 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty estimation under model misspecification in neural network regression
Nov 23, 2021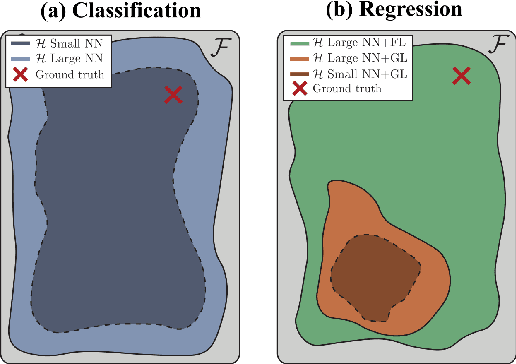
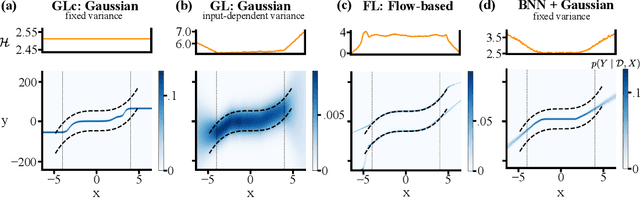

Although neural networks are powerful function approximators, the underlying modelling assumptions ultimately define the likelihood and thus the hypothesis class they are parameterizing. In classification, these assumptions are minimal as the commonly employed softmax is capable of representing any categorical distribution. In regression, however, restrictive assumptions on the type of continuous distribution to be realized are typically placed, like the dominant choice of training via mean-squared error and its underlying Gaussianity assumption. Recently, modelling advances allow to be agnostic to the type of continuous distribution to be modelled, granting regression the flexibility of classification models. While past studies stress the benefit of such flexible regression models in terms of performance, here we study the effect of the model choice on uncertainty estimation. We highlight that under model misspecification, aleatoric uncertainty is not properly captured, and that a Bayesian treatment of a misspecified model leads to unreliable epistemic uncertainty estimates. Overall, our study provides an overview on how modelling choices in regression may influence uncertainty estimation and thus any downstream decision making process.
Uncertainty-based out-of-distribution detection requires suitable function space priors
Oct 12, 2021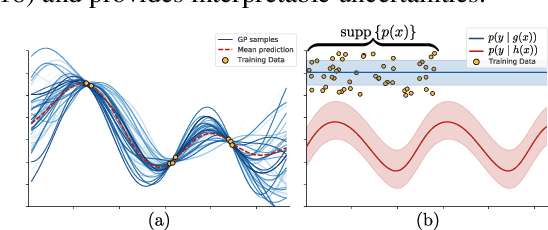

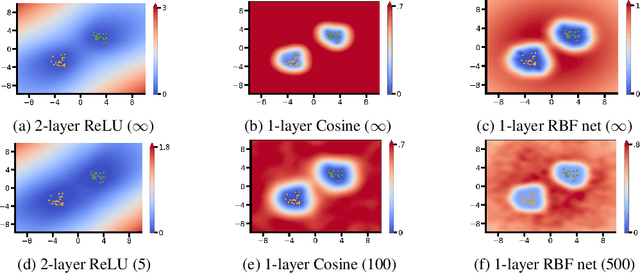
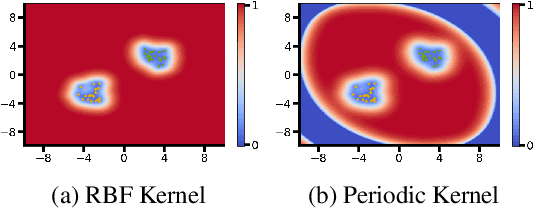
The need to avoid confident predictions on unfamiliar data has sparked interest in out-of-distribution (OOD) detection. It is widely assumed that Bayesian neural networks (BNNs) are well suited for this task, as the endowed epistemic uncertainty should lead to disagreement in predictions on outliers. In this paper, we question this assumption and show that proper Bayesian inference with function space priors induced by neural networks does not necessarily lead to good OOD detection. To circumvent the use of approximate inference, we start by studying the infinite-width case, where Bayesian inference can be exact due to the correspondence with Gaussian processes. Strikingly, the kernels induced under common architectural choices lead to uncertainties that do not reflect the underlying data generating process and are therefore unsuited for OOD detection. Importantly, we find this OOD behavior to be consistent with the corresponding finite-width networks. Desirable function space properties can be encoded in the prior in weight space, however, this currently only applies to a specified subset of the domain and thus does not inherently extend to OOD data. Finally, we argue that a trade-off between generalization and OOD capabilities might render the application of BNNs for OOD detection undesirable in practice. Overall, our study discloses fundamental problems when naively using BNNs for OOD detection and opens interesting avenues for future research.
Are Bayesian neural networks intrinsically good at out-of-distribution detection?
Jul 26, 2021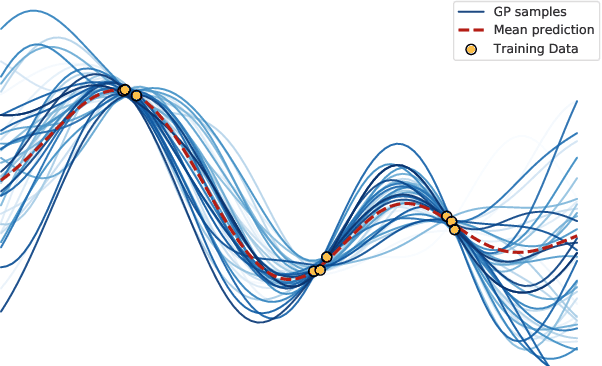

