 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransDocs: Optical Character Recognition with word to word translation
Apr 15, 2023
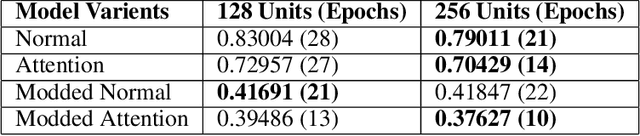
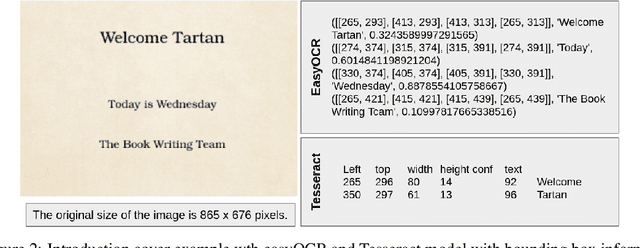
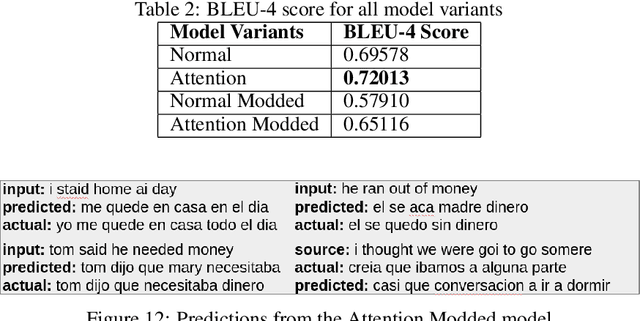
While OCR has been used in various applications, its output is not always accurate, leading to misfit words. This research work focuses on improving the optical character recognition (OCR) with ML techniques with integration of OCR with long short-term memory (LSTM) based sequence to sequence deep learning models to perform document translation. This work is based on ANKI dataset for English to Spanish translation. In this work, I have shown comparative study for pre-trained OCR while using deep learning model using LSTM-based seq2seq architecture with attention for machine translation. End-to-end performance of the model has been expressed in BLEU-4 score. This research paper is aimed at researchers and practitioners interested in OCR and its applications in document translation.
Learning video embedding space with Natural Language Supervision
Apr 08, 2023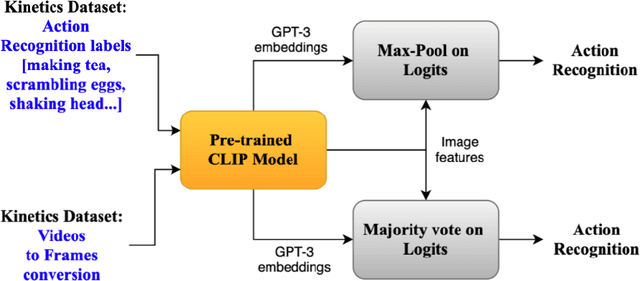
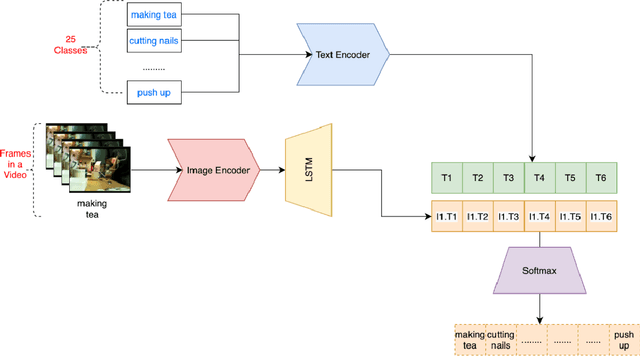
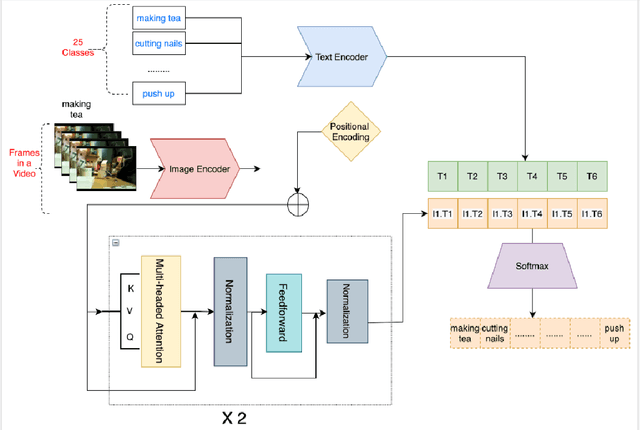
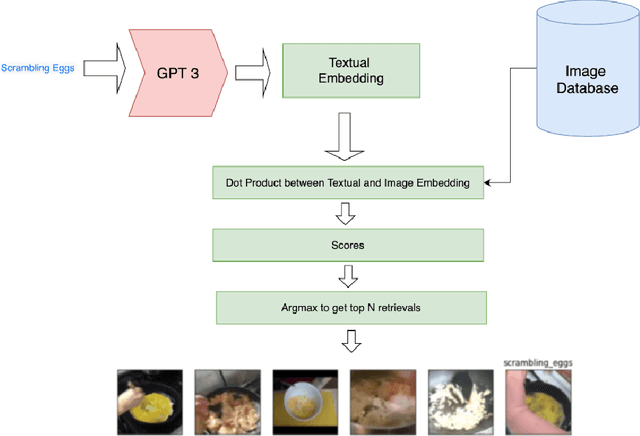
