 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Third Person Techniques Recognize First-Person Actions in Egocentric Videos
Paper and Code

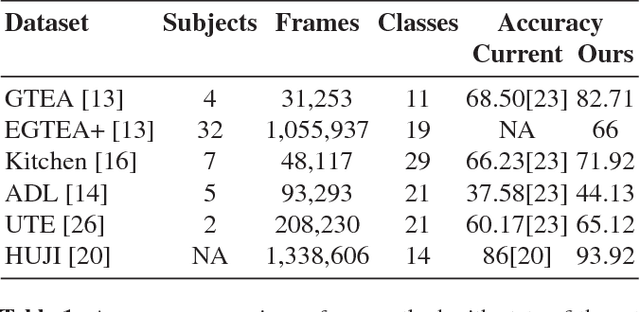
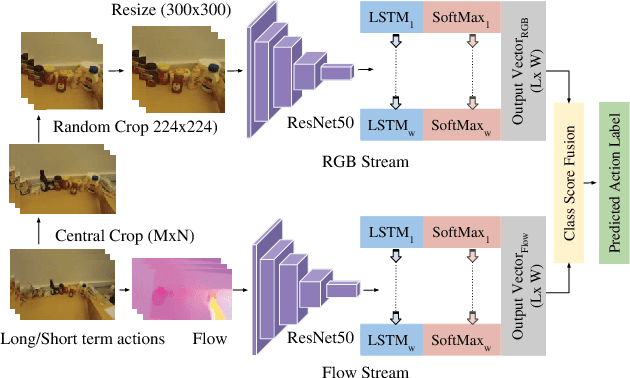
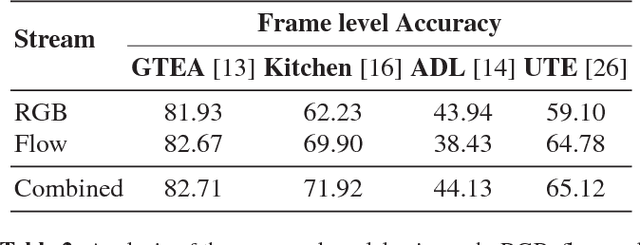
We focus on first-person action recognition from egocentric videos. Unlike third person domain, researchers have divided first-person actions into two categories: involving hand-object interactions and the ones without, and developed separate techniques for the two action categories. Further, it has been argued that traditional cues used for third person action recognition do not suffice, and egocentric specific features, such as head motion and handled objects have been used for such actions. Unlike the state-of-the-art approaches, we show that a regular two stream Convolutional Neural Network (CNN) with Long Short-Term Memory (LSTM) architecture, having separate streams for objects and motion, can generalize to all categories of first-person actions. The proposed approach unifies the feature learned by all action categories, making the proposed architecture much more practical. In an important observation, we note that the size of the objects visible in the egocentric videos is much smaller. We show that the performance of the proposed model improves after cropping and resizing frames to make the size of objects comparable to the size of ImageNet's objects. Our experiments on the standard datasets: GTEA, EGTEA Gaze+, HUJI, ADL, UTE, and Kitchen, proves that our model significantly outperforms various state-of-the-art techniques.