 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransDocs: Optical Character Recognition with word to word translation
Paper and Code

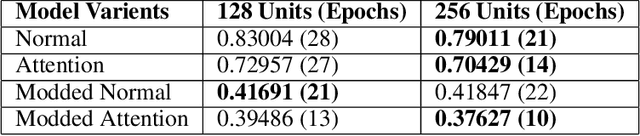
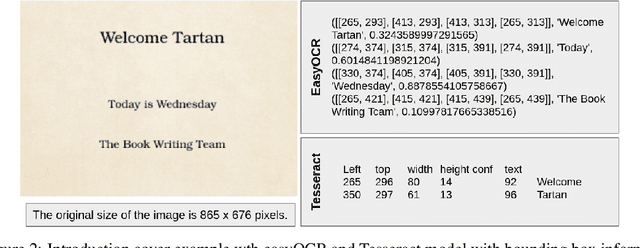
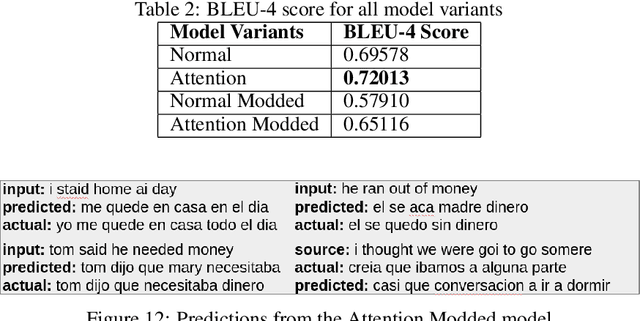
While OCR has been used in various applications, its output is not always accurate, leading to misfit words. This research work focuses on improving the optical character recognition (OCR) with ML techniques with integration of OCR with long short-term memory (LSTM) based sequence to sequence deep learning models to perform document translation. This work is based on ANKI dataset for English to Spanish translation. In this work, I have shown comparative study for pre-trained OCR while using deep learning model using LSTM-based seq2seq architecture with attention for machine translation. End-to-end performance of the model has been expressed in BLEU-4 score. This research paper is aimed at researchers and practitioners interested in OCR and its applications in document translation.