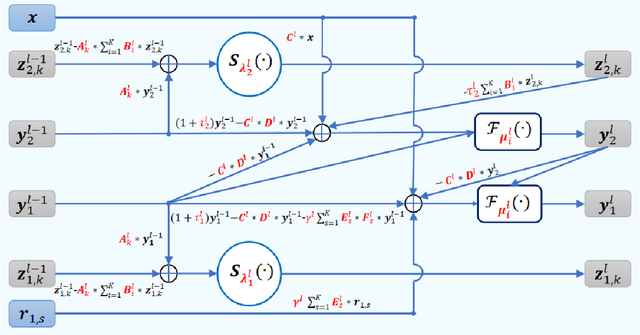
In this paper, we focus on X-ray images of paintings with concealed sub-surface designs (e.g., deriving from reuse of the painting support or revision of a composition by the artist), which include contributions from both the surface painting and the concealed features. In particular, we propose a self-supervised deep learning-based image separation approach that can be applied to the X-ray images from such paintings to separate them into two hypothetical X-ray images. One of these reconstructed images is related to the X-ray image of the concealed painting, while the second one contains only information related to the X-ray of the visible painting. The proposed separation network consists of two components: the analysis and the synthesis sub-networks. The analysis sub-network is based on learned coupled iterative shrinkage thresholding algorithms (LCISTA) designed using algorithm unrolling techniques, and the synthesis sub-network consists of several linear mappings. The learning algorithm operates in a totally self-supervised fashion without requiring a sample set that contains both the mixed X-ray images and the separated ones. The proposed method is demonstrated on a real painting with concealed content, Do\~na Isabel de Porcel by Francisco de Goya, to show its effectiveness.
UGV-UAV Object Geolocation in Unstructured Environments
Jan 14, 2022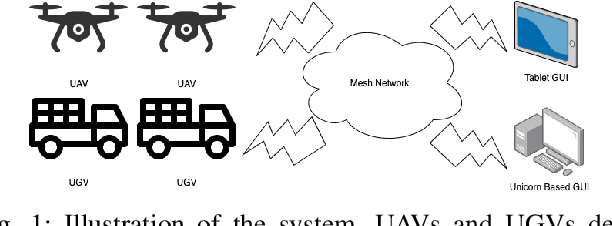


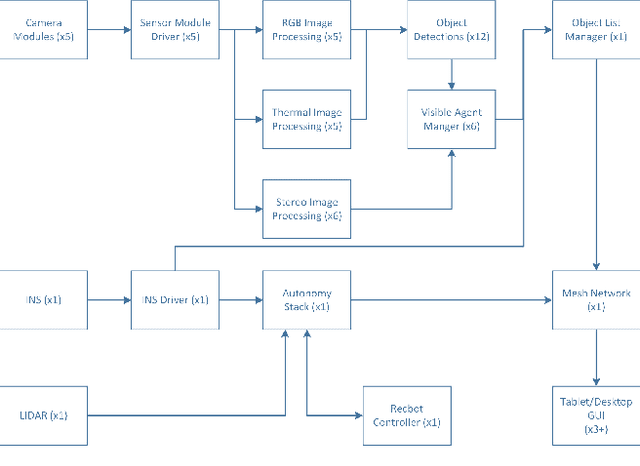
A robotic system of multiple unmanned ground vehicles (UGVs) and unmanned aerial vehicles (UAVs) has the potential for advancing autonomous object geolocation performance. Much research has focused on algorithmic improvements on individual components, such as navigation, motion planning, and perception. In this paper, we present a UGV-UAV object detection and geolocation system, which performs perception, navigation, and planning autonomously in real scale in unstructured environment. We designed novel sensor pods equipped with multispectral (visible, near-infrared, thermal), high resolution (181.6 Mega Pixels), stereo (near-infrared pair), wide field of view (192 degree HFOV) array. We developed a novel on-board software-hardware architecture to process the high volume sensor data in real-time, and we built a custom AI subsystem composed of detection, tracking, navigation, and planning for autonomous objects geolocation in real-time. This research is the first real scale demonstration of such high speed data processing capability. Our novel modular sensor pod can boost relevant computer vision and machine learning research. Our novel hardware-software architecture is a solid foundation for system-level and component-level research. Our system is validated through data-driven offline tests as well as a series of field tests in unstructured environments. We present quantitative results as well as discussions on key robotic system level challenges which manifest when we build and test the system. This system is the first step toward a UGV-UAV cooperative reconnaissance system in the future.
