 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Biologically Plausible Adversarial Training
Oct 05, 2023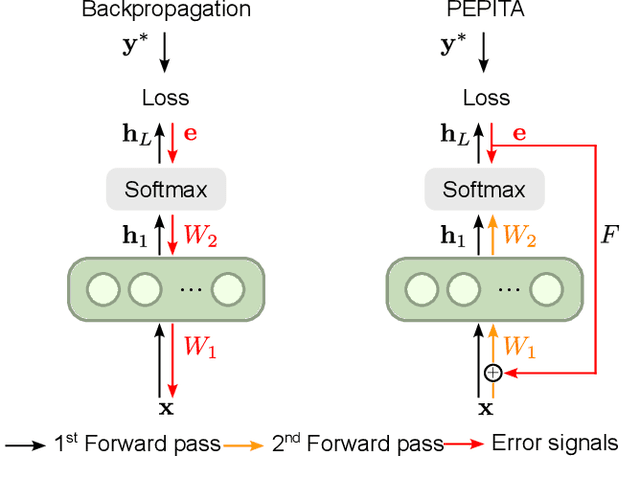


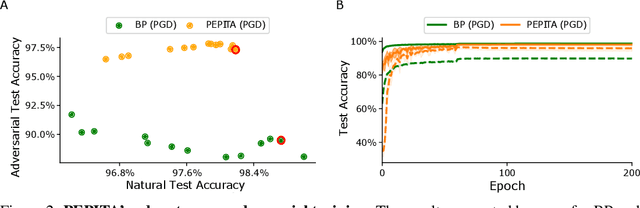
Artificial Neural Networks (ANNs) trained with Backpropagation (BP) show astounding performance and are increasingly often used in performing our daily life tasks. However, ANNs are highly vulnerable to adversarial attacks, which alter inputs with small targeted perturbations that drastically disrupt the models' performance. The most effective method to make ANNs robust against these attacks is adversarial training, in which the training dataset is augmented with exemplary adversarial samples. Unfortunately, this approach has the drawback of increased training complexity since generating adversarial samples is very computationally demanding. In contrast to ANNs, humans are not susceptible to adversarial attacks. Therefore, in this work, we investigate whether biologically-plausible learning algorithms are more robust against adversarial attacks than BP. In particular, we present an extensive comparative analysis of the adversarial robustness of BP and Present the Error to Perturb the Input To modulate Activity (PEPITA), a recently proposed biologically-plausible learning algorithm, on various computer vision tasks. We observe that PEPITA has higher intrinsic adversarial robustness and, with adversarial training, has a more favourable natural-vs-adversarial performance trade-off as, for the same natural accuracies, PEPITA's adversarial accuracies decrease in average by 0.26% and BP's by 8.05%.
Minimizing Control for Credit Assignment with Strong Feedback
Apr 14, 2022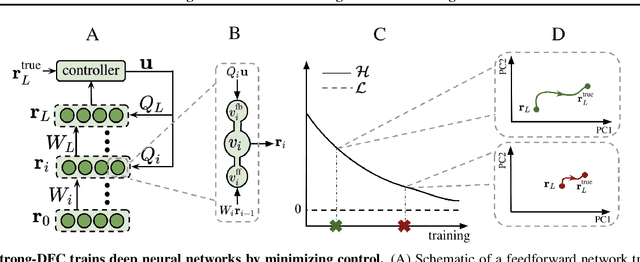

