 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing and Reasoning with Confidence: Supercharging Multimodal LLMs with an Uncertainty-Aware Agentic Framework
Mar 11, 2025Multimodal large language models (MLLMs) show promise in tasks like visual question answering (VQA) but still face challenges in multimodal reasoning. Recent works adapt agentic frameworks or chain-of-thought (CoT) reasoning to improve performance. However, CoT-based multimodal reasoning often demands costly data annotation and fine-tuning, while agentic approaches relying on external tools risk introducing unreliable output from these tools. In this paper, we propose Seeing and Reasoning with Confidence (SRICE), a training-free multimodal reasoning framework that integrates external vision models with uncertainty quantification (UQ) into an MLLM to address these challenges. Specifically, SRICE guides the inference process by allowing MLLM to autonomously select regions of interest through multi-stage interactions with the help of external tools. We propose to use a conformal prediction-based approach to calibrate the output of external tools and select the optimal tool by estimating the uncertainty of an MLLM's output. Our experiment shows that the average improvement of SRICE over the base MLLM is 4.6% on five datasets and the performance on some datasets even outperforms fine-tuning-based methods, revealing the significance of ensuring reliable tool use in an MLLM agent.
Borrowing Treasures from Neighbors: In-Context Learning for Multimodal Learning with Missing Modalities and Data Scarcity
Mar 26, 2024Multimodal machine learning with missing modalities is an increasingly relevant challenge arising in various applications such as healthcare. This paper extends the current research into missing modalities to the low-data regime, i.e., a downstream task has both missing modalities and limited sample size issues. This problem setting is particularly challenging and also practical as it is often expensive to get full-modality data and sufficient annotated training samples. We propose to use retrieval-augmented in-context learning to address these two crucial issues by unleashing the potential of a transformer's in-context learning ability. Diverging from existing methods, which primarily belong to the parametric paradigm and often require sufficient training samples, our work exploits the value of the available full-modality data, offering a novel perspective on resolving the challenge. The proposed data-dependent framework exhibits a higher degree of sample efficiency and is empirically demonstrated to enhance the classification model's performance on both full- and missing-modality data in the low-data regime across various multimodal learning tasks. When only 1% of the training data are available, our proposed method demonstrates an average improvement of 6.1% over a recent strong baseline across various datasets and missing states. Notably, our method also reduces the performance gap between full-modality and missing-modality data compared with the baseline.
HgbNet: predicting hemoglobin level/anemia degree from EHR data
Jan 22, 2024Anemia is a prevalent medical condition that typically requires invasive blood tests for diagnosis and monitoring. Electronic health records (EHRs) have emerged as valuable data sources for numerous medical studies. EHR-based hemoglobin level/anemia degree prediction is non-invasive and rapid but still faces some challenges due to the fact that EHR data is typically an irregular multivariate time series containing a significant number of missing values and irregular time intervals. To address these issues, we introduce HgbNet, a machine learning-based prediction model that emulates clinicians' decision-making processes for hemoglobin level/anemia degree prediction. The model incorporates a NanDense layer with a missing indicator to handle missing values and employs attention mechanisms to account for both local irregularity and global irregularity. We evaluate the proposed method using two real-world datasets across two use cases. In our first use case, we predict hemoglobin level/anemia degree at moment T+1 by utilizing records from moments prior to T+1. In our second use case, we integrate all historical records with additional selected test results at moment T+1 to predict hemoglobin level/anemia degree at the same moment, T+1. HgbNet outperforms the best baseline results across all datasets and use cases. These findings demonstrate the feasibility of estimating hemoglobin levels and anemia degree from EHR data, positioning HgbNet as an effective non-invasive anemia diagnosis solution that could potentially enhance the quality of life for millions of affected individuals worldwide. To our knowledge, HgbNet is the first machine learning model leveraging EHR data for hemoglobin level/anemia degree prediction.
Efficient Approximation of Action Potentials with High-Order Shape Preservation in Unsupervised Spike Sorting
Apr 28, 2022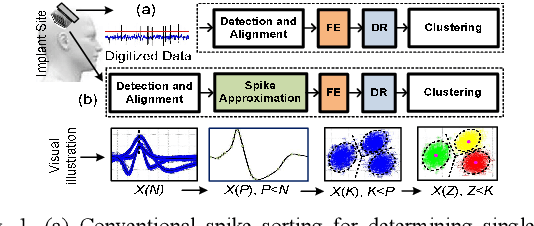


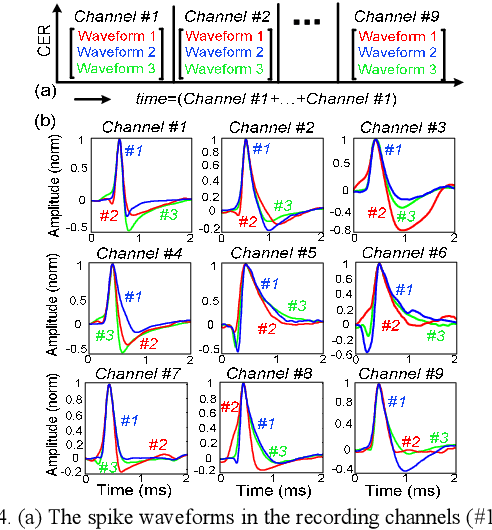
This paper presents a novel approximation unit added to the conventional spike processing chain which provides an appreciable reduction of complexity of the high-hardware cost feature extractors. The use of the Taylor polynomial is proposed and modelled employing its cascaded derivatives to non-uniformly capture the essential samples in each spike for reliable feature extraction and sorting. Inclusion of the approximation unit can provide 3X compression (i.e. from 66 to 22 samples) to the spike waveforms while preserving their shapes. Detailed spike waveform sequences based on in-vivo measurements have been generated using a customized neural simulator for performance assessment of the approximation unit tested on six published feature extractors. For noise levels {\sigma}_N between 0.05 and 0.3 and groups of 3 spikes in each channel, all the feature extractors provide almost same sorting performance before and after approximation. The overall implementation cost when including the approximation unit and feature extraction shows a large reduction (i.e. up to 8.7X) in the hardware costly and more accurate feature extractors, offering a substantial improvement in feature extraction design.