 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIRNet: Interleaved Multi-Task Recurrent State Sequence Models
Paper and Code
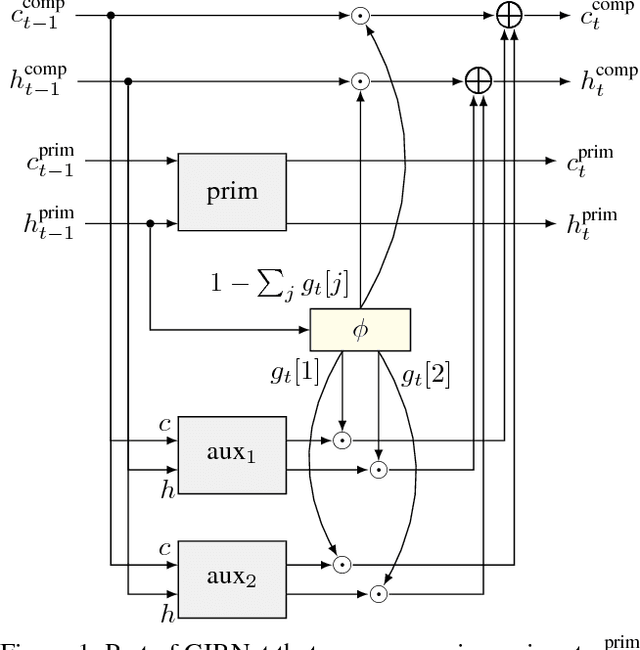


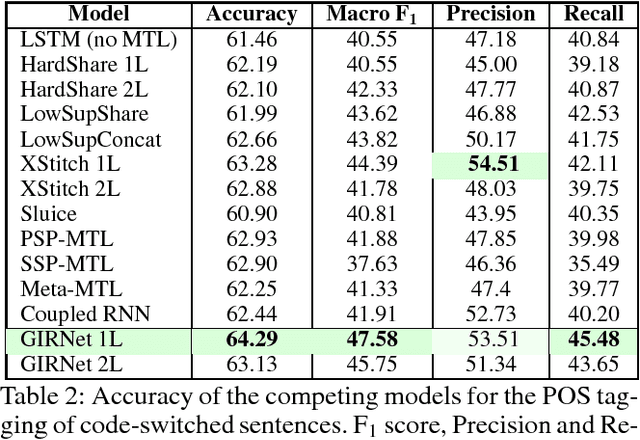
In several natural language tasks, labeled sequences are available in separate domains (say, languages), but the goal is to label sequences with mixed domain (such as code-switched text). Or, we may have available models for labeling whole passages (say, with sentiments), which we would like to exploit toward better position-specific label inference (say, target-dependent sentiment annotation). A key characteristic shared across such tasks is that different positions in a primary instance can benefit from different `experts' trained from auxiliary data, but labeled primary instances are scarce, and labeling the best expert for each position entails unacceptable cognitive burden. We propose GITNet, a unified position-sensitive multi-task recurrent neural network (RNN) architecture for such applications. Auxiliary and primary tasks need not share training instances. Auxiliary RNNs are trained over auxiliary instances. A primary instance is also submitted to each auxiliary RNN, but their state sequences are gated and merged into a novel composite state sequence tailored to the primary inference task. Our approach is in sharp contrast to recent multi-task networks like the cross-stitch and sluice network, which do not control state transfer at such fine granularity. We demonstrate the superiority of GIRNet using three applications: sentiment classification of code-switched passages, part-of-speech tagging of code-switched text, and target position-sensitive annotation of sentiment in monolingual passages. In all cases, we establish new state-of-the-art performance beyond recent competitive baselines.