The recent success of the CLIP model has shown its potential to be applied to a wide range of vision and language tasks. However this only establishes embedding space relationship of language to images, not to the video domain. In this paper, we propose a novel approach to map video embedding space to natural langugage. We propose a two-stage approach that first extracts visual features from each frame of a video using a pre-trained CNN, and then uses the CLIP model to encode the visual features for the video domain, along with the corresponding text descriptions. We evaluate our method on two benchmark datasets, UCF101 and HMDB51, and achieve state-of-the-art performance on both tasks.
Dynamic Object Removal for Effective Slam
Mar 20, 2023



This research paper focuses on the problem of dynamic objects and their impact on effective motion planning and localization. The paper proposes a two-step process to address this challenge, which involves finding the dynamic objects in the scene using a Flow-based method and then using a deep Video inpainting algorithm to remove them. The study aims to test the validity of this approach by comparing it with baseline results using two state-of-the-art SLAM algorithms, ORB-SLAM2 and LSD, and understanding the impact of dynamic objects and the corresponding trade-offs. The proposed approach does not require any significant modifications to the baseline SLAM algorithms, and therefore, the computational effort required remains unchanged. The paper presents a detailed analysis of the results obtained and concludes that the proposed method is effective in removing dynamic objects from the scene, leading to improved SLAM performance.
