 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Pixel Codec Avatars: A Hybrid Representation for Efficient Rendering
Dec 17, 2025We present Gaussian Pixel Codec Avatars (GPiCA), photorealistic head avatars that can be generated from multi-view images and efficiently rendered on mobile devices. GPiCA utilizes a unique hybrid representation that combines a triangle mesh and anisotropic 3D Gaussians. This combination maximizes memory and rendering efficiency while maintaining a photorealistic appearance. The triangle mesh is highly efficient in representing surface areas like facial skin, while the 3D Gaussians effectively handle non-surface areas such as hair and beard. To this end, we develop a unified differentiable rendering pipeline that treats the mesh as a semi-transparent layer within the volumetric rendering paradigm of 3D Gaussian Splatting. We train neural networks to decode a facial expression code into three components: a 3D face mesh, an RGBA texture, and a set of 3D Gaussians. These components are rendered simultaneously in a unified rendering engine. The networks are trained using multi-view image supervision. Our results demonstrate that GPiCA achieves the realism of purely Gaussian-based avatars while matching the rendering performance of mesh-based avatars.
SqueezeMe: Efficient Gaussian Avatars for VR
Dec 19, 2024



Gaussian Splatting has enabled real-time 3D human avatars with unprecedented levels of visual quality. While previous methods require a desktop GPU for real-time inference of a single avatar, we aim to squeeze multiple Gaussian avatars onto a portable virtual reality headset with real-time drivable inference. We begin by training a previous work, Animatable Gaussians, on a high quality dataset captured with 512 cameras. The Gaussians are animated by controlling base set of Gaussians with linear blend skinning (LBS) motion and then further adjusting the Gaussians with a neural network decoder to correct their appearance. When deploying the model on a Meta Quest 3 VR headset, we find two major computational bottlenecks: the decoder and the rendering. To accelerate the decoder, we train the Gaussians in UV-space instead of pixel-space, and we distill the decoder to a single neural network layer. Further, we discover that neighborhoods of Gaussians can share a single corrective from the decoder, which provides an additional speedup. To accelerate the rendering, we develop a custom pipeline in Vulkan that runs on the mobile GPU. Putting it all together, we run 3 Gaussian avatars concurrently at 72 FPS on a VR headset. Demo videos are at https://forresti.github.io/squeezeme.
High Accuracy Face Geometry Capture using a Smartphone Video
Mar 19, 2020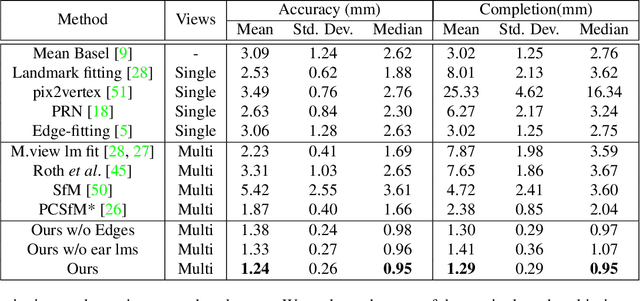


What's the most accurate 3D model of your face you can obtain while sitting at your desk? We attempt to answer this question in our work. High fidelity face reconstructions have so far been limited to either studio settings or through expensive 3D scanners. On the other hand, unconstrained reconstruction methods are typically limited by low-capacity models. Our method reconstructs accurate face geometry of a subject using a video shot from a smartphone in an unconstrained environment. Our approach takes advantage of recent advances in visual SLAM, keypoint detection, and object detection to improve accuracy and robustness. By not being constrained to a model subspace, our reconstructed meshes capture important details while being robust to noise and being topologically consistent. Our evaluations show that our method outperforms current single and multi-view baselines by a significant margin, both in terms of geometric accuracy and in capturing person-specific details important for making realistic looking models.
