 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Modeling of Photoplethysmography for Non-invasive Monitoring of Cardiovascular Parameters
Nov 18, 2025Continuous cardiovascular monitoring can play a key role in precision health. However, some fundamental cardiac biomarkers of interest, including stroke volume and cardiac output, require invasive measurements, e.g., arterial pressure waveforms (APW). As a non-invasive alternative, photoplethysmography (PPG) measurements are routinely collected in hospital settings. Unfortunately, the prediction of key cardiac biomarkers from PPG instead of APW remains an open challenge, further complicated by the scarcity of annotated PPG measurements. As a solution, we propose a hybrid approach that uses hemodynamic simulations and unlabeled clinical data to estimate cardiovascular biomarkers directly from PPG signals. Our hybrid model combines a conditional variational autoencoder trained on paired PPG-APW data with a conditional density estimator of cardiac biomarkers trained on labeled simulated APW segments. As a key result, our experiments demonstrate that the proposed approach can detect fluctuations of cardiac output and stroke volume and outperform a supervised baseline in monitoring temporal changes in these biomarkers.
Inferring Optical Tissue Properties from Photoplethysmography using Hybrid Amortized Inference
Oct 02, 2025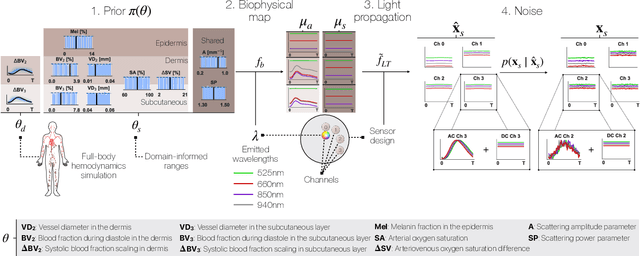
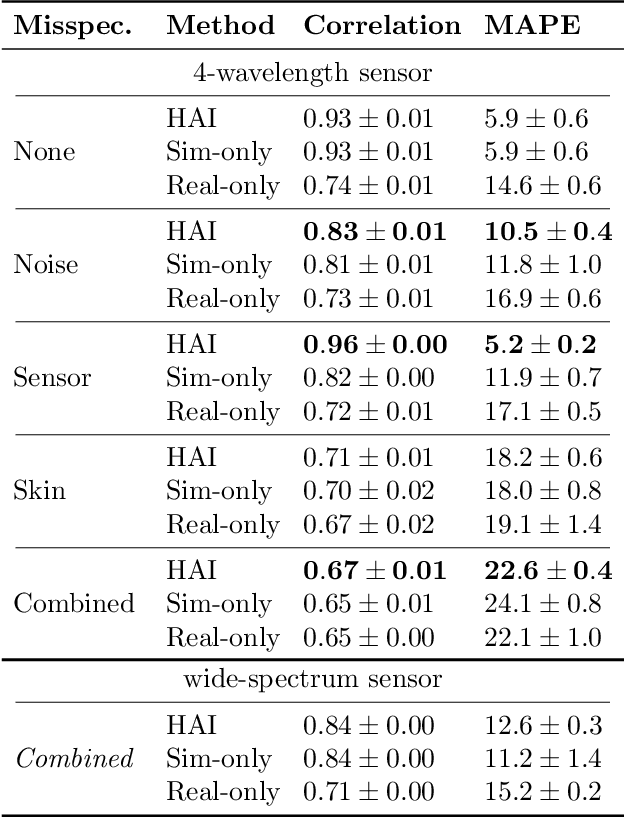
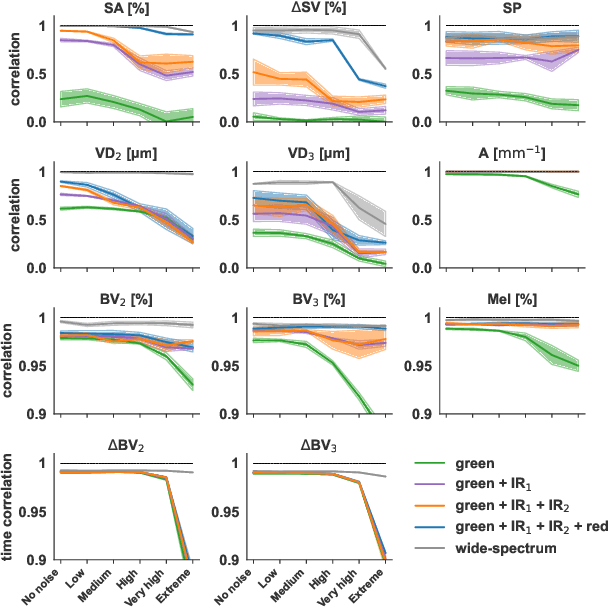

Smart wearables enable continuous tracking of established biomarkers such as heart rate, heart rate variability, and blood oxygen saturation via photoplethysmography (PPG). Beyond these metrics, PPG waveforms contain richer physiological information, as recent deep learning (DL) studies demonstrate. However, DL models often rely on features with unclear physiological meaning, creating a tension between predictive power, clinical interpretability, and sensor design. We address this gap by introducing PPGen, a biophysical model that relates PPG signals to interpretable physiological and optical parameters. Building on PPGen, we propose hybrid