 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning through Control Minimization
Feb 04, 2026Catastrophic forgetting remains a fundamental challenge for neural networks when tasks are trained sequentially. In this work, we reformulate continual learning as a control problem where learning and preservation signals compete within neural activity dynamics. We convert regularization penalties into preservation signals that protect prior-task representations. Learning then proceeds by minimizing the control effort required to integrate new tasks while competing with the preservation of prior tasks. At equilibrium, the neural activities produce weight updates that implicitly encode the full prior-task curvature, a property we term the continual-natural gradient, requiring no explicit curvature storage. Experiments confirm that our learning framework recovers true prior-task curvature and enables task discrimination, outperforming existing methods on standard benchmarks without replay.
Temporal horizons in forecasting: a performance-learnability trade-off
Jun 04, 2025



When training autoregressive models for dynamical systems, a critical question arises: how far into the future should the model be trained to predict? Too short a horizon may miss long-term trends, while too long a horizon can impede convergence due to accumulating prediction errors. In this work, we formalize this trade-off by analyzing how the geometry of the loss landscape depends on the training horizon. We prove that for chaotic systems, the loss landscape's roughness grows exponentially with the training horizon, while for limit cycles, it grows linearly, making long-horizon training inherently challenging. However, we also show that models trained on long horizons generalize well to short-term forecasts, whereas those trained on short horizons suffer exponentially (resp. linearly) worse long-term predictions in chaotic (resp. periodic) systems. We validate our theory through numerical experiments and discuss practical implications for selecting training horizons. Our results provide a principled foundation for hyperparameter optimization in autoregressive forecasting models.
The Role of Temporal Hierarchy in Spiking Neural Networks
Jul 26, 2024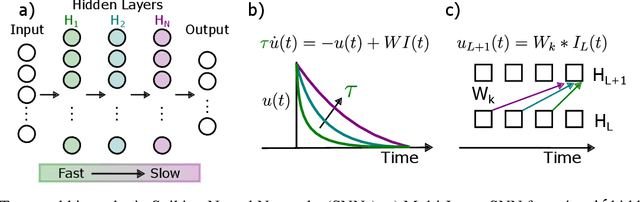
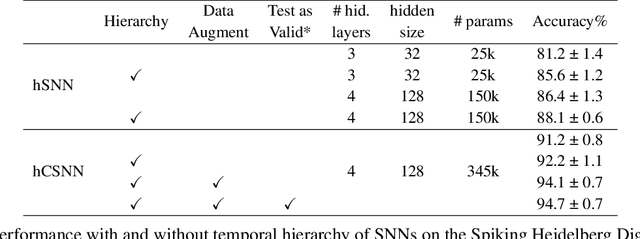
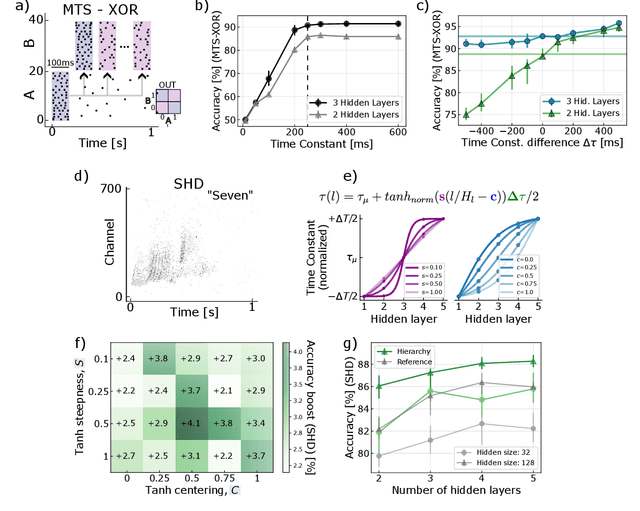

Spiking Neural Networks (SNNs) have the potential for rich spatio-temporal signal processing thanks to exploiting both spatial and temporal parameters. The temporal dynamics such as time constants of the synapses and neurons and delays have been recently shown to have computational benefits that help reduce the overall number of parameters required in the network and increase the accuracy of the SNNs in solving temporal tasks. Optimizing such temporal parameters, for example, through gradient descent, gives rise to a temporal architecture for different problems. As has been shown in machine learning, to reduce the cost of optimization, architectural biases can be applied, in this case in the temporal domain. Such inductive biases in temporal parameters have been found in neuroscience studies, highlighting a hierarchy of temporal structure and input representation in different layers of the cortex. Motivated by this, we propose to impose a hierarchy of temporal representation in the hidden layers of SNNs, highlighting that such an inductive bias improves their performance. We demonstrate the positive effects of temporal hierarchy in the time constants of feed-forward SNNs applied to temporal tasks (Multi-Time-Scale XOR and Keyword Spotting, with a benefit of up to 4.1% in classification accuracy). Moreover, we show that such architectural biases, i.e. hierarchy of time constants, naturally emerge when optimizing the time constants through gradient descent, initialized as homogeneous values. We further pursue this proposal in temporal convolutional SNNs, by introducing the hierarchical bias in the size and dilation of temporal kernels, giving rise to competitive results in popular temporal spike-based datasets.
