 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Pixel Codec Avatars: A Hybrid Representation for Efficient Rendering
Dec 17, 2025We present Gaussian Pixel Codec Avatars (GPiCA), photorealistic head avatars that can be generated from multi-view images and efficiently rendered on mobile devices. GPiCA utilizes a unique hybrid representation that combines a triangle mesh and anisotropic 3D Gaussians. This combination maximizes memory and rendering efficiency while maintaining a photorealistic appearance. The triangle mesh is highly efficient in representing surface areas like facial skin, while the 3D Gaussians effectively handle non-surface areas such as hair and beard. To this end, we develop a unified differentiable rendering pipeline that treats the mesh as a semi-transparent layer within the volumetric rendering paradigm of 3D Gaussian Splatting. We train neural networks to decode a facial expression code into three components: a 3D face mesh, an RGBA texture, and a set of 3D Gaussians. These components are rendered simultaneously in a unified rendering engine. The networks are trained using multi-view image supervision. Our results demonstrate that GPiCA achieves the realism of purely Gaussian-based avatars while matching the rendering performance of mesh-based avatars.
SqueezeMe: Efficient Gaussian Avatars for VR
Dec 19, 2024



Gaussian Splatting has enabled real-time 3D human avatars with unprecedented levels of visual quality. While previous methods require a desktop GPU for real-time inference of a single avatar, we aim to squeeze multiple Gaussian avatars onto a portable virtual reality headset with real-time drivable inference. We begin by training a previous work, Animatable Gaussians, on a high quality dataset captured with 512 cameras. The Gaussians are animated by controlling base set of Gaussians with linear blend skinning (LBS) motion and then further adjusting the Gaussians with a neural network decoder to correct their appearance. When deploying the model on a Meta Quest 3 VR headset, we find two major computational bottlenecks: the decoder and the rendering. To accelerate the decoder, we train the Gaussians in UV-space instead of pixel-space, and we distill the decoder to a single neural network layer. Further, we discover that neighborhoods of Gaussians can share a single corrective from the decoder, which provides an additional speedup. To accelerate the rendering, we develop a custom pipeline in Vulkan that runs on the mobile GPU. Putting it all together, we run 3 Gaussian avatars concurrently at 72 FPS on a VR headset. Demo videos are at https://forresti.github.io/squeezeme.
Image Segmentation Keras : Implementation of Segnet, FCN, UNet, PSPNet and other models in Keras
Jul 25, 2023Semantic segmentation plays a vital role in computer vision tasks, enabling precise pixel-level understanding of images. In this paper, we present a comprehensive library for semantic segmentation, which contains implementations of popular segmentation models like SegNet, FCN, UNet, and PSPNet. We also evaluate and compare these models on several datasets, offering researchers and practitioners a powerful toolset for tackling diverse segmentation challenges.