amortized inference (HAI), enabling fast, robust, and scalable estimation of relevant physiological parameters from PPG signals while correcting for model misspecification. In extensive in-silico experiments, we show that HAI can accurately infer physiological parameters under diverse noise and sensor conditions. Our results illustrate a path toward PPG models that retain the fidelity needed for DL-based features while supporting clinical interpretation and informed hardware design.
Minimizing Control for Credit Assignment with Strong Feedback
Apr 14, 2022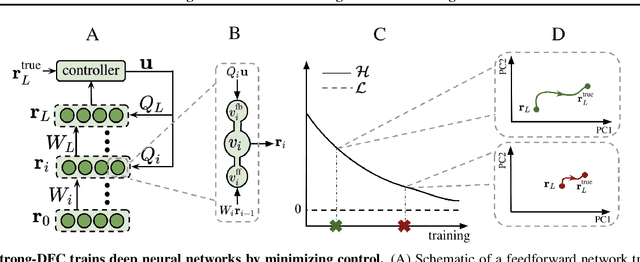

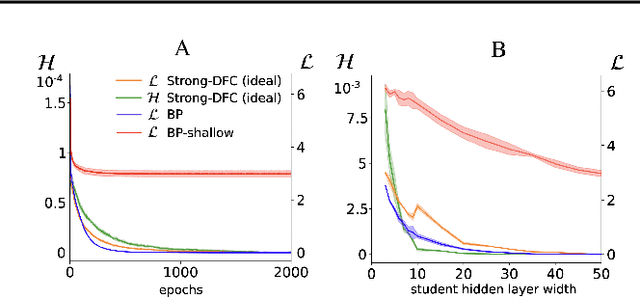
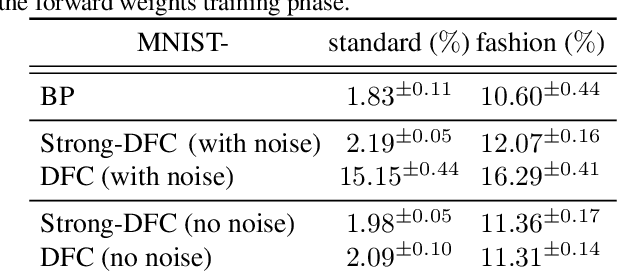
The success of deep learning attracted interest in whether the brain learns hierarchical representations using gradient-based learning. However, current biologically plausible methods for gradient-based credit assignment in deep neural networks need infinitesimally small feedback signals, which is problematic in biologically realistic noisy environments and at odds with experimental evidence in neuroscience showing that top-down feedback can significantly influence neural activity. Building upon deep feedback control (DFC), a recently proposed credit assignment method, we combine strong feedback influences on neural activity with gradient-based learning and show that this naturally leads to a novel view on neural network optimization. Instead of gradually changing the network weights towards configurations with low output loss, weight updates gradually minimize the amount of feedback required from a controller that drives the network to the supervised output label. Moreover, we show that the use of strong feedback in DFC allows learning forward and feedback connections simultaneously, using a learning rule fully local in space and time. We complement our theoretical results with experiments on standard computer-vision benchmarks, showing competitive performance to backpropagation as well as robustness to noise. Overall, our work presents a fundamentally novel view of learning as control minimization, while sidestepping biologically unrealistic assumptions.