Bio-Inspired, Task-Free Continual Learning through Activity Regularization
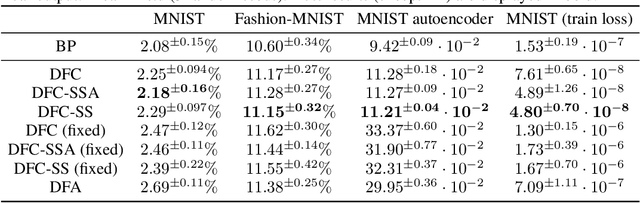
Dec 08, 2022The ability to sequentially learn multiple tasks without forgetting is a key skill of biological brains, whereas it represents a major challenge to the field of deep learning. To avoid catastrophic forgetting, various continual learning (CL) approaches have been devised. However, these usually require discrete task boundaries. This requirement seems biologically implausible and often limits the application of CL methods in the real world where tasks are not always well defined. Here, we take inspiration from neuroscience, where sparse, non-overlapping neuronal representations have been suggested to prevent catastrophic forgetting. As in the brain, we argue that these sparse representations should be chosen on the basis of feed forward (stimulus-specific) as well as top-down (context-specific) information. To implement such selective sparsity, we use a bio-plausible form of hierarchical credit assignment known as Deep Feedback Control (DFC) and combine it with a winner-take-all sparsity mechanism. In addition to sparsity, we introduce lateral recurrent connections within each layer to further protect previously learned representations. We evaluate the new sparse-recurrent version of DFC on the split-MNIST computer vision benchmark and show that only the combination of sparsity and intra-layer recurrent connections improves CL performance with respect to standard backpropagation. Our method achieves similar performance to well-known CL methods, such as Elastic Weight Consolidation and Synaptic Intelligence, without requiring information about task boundaries. Overall, we showcase the idea of adopting computational principles from the brain to derive new, task-free learning algorithms for CL.
Disentangling the Predictive Variance of Deep Ensembles through the Neural Tangent Kernel
Oct 18, 2022

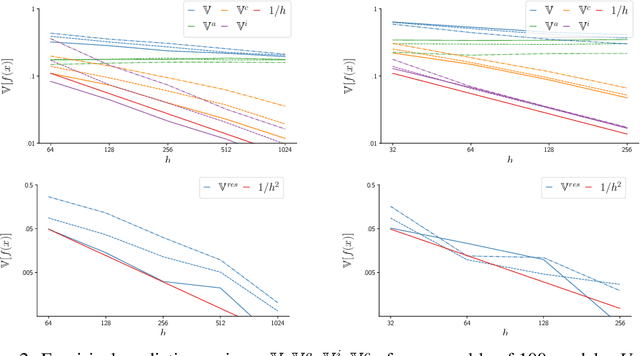
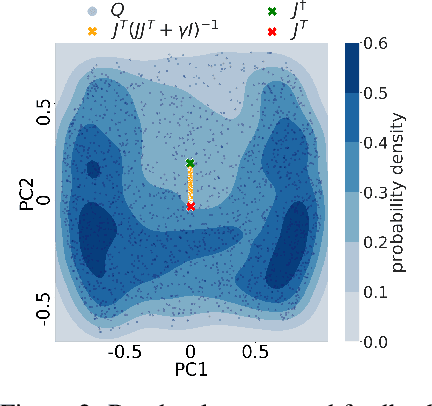
Identifying unfamiliar inputs, also known as out-of-distribution (OOD) detection, is a crucial property of any decision making process. A simple and empirically validated technique is based on deep ensembles where the variance of predictions over different neural networks acts as a substitute for input uncertainty. Nevertheless, a theoretical understanding of the inductive biases leading to the performance of deep ensemble's uncertainty estimation is missing. To improve our description of their behavior, we study deep ensembles with large layer widths operating in simplified linear training regimes, in which the functions trained with gradient descent can be described by the neural tangent kernel. We identify two sources of noise, each inducing a distinct inductive bias in the predictive variance at initialization. We further show theoretically and empirically that both noise sources affect the predictive variance of non-linear deep ensembles in toy models and realistic settings after training. Finally, we propose practical ways to eliminate part of these noise sources leading to significant changes and improved OOD detection in trained deep ensembles.