Unsupervised Feature Learning of Human Actions as Trajectories in Pose Embedding Manifold
Dec 06, 2018
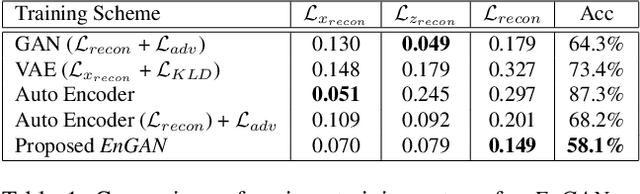

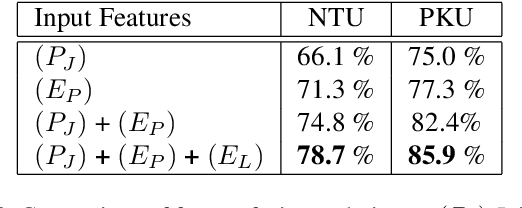
An unsupervised human action modeling framework can provide useful pose-sequence representation, which can be utilized in a variety of pose analysis applications. In this work we propose a novel temporal pose-sequence modeling framework, which can embed the dynamics of 3D human-skeleton joints to a continuous latent space in an efficient manner. In contrast to end-to-end framework explored by previous works, we disentangle the task of individual pose representation learning from the task of learning actions as a trajectory in pose embedding space. In order to realize a continuous pose embedding manifold with improved reconstructions, we propose an unsupervised, manifold learning procedure named Encoder GAN, (or EnGAN). Further, we use the pose embeddings generated by EnGAN to model human actions using a bidirectional RNN auto-encoder architecture, PoseRNN. We introduce first-order gradient loss to explicitly enforce temporal regularity in the predicted motion sequence. A hierarchical feature fusion technique is also investigated for simultaneous modeling of local skeleton joints along with global pose variations. We demonstrate state-of-the-art transfer-ability of the learned representation against other supervisedly and unsupervisedly learned motion embeddings for the task of fine-grained action recognition on SBU interaction dataset. Further, we show the qualitative strengths of the proposed framework by visualizing skeleton pose reconstructions and interpolations in pose-embedding space, and low dimensional principal component projections of the reconstructed pose trajectories.
Ask, Acquire, and Attack: Data-free UAP Generation using Class Impressions
Aug 03, 2018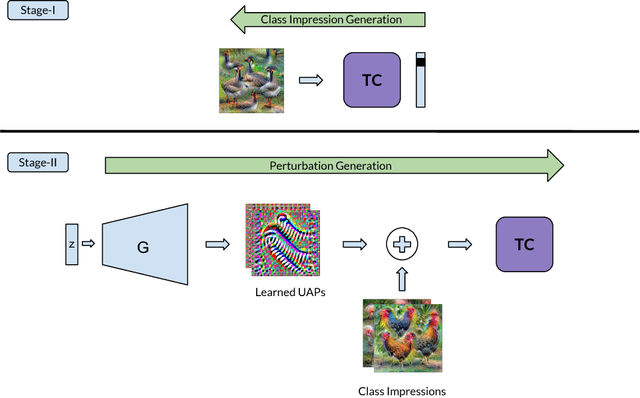
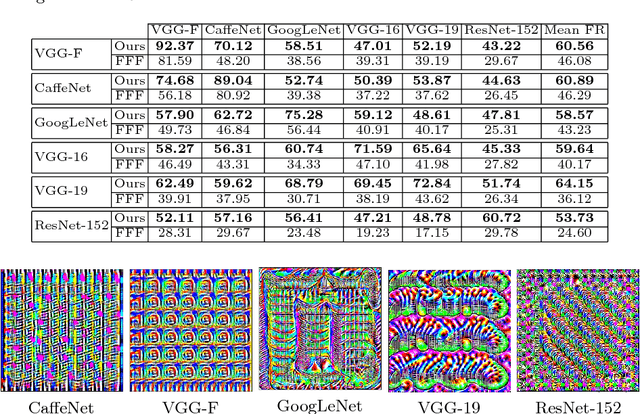

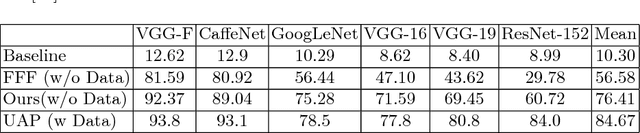
Deep learning models are susceptible to input specific noise, called adversarial perturbations. Moreover, there exist input-agnostic noise, called Universal Adversarial Perturbations (UAP) that can affect inference of the models over most input samples. Given a model, there exist broadly two approaches to craft UAPs: (i) data-driven: that require data, and (ii) data-free: that do not require data samples. Data-driven approaches require actual samples from the underlying data distribution and craft UAPs with high success (fooling) rate. However, data-free approaches craft UAPs without utilizing any data samples and therefore result in lesser success rates. In this paper, for data-free scenarios, we propose a novel approach that emulates the effect of data samples with class impressions in order to craft UAPs using data-driven objectives. Class impression for a given pair of category and model is a generic representation (in the input space) of the samples belonging to that category. Further, we present a neural network based generative model that utilizes the acquired class impressions to learn crafting UAPs. Experimental evaluation demonstrates that the learned generative model, (i) readily crafts UAPs via simple feed-forwarding through neural network layers, and (ii) achieves state-of-the-art success rates for data-free scenario and closer to that for data-driven setting without actually utilizing any data samples.