Robust lEarned Shrinkage-Thresholding (REST): Robust unrolling for sparse recover
Oct 20, 2021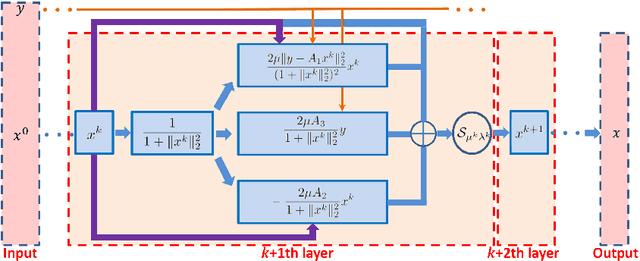



In this paper, we consider deep neural networks for solving inverse problems that are robust to forward model mis-specifications. Specifically, we treat sensing problems with model mismatch where one wishes to recover a sparse high-dimensional vector from low-dimensional observations subject to uncertainty in the measurement operator. We then design a new robust deep neural network architecture by applying algorithm unfolding techniques to a robust version of the underlying recovery problem. Our proposed network - named Robust lEarned Shrinkage-Thresholding (REST) - exhibits an additional normalization processing compared to Learned Iterative Shrinkage-Thresholding Algorithm (LISTA), leading to reliable recovery of the signal under sample-wise varying model mismatch. The proposed REST network is shown to outperform state-of-the-art model-based and data-driven algorithms in both compressive sensing and radar imaging problems wherein model mismatch is taken into consideration.
SBEVNet: End-to-End Deep Stereo Layout Estimation
May 25, 2021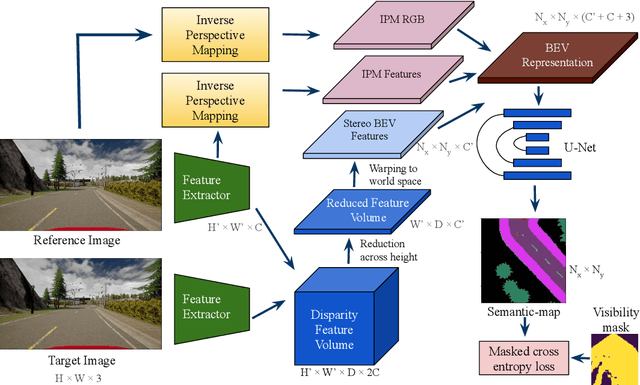
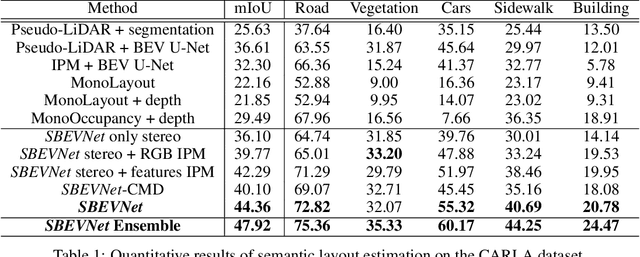
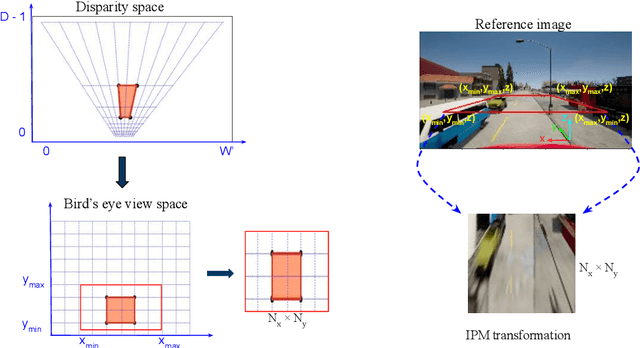
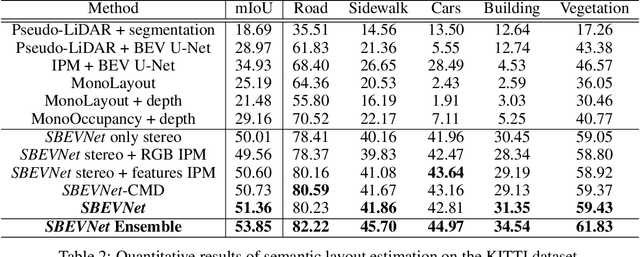
Accurate layout estimation is crucial for planning and navigation in robotics applications, such as self-driving. In this paper, we introduce the Stereo Bird's Eye ViewNetwork (SBEVNet), a novel supervised end-to-end framework for estimation of bird's eye view layout from a pair of stereo images. Although our network reuses some of the building blocks from the state-of-the-art deep learning networks for disparity estimation, we show that explicit depth estimation is neither sufficient nor necessary. Instead, the learning of a good internal bird's eye view feature representation is effective for layout estimation. Specifically, we first generate a disparity feature volume using the features of the stereo images and then project it to the bird's eye view coordinates. This gives us coarse-grained information about the scene structure. We also apply inverse perspective mapping (IPM) to map the input images and their features to the bird's eye view. This gives us fine-grained texture information. Concatenating IPM features with the projected feature volume creates a rich bird's eye view representation which is useful for spatial reasoning. We use this representation to estimate the BEV semantic map. Additionally, we show that using the IPM features as a supervisory signal for stereo features can give an improvement in performance. We demonstrate our approach on two datasets:the KITTI dataset and a synthetically generated dataset from the CARLA simulator. For both of these datasets, we establish state-of-the-art performance compared to baseline techniques.