SBEVNet: End-to-End Deep Stereo Layout Estimation
May 25, 2021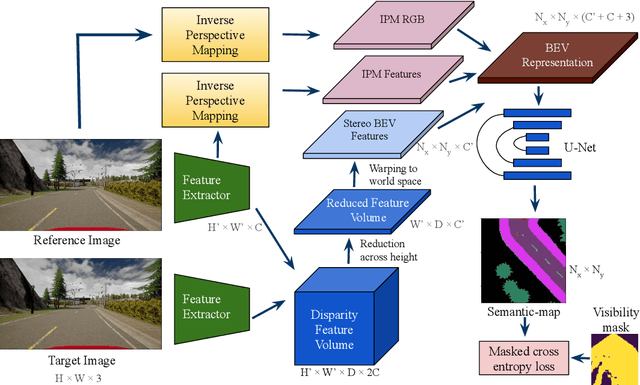
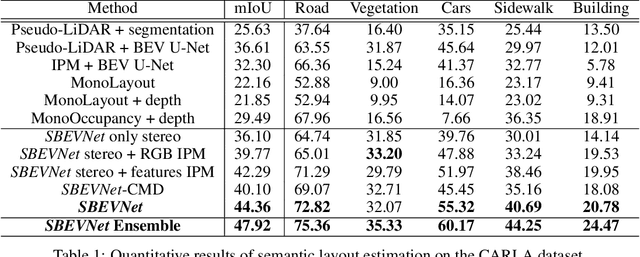
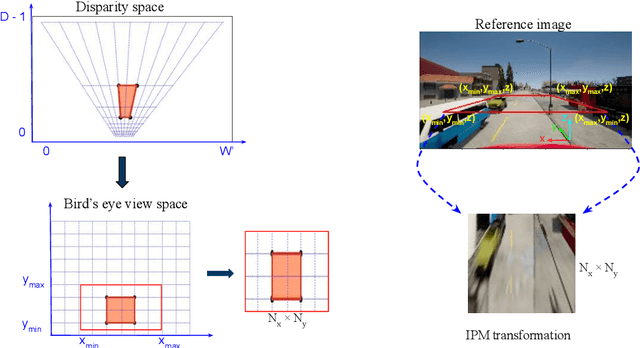
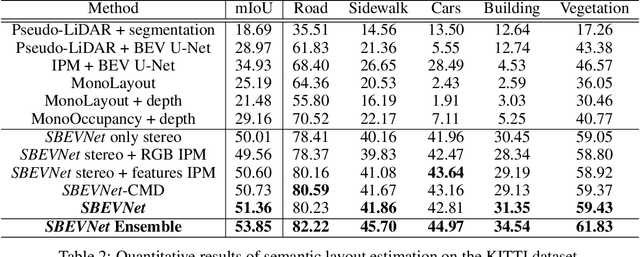
Accurate layout estimation is crucial for planning and navigation in robotics applications, such as self-driving. In this paper, we introduce the Stereo Bird's Eye ViewNetwork (SBEVNet), a novel supervised end-to-end framework for estimation of bird's eye view layout from a pair of stereo images. Although our network reuses some of the building blocks from the state-of-the-art deep learning networks for disparity estimation, we show that explicit depth estimation is neither sufficient nor necessary. Instead, the learning of a good internal bird's eye view feature representation is effective for layout estimation. Specifically, we first generate a disparity feature volume using the features of the stereo images and then project it to the bird's eye view coordinates. This gives us coarse-grained information about the scene structure. We also apply inverse perspective mapping (IPM) to map the input images and their features to the bird's eye view. This gives us fine-grained texture information. Concatenating IPM features with the projected feature volume creates a rich bird's eye view representation which is useful for spatial reasoning. We use this representation to estimate the BEV semantic map. Additionally, we show that using the IPM features as a supervisory signal for stereo features can give an improvement in performance. We demonstrate our approach on two datasets:the KITTI dataset and a synthetically generated dataset from the CARLA simulator. For both of these datasets, we establish state-of-the-art performance compared to baseline techniques.