Credit Assignment in Neural Networks through Deep Feedback Control
Jun 15, 2021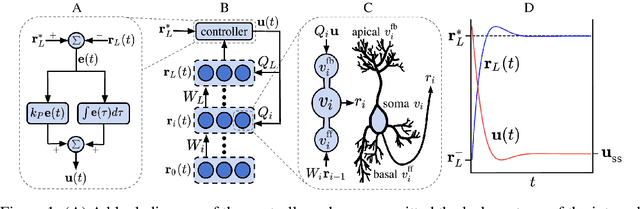
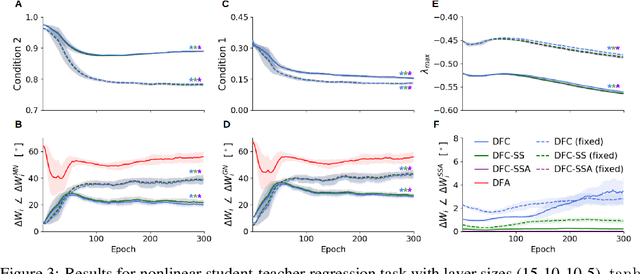
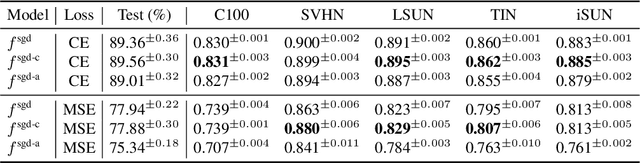
The success of deep learning sparked interest in whether the brain learns by using similar techniques for assigning credit to each synaptic weight for its contribution to the network output. However, the majority of current attempts at biologically-plausible learning methods are either non-local in time, require highly specific connectivity motives, or have no clear link to any known mathematical optimization method. Here, we introduce Deep Feedback Control (DFC), a new learning method that uses a feedback controller to drive a deep neural network to match a desired output target and whose control signal can be used for credit assignment. The resulting learning rule is fully local in space and time and approximates Gauss-Newton optimization for a wide range of feedback connectivity patterns. To further underline its biological plausibility, we relate DFC to a multi-compartment model of cortical pyramidal neurons with a local voltage-dependent synaptic plasticity rule, consistent with recent theories of dendritic processing. By combining dynamical system theory with mathematical optimization theory, we provide a strong theoretical foundation for DFC that we corroborate with detailed results on toy experiments and standard computer-vision benchmarks.