Image Separation with Side Information: A Connected Auto-Encoders Based Approach
Sep 16, 2020
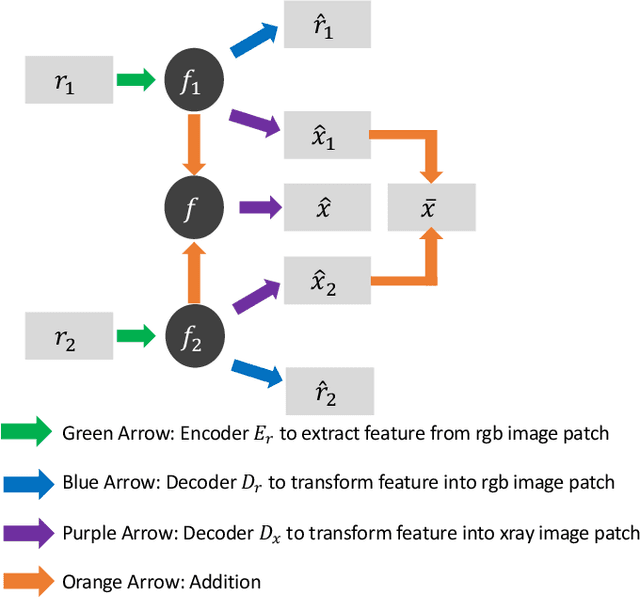
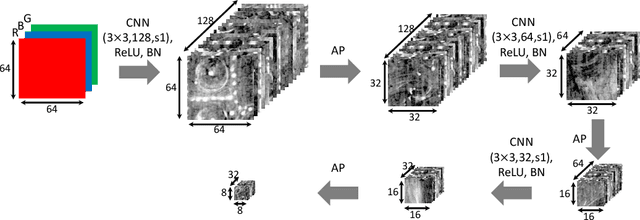
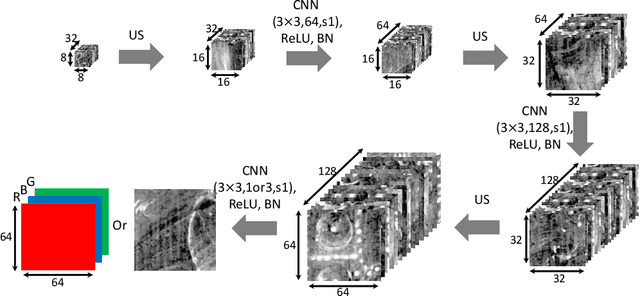
X-radiography (X-ray imaging) is a widely used imaging technique in art investigation. It can provide information about the condition of a painting as well as insights into an artist's techniques and working methods, often revealing hidden information invisible to the naked eye. In this paper, we deal with the problem of separating mixed X-ray images originating from the radiography of double-sided paintings. Using the visible color images (RGB images) from each side of the painting, we propose a new Neural Network architecture, based upon 'connected' auto-encoders, designed to separate the mixed X-ray image into two simulated X-ray images corresponding to each side. In this proposed architecture, the convolutional auto encoders extract features from the RGB images. These features are then used to (1) reproduce both of the original RGB images, (2) reconstruct the hypothetical separated X-ray images, and (3) regenerate the mixed X-ray image. The algorithm operates in a totally self-supervised fashion without requiring a sample set that contains both the mixed X-ray images and the separated ones. The methodology was tested on images from the double-sided wing panels of the \textsl{Ghent Altarpiece}, painted in 1432 by the brothers Hubert and Jan van Eyck. These tests show that the proposed approach outperforms other state-of-the-art X-ray image separation methods for art investigation applications.