Uncertainty estimation under model misspecification in neural network regression
Nov 23, 2021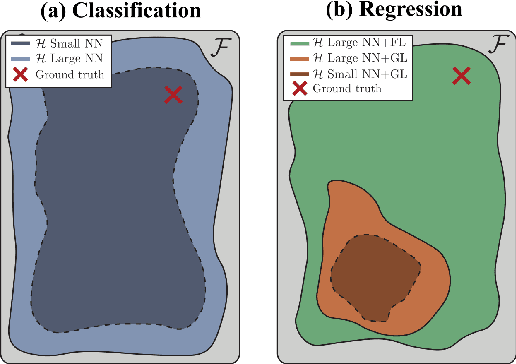
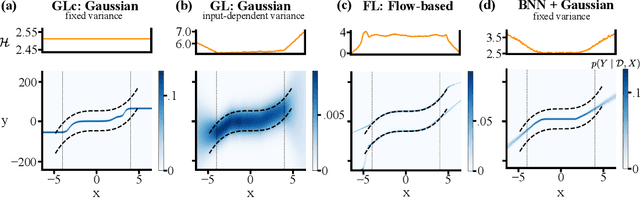

Although neural networks are powerful function approximators, the underlying modelling assumptions ultimately define the likelihood and thus the hypothesis class they are parameterizing. In classification, these assumptions are minimal as the commonly employed softmax is capable of representing any categorical distribution. In regression, however, restrictive assumptions on the type of continuous distribution to be realized are typically placed, like the dominant choice of training via mean-squared error and its underlying Gaussianity assumption. Recently, modelling advances allow to be agnostic to the type of continuous distribution to be modelled, granting regression the flexibility of classification models. While past studies stress the benefit of such flexible regression models in terms of performance, here we study the effect of the model choice on uncertainty estimation. We highlight that under model misspecification, aleatoric uncertainty is not properly captured, and that a Bayesian treatment of a misspecified model leads to unreliable epistemic uncertainty estimates. Overall, our study provides an overview on how modelling choices in regression may influence uncertainty estimation and thus any downstream decision making process.
Posterior Meta-Replay for Continual Learning
Mar 01, 2021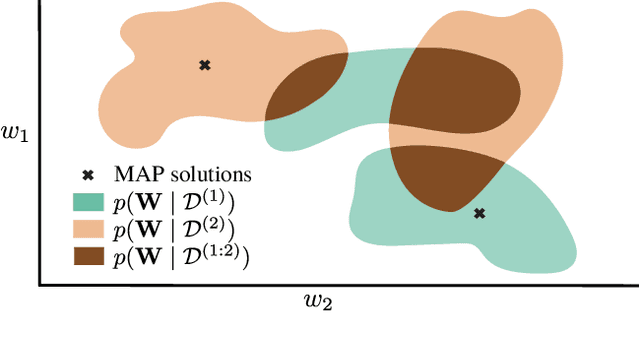
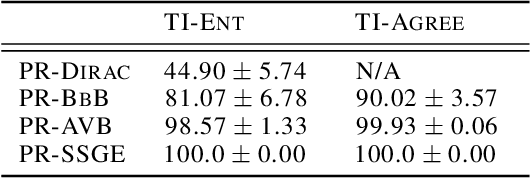
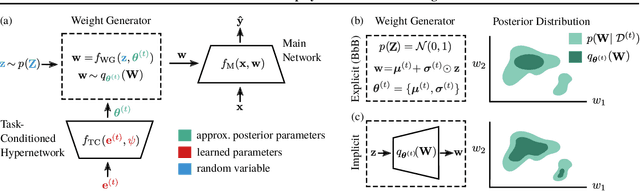
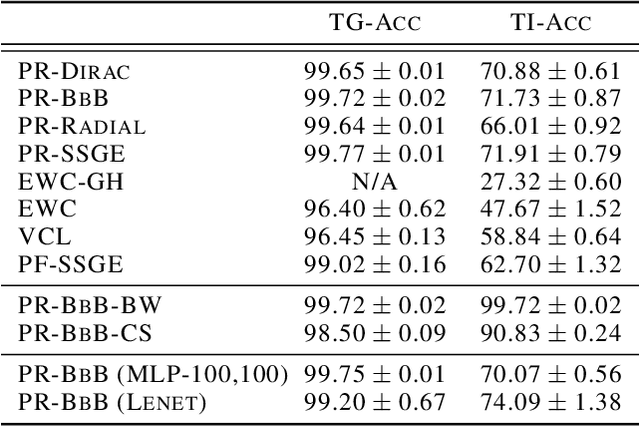
Continual Learning (CL) algorithms have recently received a lot of attention as they attempt to overcome the need to train with an i.i.d. sample from some unknown target data distribution. Building on prior work, we study principled ways to tackle the CL problem by adopting a Bayesian perspective and focus on continually learning a task-specific posterior distribution via a shared meta-model, a task-conditioned hypernetwork. This approach, which we term Posterior-replay CL, is in sharp contrast to most Bayesian CL approaches that focus on the recursive update of a single posterior distribution. The benefits of our approach are (1) an increased