Tailoring Artificial Neural Networks for Optimal Learning
Jul 08, 2017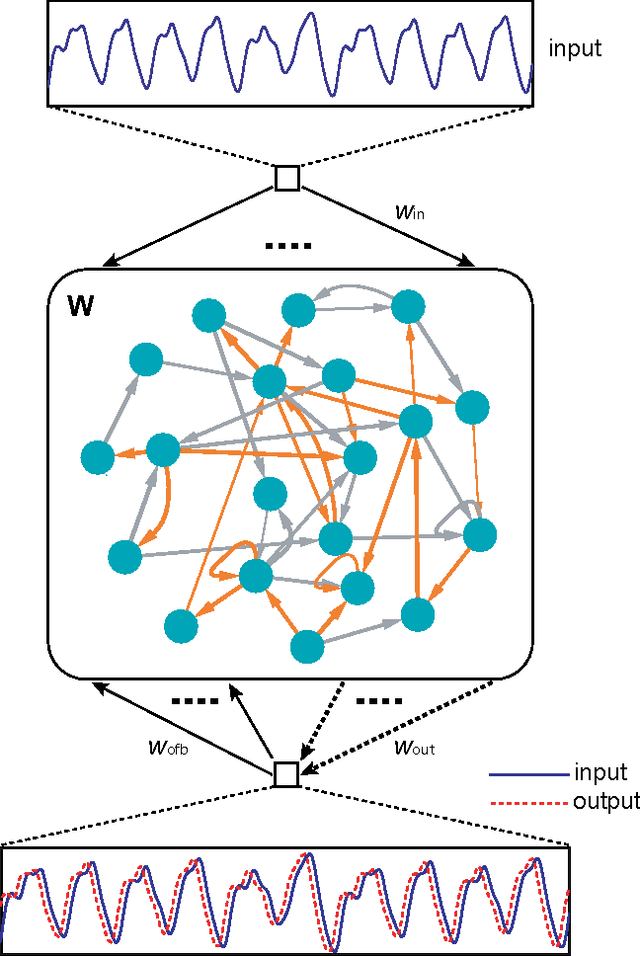
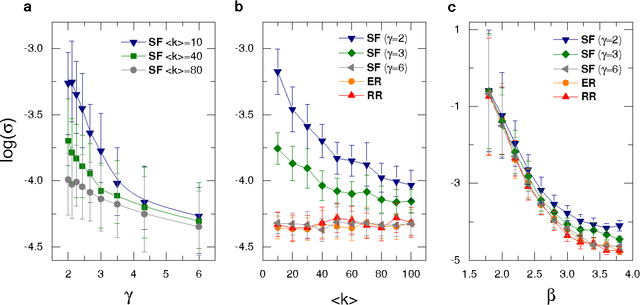
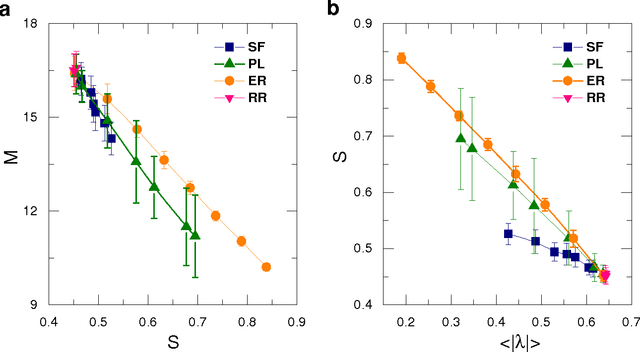
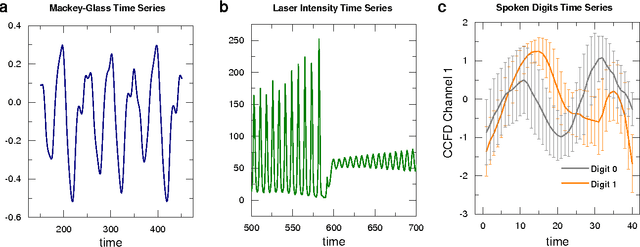
As one of the most important paradigms of recurrent neural networks, the echo state network (ESN) has been applied to a wide range of fields, from robotics to medicine to finance, and language processing. A key feature of the ESN paradigm is its reservoir ---a directed and weighted network--- that represents the connections between neurons and projects the input signals into a high dimensional space. Despite extensive studies, the impact of the reservoir network on the ESN performance remains unclear. Here we systematically address this fundamental question. Through spectral analysis of the reservoir network we reveal a key factor that largely determines the ESN memory capacity and hence affects its performance. Moreover, we find that adding short loops to the reservoir network can tailor ESN for specific tasks and optimal learning. We validate our findings by applying ESN to forecast both synthetic and real benchmark time series. Our results provide a new way to design task-specific recurrent neural networks, as well as new insights in understanding complex networked systems.