 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward Learning with Top-Down Feedback: Empirical and Analytical Characterization
Feb 10, 2023



"Forward-only" algorithms, which train neural networks while avoiding a backward pass, have recently gained attention as a way of solving the biologically unrealistic aspects of backpropagation. Here, we first discuss the similarities between two "forward-only" algorithms, the Forward-Forward and PEPITA frameworks, and demonstrate that PEPITA is equivalent to a Forward-Forward with top-down feedback connections. Then, we focus on PEPITA to address compelling challenges related to the "forward-only" rules, which include providing an analytical understanding of their dynamics and reducing the gap between their performance and that of backpropagation. We propose a theoretical analysis of the dynamics of PEPITA. In particular, we show that PEPITA is well-approximated by an "adaptive-feedback-alignment" algorithm and we analytically track its performance during learning in a prototype high-dimensional setting. Finally, we develop a strategy to apply the weight mirroring algorithm on "forward-only" algorithms with top-down feedback and we show how it impacts PEPITA's accuracy and convergence rate.
Bio-Inspired, Task-Free Continual Learning through Activity Regularization
Dec 08, 2022The ability to sequentially learn multiple tasks without forgetting is a key skill of biological brains, whereas it represents a major challenge to the field of deep learning. To avoid catastrophic forgetting, various continual learning (CL) approaches have been devised. However, these usually require discrete task boundaries. This requirement seems biologically implausible and often limits the application of CL methods in the real world where tasks are not always well defined. Here, we take inspiration from neuroscience, where sparse, non-overlapping neuronal representations have been suggested to prevent catastrophic forgetting. As in the brain, we argue that these sparse representations should be chosen on the basis of feed forward (stimulus-specific) as well as top-down (context-specific) information. To implement such selective sparsity, we use a bio-plausible form of hierarchical credit assignment known as Deep Feedback Control (DFC) and combine it with a winner-take-all sparsity mechanism. In addition to sparsity, we introduce lateral recurrent connections within each layer to further protect previously learned representations. We evaluate the new sparse-recurrent version of DFC on the split-MNIST computer vision benchmark and show that only the combination of sparsity and intra-layer recurrent connections improves CL performance with respect to standard backpropagation. Our method achieves similar performance to well-known CL methods, such as Elastic Weight Consolidation and Synaptic Intelligence, without requiring information about task boundaries. Overall, we showcase the idea of adopting computational principles from the brain to derive new, task-free learning algorithms for CL.
Adversarial Attacks on Spiking Convolutional Networks for Event-based Vision
Oct 06, 2021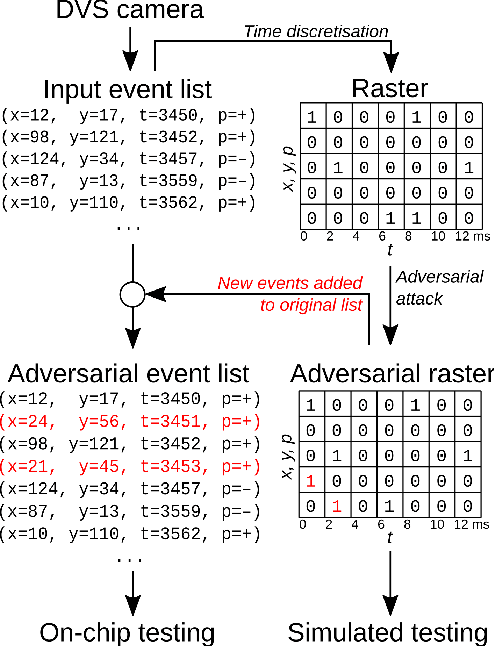
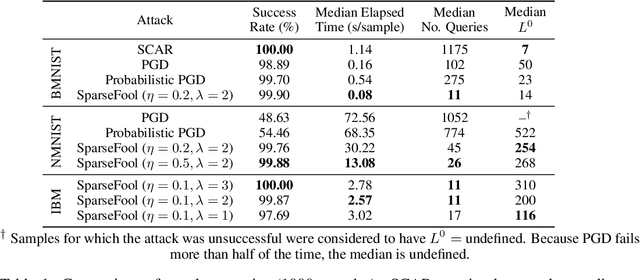


Event-based sensing using dynamic vision sensors is gaining traction in low-power vision applications. Spiking neural networks work well with the sparse nature of event-based data and suit deployment on low-power neuromorphic hardware. Being a nascent field, the sensitivity of spiking neural networks to potentially malicious adversarial attacks has received very little attention so far. In this work, we show how white-box adversarial attack algorithms can be adapted to the discrete and sparse nature of event-based visual data, and to the continuous-time setting of spiking neural networks. We test our methods on the N-MNIST and IBM Gestures neuromorphic vision datasets and show adversarial perturbations achieve a high success rate, by injecting a relatively small number of appropriately placed events. We also verify, for the first time, the effectiveness of these perturbations directly on neuromorphic hardware. Finally, we discuss the properties of the resulting perturbations and possible future directions.
Optimizing the energy consumption of spiking neural networks for neuromorphic applications
Dec 03, 2019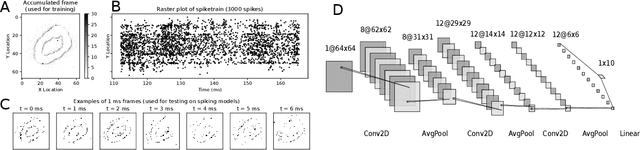
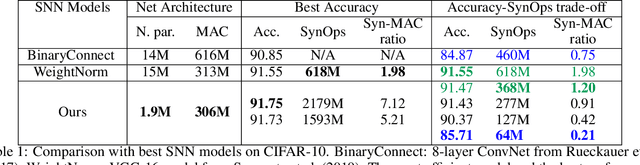
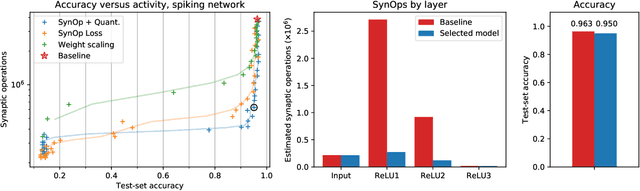
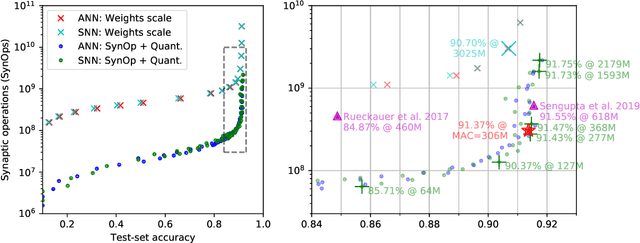
In the last few years, spiking neural networks have been demonstrated to perform on par with regular convolutional neural networks. Several works have proposed methods to convert a pre-trained CNN to a Spiking CNN without a significant sacrifice of performance. We demonstrate first that quantization-aware training of CNNs leads to better accuracy in SNNs. One of the benefits of converting CNNs to spiking CNNs is to leverage the sparse computation of SNNs and consequently perform equivalent computation at a lower energy consumption. Here we propose an efficient optimization strategy to train spiking networks at lower energy consumption, while maintaining similar accuracy levels. We demonstrate results on the MNIST-DVS and CIFAR-10 datasets.