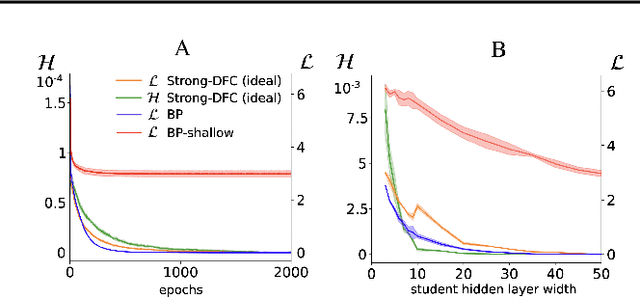
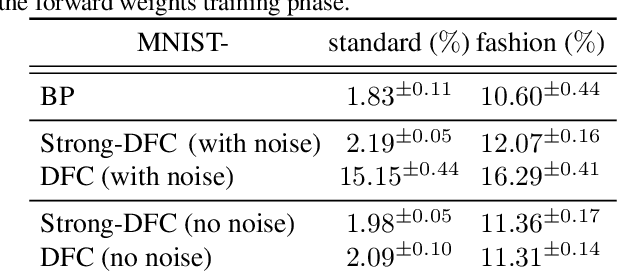
The success of deep learning attracted interest in whether the brain learns hierarchical representations using gradient-based learning. However, current biologically plausible methods for gradient-based credit assignment in deep neural networks need infinitesimally small feedback signals, which is problematic in biologically realistic noisy environments and at odds with experimental evidence in neuroscience showing that top-down feedback can significantly influence neural activity. Building upon deep feedback control (DFC), a recently proposed credit assignment method, we combine strong feedback influences on neural activity with gradient-based learning and show that this naturally leads to a novel view on neural network optimization. Instead of gradually changing the network weights towards configurations with low output loss, weight updates gradually minimize the amount of feedback required from a controller that drives the network to the supervised output label. Moreover, we show that the use of strong feedback in DFC allows learning forward and feedback connections simultaneously, using a learning rule fully local in space and time. We complement our theoretical results with experiments on standard computer-vision benchmarks, showing competitive performance to backpropagation as well as robustness to noise. Overall, our work presents a fundamentally novel view of learning as control minimization, while sidestepping biologically unrealistic assumptions.
Credit Assignment in Neural Networks through Deep Feedback Control
Jun 15, 2021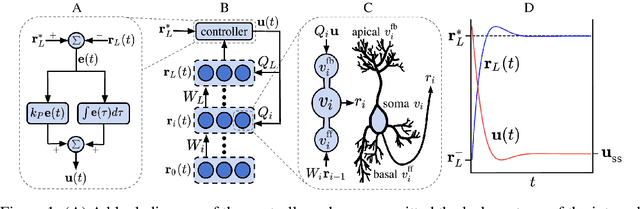
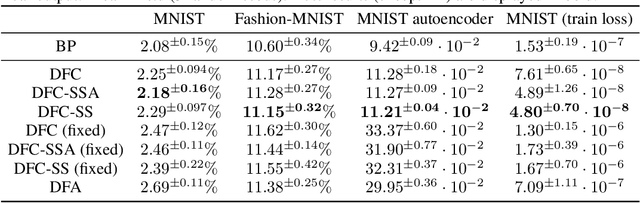
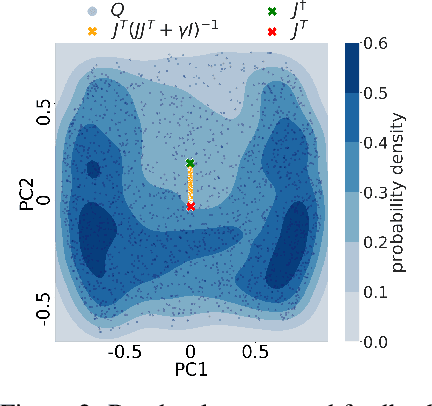
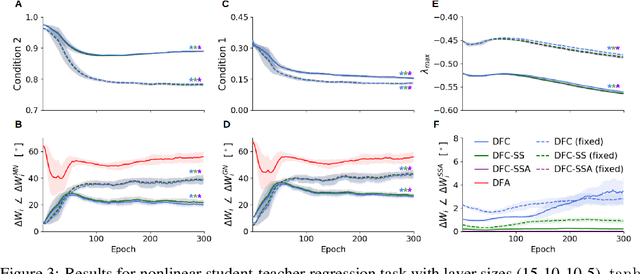
The success of deep learning sparked interest in whether the brain learns by using similar techniques for assigning credit to each synaptic weight for its contribution to the network output. However, the majority of current attempts at biologically-plausible learning methods are either non-local in time, require highly specific connectivity motives, or have no clear link to any known mathematical optimization method. Here, we introduce Deep Feedback Control (DFC), a new learning method that uses a feedback controller to drive a deep neural network to match a desired output target and whose control signal can be used for credit assignment. The resulting learning rule is fully local in space and time and approximates Gauss-Newton optimization for a wide range of feedback connectivity patterns. To further underline its biological plausibility, we relate DFC to a multi-compartment model of cortical pyramidal neurons with a local voltage-dependent synaptic plasticity rule, consistent with recent theories of dendritic processing. By combining dynamical system theory with mathematical optimization theory, we provide a strong theoretical foundation for DFC that we corroborate with detailed results on toy experiments and standard computer-vision benchmarks.
Equilibrium Propagation for Complete Directed Neural Networks
Jun 17, 2020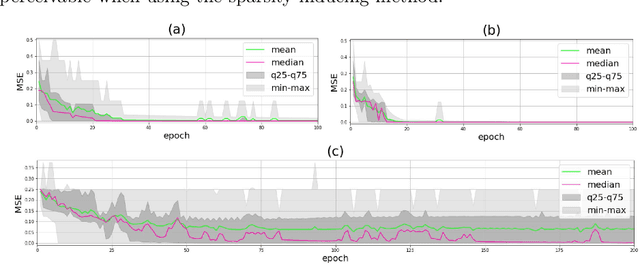

Artificial neural networks, one of the most successful approaches to supervised learning, were originally inspired by their biological counterparts. However, the most successful learning algorithm for artificial neural networks, backpropagation, is considered biologically implausible. We contribute to the topic of biologically plausible neuronal learning by building upon and extending the equilibrium propagation learning framework. Specifically, we introduce: a new neuronal dynamics and learning rule for arbitrary network architectures; a sparsity-inducing method able to prune irrelevant connections; a dynamical-systems characterization of the models, using Lyapunov theory.