flexibility to model solutions in weight space and therewith less susceptibility to task dissimilarity, (2) access to principled task-specific predictive uncertainty estimates, that can be used to infer task identity during test time and to detect task boundaries during training, and (3) the ability to revisit and update task-specific posteriors in a principled manner without requiring access to past data. The proposed framework is versatile, which we demonstrate using simple posterior approximations (such as Gaussians) as well as powerful, implicit distributions modelled via a neural network. We illustrate the conceptual advance of our framework on low-dimensional problems and show performance gains on computer vision benchmarks.
Continual Learning in Recurrent Neural Networks with Hypernetworks
Jun 22, 2020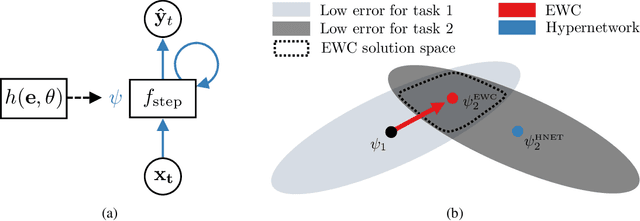
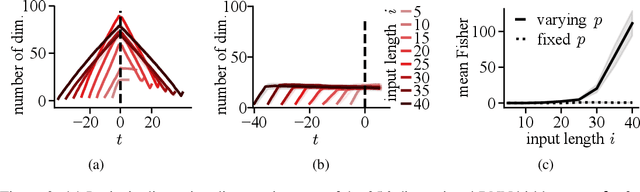
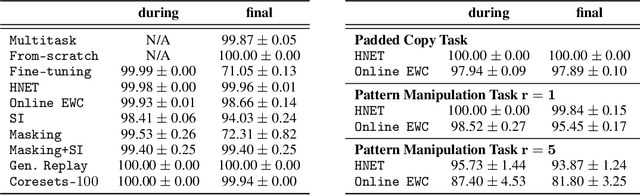
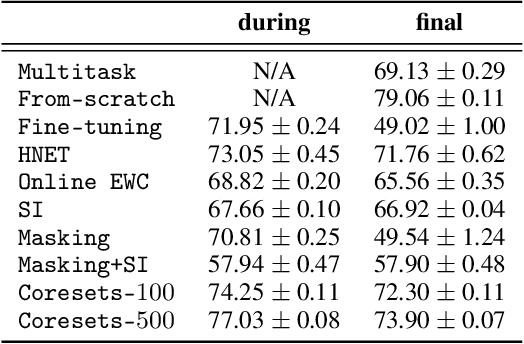
The last decade has seen a surge of interest in continual learning (CL), and a variety of methods have been developed to alleviate catastrophic forgetting. However, most prior work has focused on tasks with static data, while CL on sequential data has remained largely unexplored. Here we address this gap in two ways. First, we evaluate the performance of established CL methods when applied to recurrent neural networks (RNNs). We primarily focus on elastic weight consolidation, which is limited by a stability-plasticity trade-off, and explore the particularities of this trade-off when using sequential data. We show that high working memory requirements, but not necessarily sequence length, lead to an increased need for stability at the cost of decreased performance on subsequent tasks. Second, to overcome this limitation we employ a recent method based on hypernetworks and apply it to RNNs to address catastrophic forgetting on sequential data. By generating the weights of a main RNN in a task-dependent manner, our approach disentangles stability and plasticity, and outperforms alternative methods in a range of experiments. Overall, our work provides several key insights on the differences between CL in feedforward networks and in RNNs, while offering a novel solution to effectively tackle CL on sequential data.