 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Meta-Replay for Continual Learning
Mar 01, 2021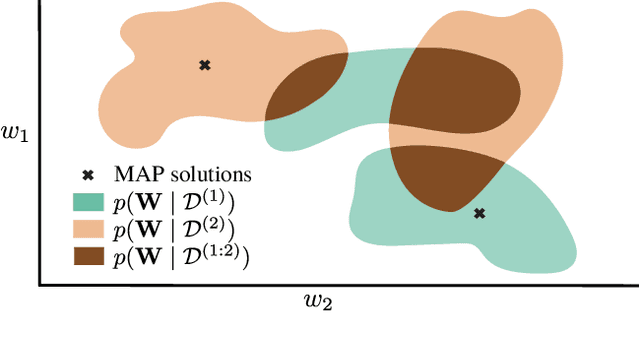
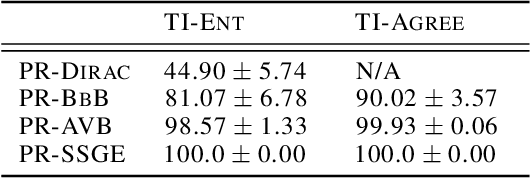
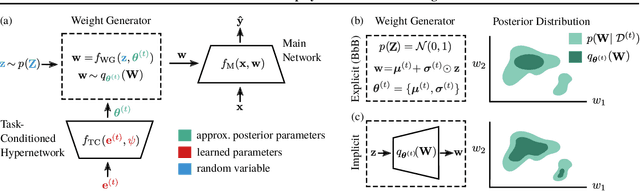
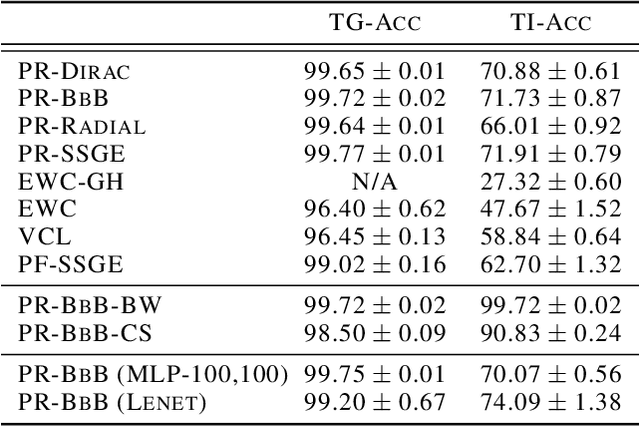
Continual Learning (CL) algorithms have recently received a lot of attention as they attempt to overcome the need to train with an i.i.d. sample from some unknown target data distribution. Building on prior work, we study principled ways to tackle the CL problem by adopting a Bayesian perspective and focus on continually learning a task-specific posterior distribution via a shared meta-model, a task-conditioned hypernetwork. This approach, which we term Posterior-replay CL, is in sharp contrast to most Bayesian CL approaches that focus on the recursive update of a single posterior distribution. The benefits of our approach are (1) an increased flexibility to model solutions in weight space and therewith less susceptibility to task dissimilarity, (2) access to principled task-specific predictive uncertainty estimates, that can be used to infer task identity during test time and to detect task boundaries during training, and (3) the ability to revisit and update task-specific posteriors in a principled manner without requiring access to past data. The proposed framework is versatile, which we demonstrate using simple posterior approximations (such as Gaussians) as well as powerful, implicit distributions modelled via a neural network. We illustrate the conceptual advance of our framework on low-dimensional problems and show performance gains on computer vision benchmarks.
Continual Learning in Recurrent Neural Networks with Hypernetworks
Jun 22, 2020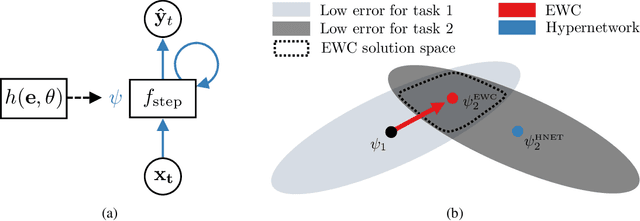
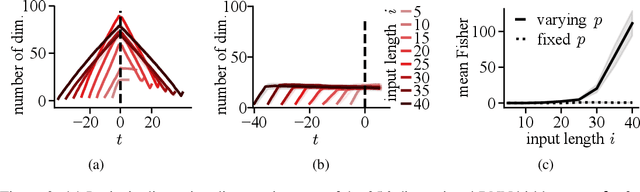
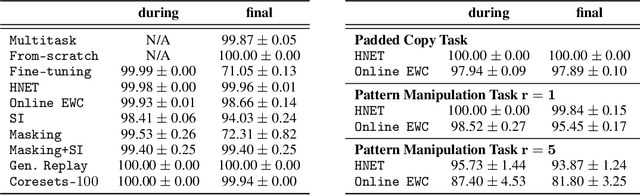
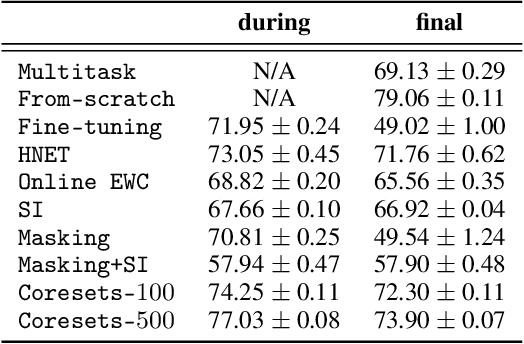
The last decade has seen a surge of interest in continual learning (CL), and a variety of methods have been developed to alleviate catastrophic forgetting. However, most prior work has focused on tasks with static data, while CL on sequential data has remained largely unexplored. Here we address this gap in two ways. First, we evaluate the performance of established CL methods when applied to recurrent neural networks (RNNs). We primarily focus on elastic weight consolidation, which is limited by a stability-plasticity trade-off, and explore the particularities of this trade-off when using sequential data. We show that high working memory requirements, but not necessarily sequence length, lead to an increased need for stability at the cost of decreased performance on subsequent tasks. Second, to overcome this limitation we employ a recent method based on hypernetworks and apply it to RNNs to address catastrophic forgetting on sequential data. By generating the weights of a main RNN in a task-dependent manner, our approach disentangles stability and plasticity, and outperforms alternative methods in a range of experiments. Overall, our work provides several key insights on the differences between CL in feedforward networks and in RNNs, while offering a novel solution to effectively tackle CL on sequential data.