* Presented at The IEEE Winter Conference on Applications of Computer Vision (WACV), 2020, pp. 81-90
Enhancing Salient Object Segmentation Through Attention
May 27, 2019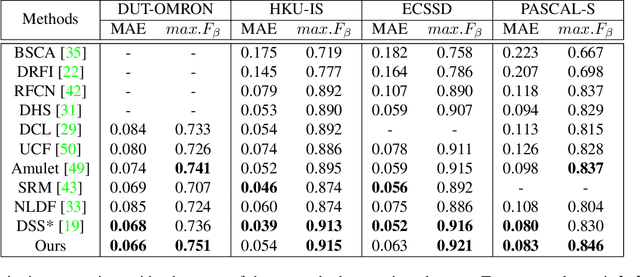
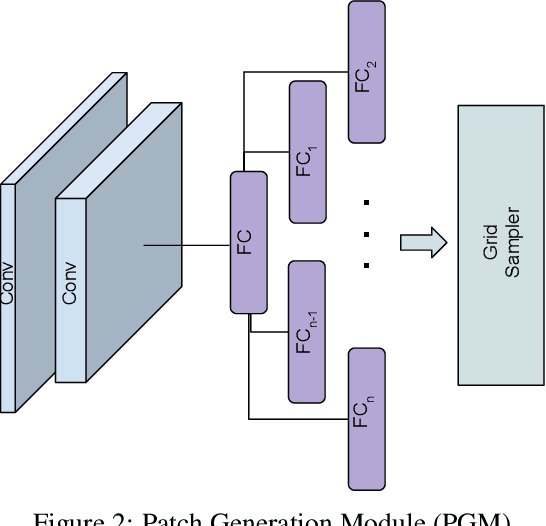
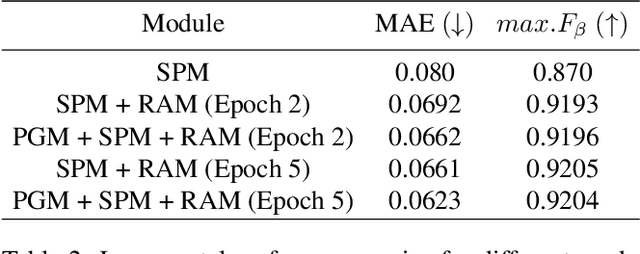
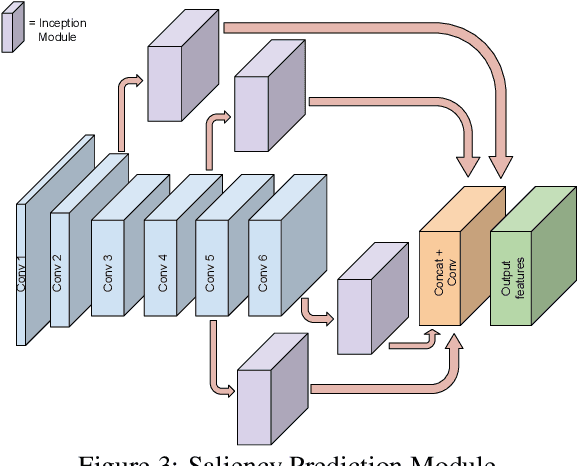
Segmenting salient objects in an image is an important vision task with ubiquitous applications. The problem becomes more challenging in the presence of a cluttered and textured background, low resolution and/or low contrast images. Even though existing algorithms perform well in segmenting most of the object(s) of interest, they often end up segmenting false positives due to resembling salient objects in the background. In this work, we tackle this problem by iteratively attending to image patches in a recurrent fashion and subsequently enhancing the predicted segmentation mask. Saliency features are estimated independently for every image patch, which are further combined using an aggregation strategy based on a Convolutional Gated Recurrent Unit (ConvGRU) network. The proposed approach works in an end-to-end manner, removing background noise and false positives incrementally. Through extensive evaluation on various benchmark datasets, we show superior performance to the existing approaches without any post-processing.