The need to avoid confident predictions on unfamiliar data has sparked interest in out-of-distribution (OOD) detection. It is widely assumed that Bayesian neural networks (BNN) are well suited for this task, as the endowed epistemic uncertainty should lead to disagreement in predictions on outliers. In this paper, we question this assumption and provide empirical evidence that proper Bayesian inference with common neural network architectures does not necessarily lead to good OOD detection. To circumvent the use of approximate inference, we start by studying the infinite-width case, where Bayesian inference can be exact considering the corresponding Gaussian process. Strikingly, the kernels induced under common architectural choices lead to uncertainties that do not reflect the underlying data generating process and are therefore unsuited for OOD detection. Finally, we study finite-width networks using HMC, and observe OOD behavior that is consistent with the infinite-width case. Overall, our study discloses fundamental problems when naively using BNNs for OOD detection and opens interesting avenues for future research.
Posterior Meta-Replay for Continual Learning
Mar 01, 2021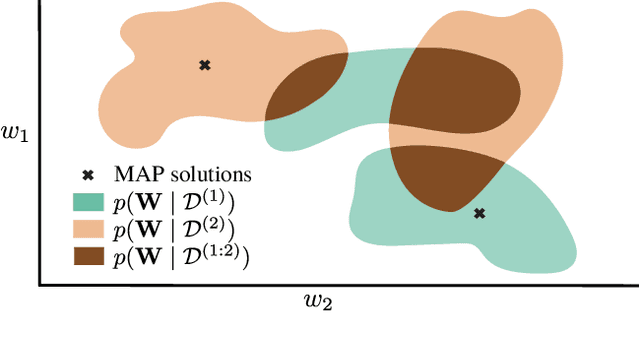
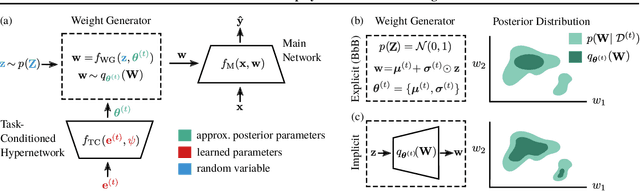
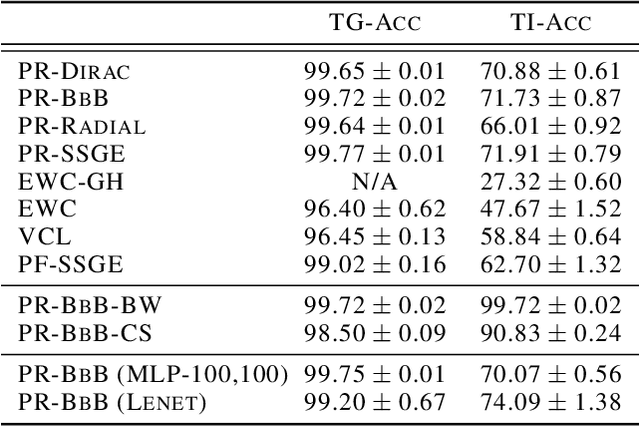
Continual Learning (CL) algorithms have recently received a lot of attention as they attempt to overcome the need to train with an i.i.d. sample from some unknown target data distribution. Building on prior work, we study principled ways to tackle the CL problem by adopting a Bayesian perspective and focus on continually learning a task-specific posterior distribution via a shared meta-model, a task-conditioned hypernetwork. This approach, which we term Posterior-replay CL, is in sharp contrast to most Bayesian CL approaches that focus on the recursive update of a single posterior distribution. The benefits of our approach are (1) an increased flexibility to model solutions in weight space and therewith less susceptibility to task dissimilarity, (2) access to principled task-specific predictive uncertainty estimates, that can be used to infer task identity during test time and to detect task boundaries during training, and (3) the ability to revisit and update task-specific posteriors in a principled manner without requiring access to past data. The proposed framework is versatile, which we demonstrate using simple posterior approximations (such as Gaussians) as well as powerful, implicit distributions modelled via a neural network. We illustrate the conceptual advance of our framework on low-dimensional problems and show performance gains on computer vision benchmarks.
Economical ensembles with hypernetworks
Jul 25, 2020