Making Third Person Techniques Recognize First-Person Actions in Egocentric Videos
Oct 17, 2019
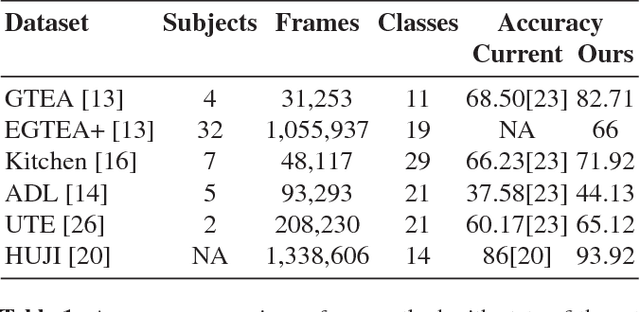
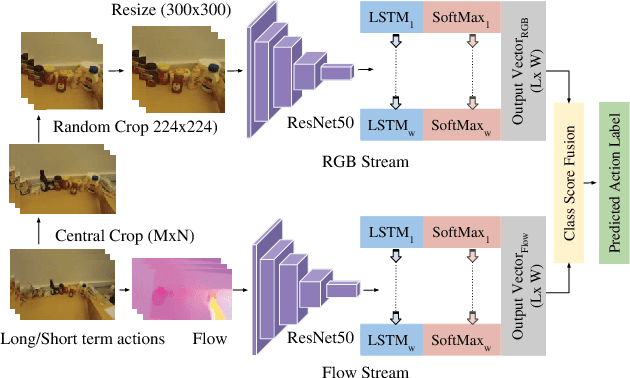
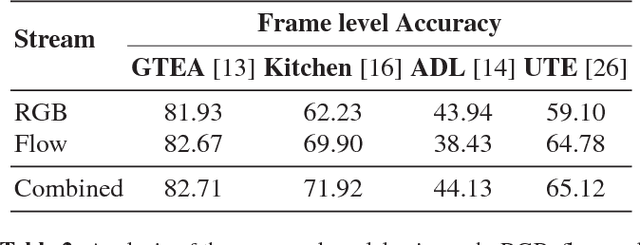
We focus on first-person action recognition from egocentric videos. Unlike third person domain, researchers have divided first-person actions into two categories: involving hand-object interactions and the ones without, and developed separate techniques for the two action categories. Further, it has been argued that traditional cues used for third person action recognition do not suffice, and egocentric specific features, such as head motion and handled objects have been used for such actions. Unlike the state-of-the-art approaches, we show that a regular two stream Convolutional Neural Network (CNN) with Long Short-Term Memory (LSTM) architecture, having separate streams for objects and motion, can generalize to all categories of first-person actions. The proposed approach unifies the feature learned by all action categories, making the proposed architecture much more practical. In an important observation, we note that the size of the objects visible in the egocentric videos is much smaller. We show that the performance of the proposed model improves after cropping and resizing frames to make the size of objects comparable to the size of ImageNet's objects. Our experiments on the standard datasets: GTEA, EGTEA Gaze+, HUJI, ADL, UTE, and Kitchen, proves that our model significantly outperforms various state-of-the-art techniques.
Multi-task Learning for Target-dependent Sentiment Classification
Feb 08, 2019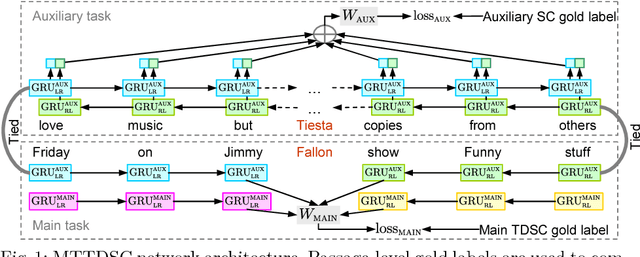
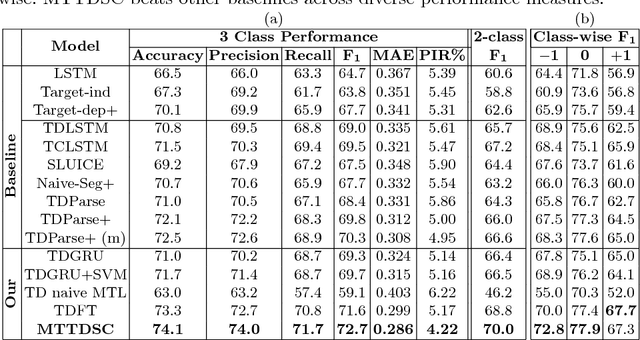
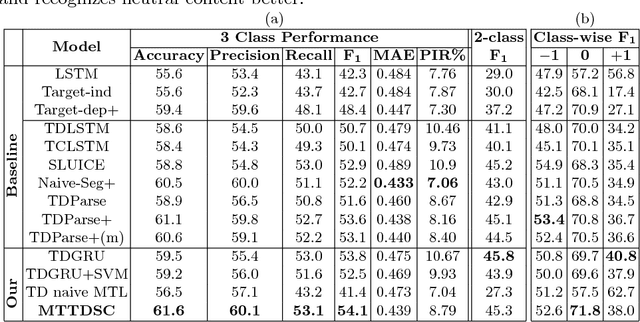
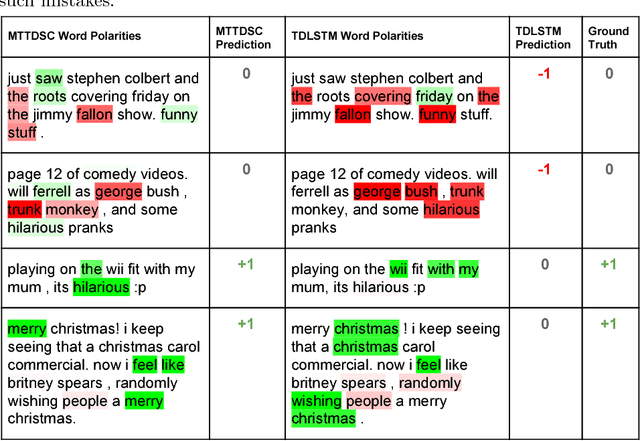