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
Jun 07, 2018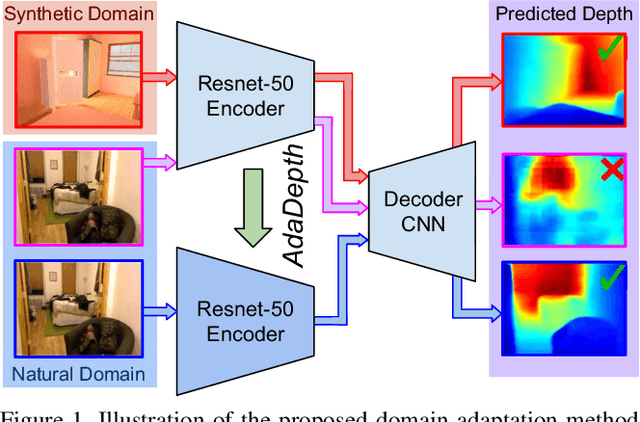
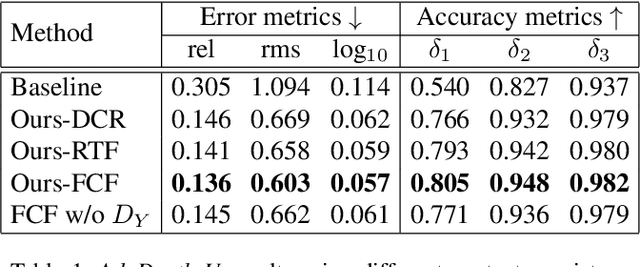
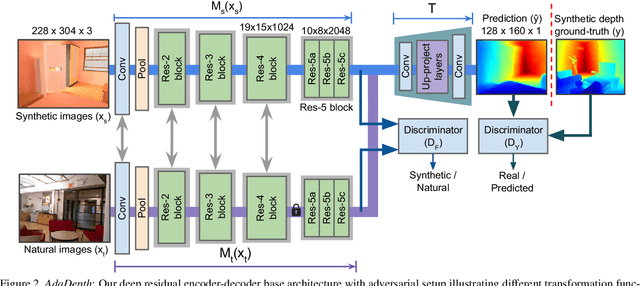
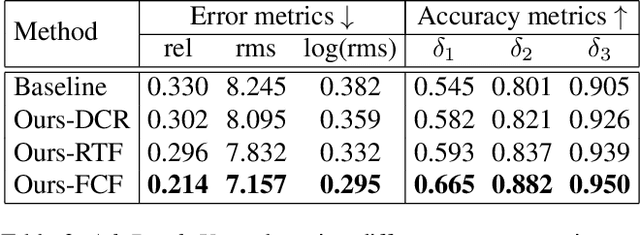
Supervised deep learning methods have shown promising results for the task of monocular depth estimation; but acquiring ground truth is costly, and prone to noise as well as inaccuracies. While synthetic datasets have been used to circumvent above problems, the resultant models do not generalize well to natural scenes due to the inherent domain shift. Recent adversarial approaches for domain adaption have performed well in mitigating the differences between the source and target domains. But these methods are mostly limited to a classification setup and do not scale well for fully-convolutional architectures. In this work, we propose AdaDepth - an unsupervised domain adaptation strategy for the pixel-wise regression task of monocular depth estimation. The proposed approach is devoid of above limitations through a) adversarial learning and b) explicit imposition of content consistency on the adapted target representation. Our unsupervised approach performs competitively with other established approaches on depth estimation tasks and achieves state-of-the-art results in a semi-supervised setting.