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
Jun 07, 2018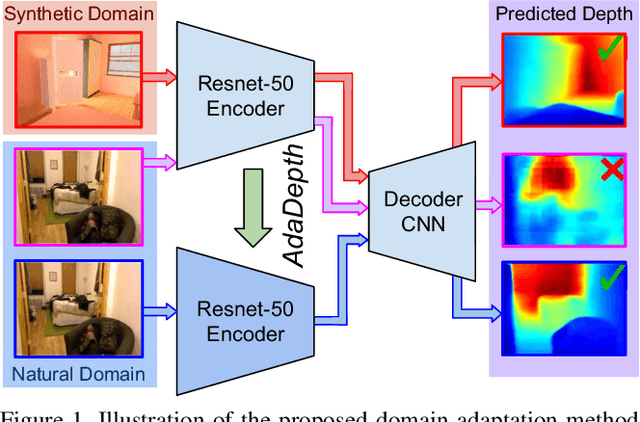
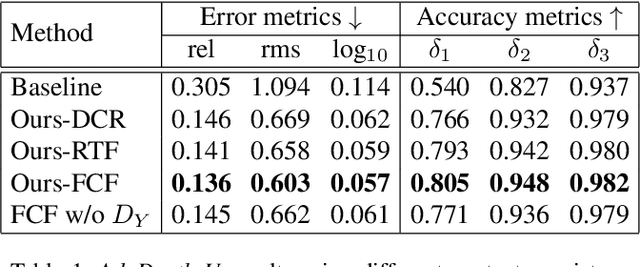
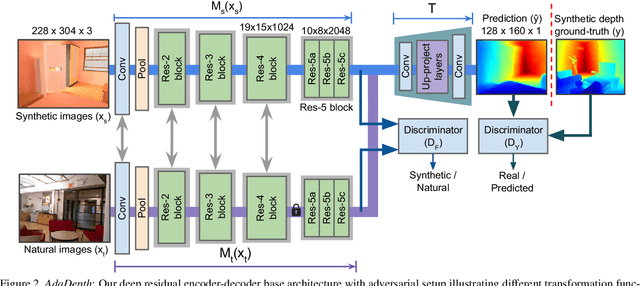
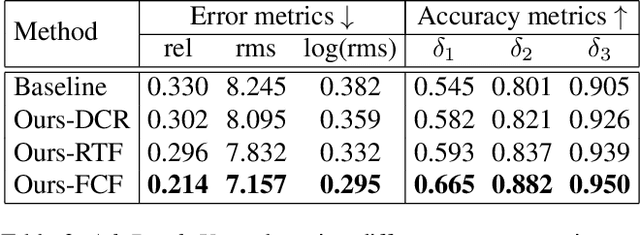
Supervised deep learning methods have shown promising results for the task of monocular depth estimation; but acquiring ground truth is costly, and prone to noise as well as inaccuracies. While synthetic datasets have been used to circumvent above problems, the resultant models do not generalize well to natural scenes due to the inherent domain shift. Recent adversarial approaches for domain adaption have performed well in mitigating the differences between the source and target domains. But these methods are mostly limited to a classification setup and do not scale well for fully-convolutional architectures. In this work, we propose AdaDepth - an unsupervised domain adaptation strategy for the pixel-wise regression task of monocular depth estimation. The proposed approach is devoid of above limitations through a) adversarial learning and b) explicit imposition of content consistency on the adapted target representation. Our unsupervised approach performs competitively with other established approaches on depth estimation tasks and achieves state-of-the-art results in a semi-supervised setting.
On Optimizing Human-Machine Task Assignments
Sep 24, 2015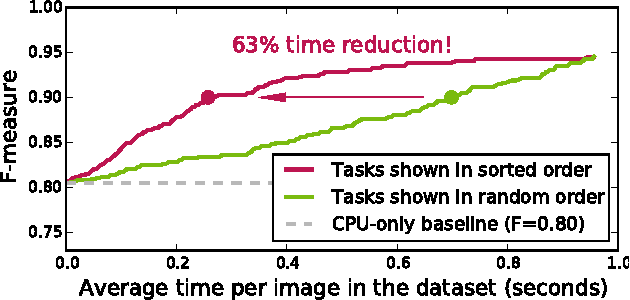
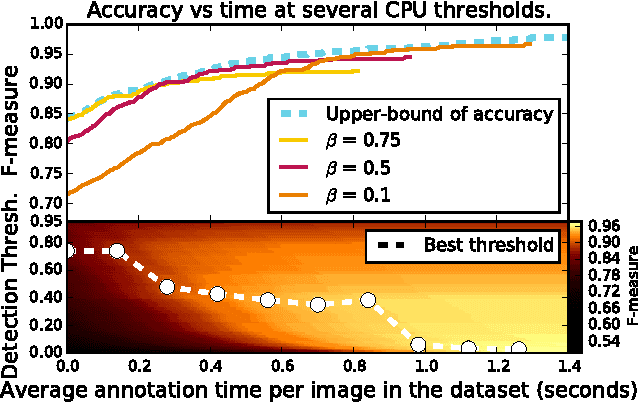
When crowdsourcing systems are used in combination with machine inference systems in the real world, they benefit the most when the machine system is deeply integrated with the crowd workers. However, if researchers wish to integrate the crowd with "off-the-shelf" machine classifiers, this deep integration is not always possible. This work explores two strategies to increase accuracy and decrease cost under this setting. First, we show that reordering tasks presented to the human can create a significant accuracy improvement. Further, we show that greedily choosing parameters to maximize machine accuracy is sub-optimal, and joint optimization of the combined system improves performance.