Averaging the predictions of many independently trained neural networks is a simple and effective way of improving generalization in deep learning. However, this strategy rapidly becomes costly, as the number of trainable parameters grows linearly with the size of the ensemble. Here, we propose a new method to learn economical ensembles, where the number of trainable parameters and iterations over the data is comparable to that of a single model. Our neural networks are parameterized by hypernetworks, which learn to embed weights in low-dimensional spaces. In a late training phase, we generate an ensemble by randomly initializing an additional number of weight embeddings in the vicinity of each other. We then exploit the inherent randomness in stochastic gradient descent to induce ensemble diversity. Experiments with wide residual networks on the CIFAR and Fashion-MNIST datasets show that our algorithm yields models that are more accurate and less overconfident on unseen data, while learning as efficiently as a single network.
Continual Learning in Recurrent Neural Networks with Hypernetworks
Jun 22, 2020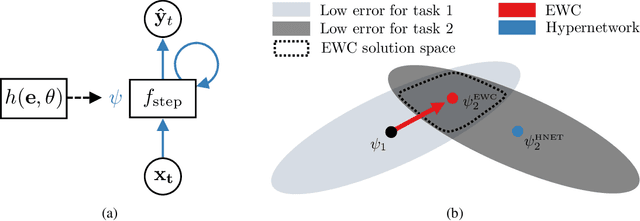
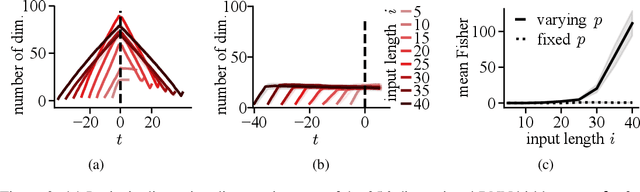
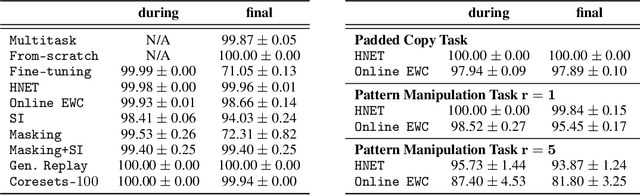
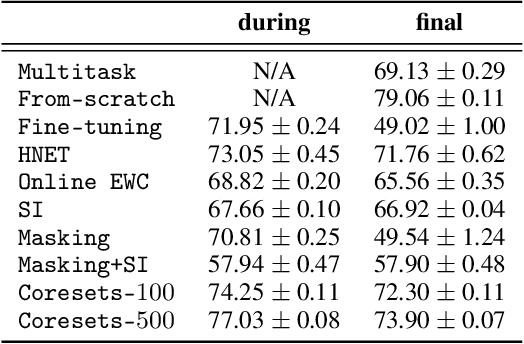
The last decade has seen a surge of interest in continual learning (CL), and a variety of methods have been developed to alleviate catastrophic forgetting. However, most prior work has focused on tasks with static data, while CL on sequential data has remained largely unexplored. Here we address this gap in two ways. First, we evaluate the performance of established CL methods when applied to recurrent neural networks (RNNs). We primarily focus on elastic weight consolidation, which is limited by a stability-plasticity trade-off, and explore the particularities of this trade-off when using sequential data. We show that high working memory requirements, but not necessarily sequence length, lead to an increased need for stability at the cost of decreased performance on subsequent tasks. Second, to overcome this limitation we employ a recent method based on hypernetworks and apply it to RNNs to address catastrophic forgetting on sequential data. By generating the weights of a main RNN in a task-dependent manner, our approach disentangles stability and plasticity, and outperforms alternative methods in a range of experiments. Overall, our work provides several key insights on the differences between CL in feedforward networks and in RNNs, while offering a novel solution to effectively tackle CL on sequential data.
Continual learning with hypernetworks
Jun 03, 2019



Artificial neural networks suffer from catastrophic forgetting when they are sequentially trained on multiple tasks. To overcome this problem, we present a novel approach based on task-conditioned hypernetworks, i.e., networks that generate the weights of a target model based on task identity. Continual learning (CL) is less difficult for this class of models thanks to a simple key observation: instead of relying on recalling the input-output relations of all previously seen data, task-conditioned hypernetworks only require rehearsing previous weight realizations, which can be maintained in memory using a simple regularizer. Besides achieving good performance on standard CL benchmarks, additional experiments on long task sequences reveal that task-conditioned hypernetworks display an unprecedented capacity to retain previous memories. Notably, such long memory lifetimes are achieved in a compressive regime, when the number of trainable weights is comparable or smaller than target network size. We provide insight into the structure of low-dimensional task embedding spaces (the input space of the hypernetwork) and show that task-conditioned hypernetworks demonstrate transfer learning properties. Finally, forward information transfer is further supported by empirical results on a challenging CL benchmark based on the CIFAR-10/100 image datasets.