Detecting and aggregating sentiments toward people, organizations, and events expressed in unstructured social media have become critical text mining operations. Early systems detected sentiments over whole passages, whereas more recently, target-specific sentiments have been of greater interest. In this paper, we present MTTDSC, a multi-task target-dependent sentiment classification system that is informed by feature representation learnt for the related auxiliary task of passage-level sentiment classification. The auxiliary task uses a gated recurrent unit (GRU) and pools GRU states, followed by an auxiliary fully-connected layer that outputs passage-level predictions. In the main task, these GRUs contribute auxiliary per-token representations over and above word embeddings. The main task has its own, separate GRUs. The auxiliary and main GRUs send their states to a different fully connected layer, trained for the main task. Extensive experiments using two auxiliary datasets and three benchmark datasets (of which one is new, introduced by us) for the main task demonstrate that MTTDSC outperforms state-of-the-art baselines. Using word-level sensitivity analysis, we present anecdotal evidence that prior systems can make incorrect target-specific predictions because they miss sentiments expressed by words independent of target.
GIRNet: Interleaved Multi-Task Recurrent State Sequence Models
Nov 28, 2018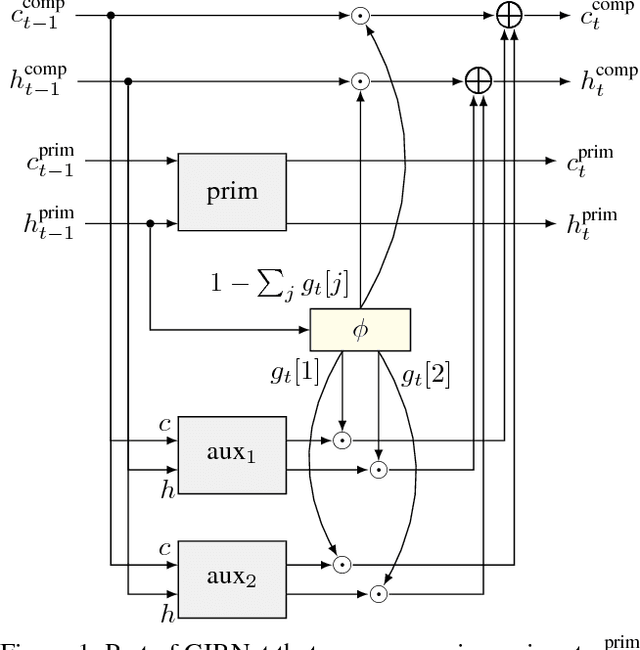


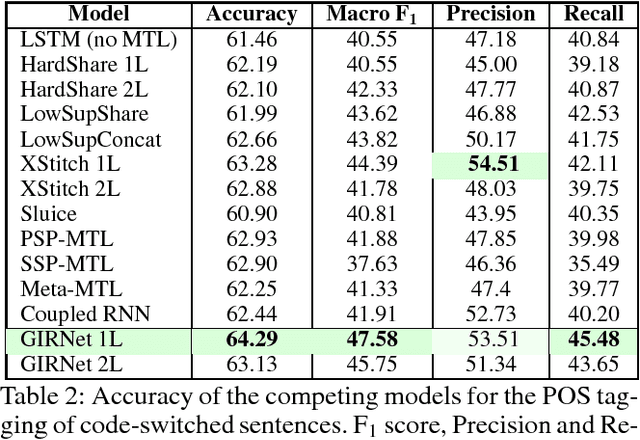
In several natural language tasks, labeled sequences are available in separate domains (say, languages), but the goal is to label sequences with mixed domain (such as code-switched text). Or, we may have available models for labeling whole passages (say, with sentiments), which we would like to exploit toward better position-specific label inference (say, target-dependent sentiment annotation). A key characteristic shared across such tasks is that different positions in a primary instance can benefit from different `experts' trained from auxiliary data, but labeled primary instances are scarce, and labeling the best expert for each position entails unacceptable cognitive burden. We propose GITNet, a unified position-sensitive multi-task recurrent neural network (RNN) architecture for such applications. Auxiliary and primary tasks need not share training instances. Auxiliary RNNs are trained over auxiliary instances. A primary instance is also submitted to each auxiliary RNN, but their state sequences are gated and merged into a novel composite state sequence tailored to the primary inference task. Our approach is in sharp contrast to recent multi-task networks like the cross-stitch and sluice network, which do not control state transfer at such fine granularity. We demonstrate the superiority of GIRNet using three applications: sentiment classification of code-switched passages, part-of-speech tagging of code-switched text, and target position-sensitive annotation of sentiment in monolingual passages. In all cases, we establish new state-of-the-art performance beyond recent competitive baselines.
PicHunt: Social Media Image Retrieval for Improved Law Enforcement
Sep 15, 2016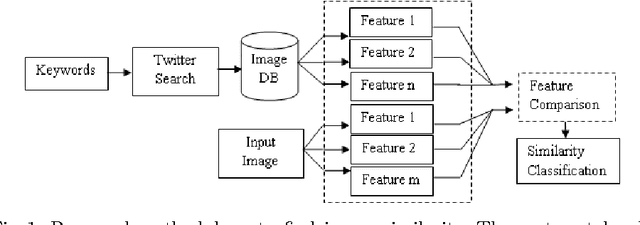


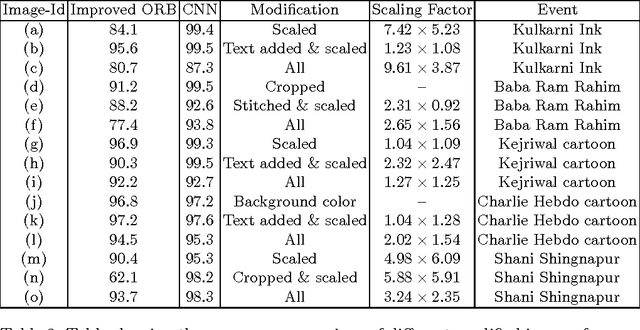
First responders are increasingly using social media to identify and reduce crime for well-being and safety of the society. Images shared on social media hurting religious, political, communal and other sentiments of people, often instigate violence and create law & order situations in society. This results in the need for first responders to inspect the spread of such images and users propagating them on social media. In this paper, we present a comparison between different hand-crafted features and a Convolutional Neural Network (CNN) model to retrieve similar images, which outperforms state-of-art hand-crafted features. We propose an Open-Source-Intelligent (OSINT) real-time image search system, robust to retrieve modified images that allows first responders to analyze the current spread of images, sentiments floating and details of users propagating such content. The system also aids officials to save time of manually analyzing the content by reducing the search space on an average by 67%.