 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time processing of analog signals on accelerated neuromorphic hardware
Feb 04, 2026Sensory processing with neuromorphic systems is typically done by using either event-based sensors or translating input signals to spikes before presenting them to the neuromorphic processor. Here, we offer an alternative approach: direct analog signal injection eliminates superfluous and power-intensive analog-to-digital and digital-to-analog conversions, making it particularly suitable for efficient near-sensor processing. We demonstrate this by using the accelerated BrainScaleS-2 mixed-signal neuromorphic research platform and interfacing it directly to microphones and a servo-motor-driven actuator. Utilizing BrainScaleS-2's 1000-fold acceleration factor, we employ a spiking neural network to transform interaural time differences into a spatial code and thereby predict the location of sound sources. Our primary contributions are the first demonstrations of direct, continuous-valued sensor data injection into the analog compute units of the BrainScaleS-2 ASIC, and actuator control using its embedded microprocessors. This enables a fully on-chip processing pipeline$\unicode{x2014}$from sensory input handling, via spiking neural network processing to physical action. We showcase this by programming the system to localize and align a servo motor with the spatial direction of transient noise peaks in real-time.
mGRADE: Minimal Recurrent Gating Meets Delay Convolutions for Lightweight Sequence Modeling
Jul 02, 2025Edge devices for temporal processing demand models that capture both short- and long- range dynamics under tight memory constraints. While Transformers excel at sequence modeling, their quadratic memory scaling with sequence length makes them impractical for such settings. Recurrent Neural Networks (RNNs) offer constant memory but train sequentially, and Temporal Convolutional Networks (TCNs), though efficient, scale memory with kernel size. To address this, we propose mGRADE (mininally Gated Recurrent Architecture with Delay Embedding), a hybrid-memory system that integrates a temporal 1D-convolution with learnable spacings followed by a minimal gated recurrent unit (minGRU). This design allows the convolutional layer to realize a flexible delay embedding that captures rapid temporal variations, while the recurrent module efficiently maintains global context with minimal memory overhead. We validate our approach on two synthetic tasks, demonstrating that mGRADE effectively separates and preserves multi-scale temporal features. Furthermore, on challenging pixel-by-pixel image classification benchmarks, mGRADE consistently outperforms both pure convolutional and pure recurrent counterparts using approximately 20% less memory footprint, highlighting its suitability for memory-constrained temporal processing at the edge. This highlights mGRADE's promise as an efficient solution for memory-constrained multi-scale temporal processing at the edge.
Quantizing Small-Scale State-Space Models for Edge AI
Jun 14, 2025State-space models (SSMs) have recently gained attention in deep learning for their ability to efficiently model long-range dependencies, making them promising candidates for edge-AI applications. In this paper, we analyze the effects of quantization on small-scale SSMs with a focus on reducing memory and computational costs while maintaining task performance. Using the S4D architecture, we first investigate post-training quantization (PTQ) and show that the state matrix A and internal state x are particularly sensitive to quantization. Furthermore, we analyze the impact of different quantization techniques applied to the parameters and activations in the S4D architecture. To address the observed performance drop after Post-training Quantization (PTQ), we apply Quantization-aware Training (QAT), significantly improving performance from 40% (PTQ) to 96% on the sequential MNIST benchmark at 8-bit precision. We further demonstrate the potential of QAT in enabling sub-8-bit precisions and evaluate different parameterization schemes for QAT stability. Additionally, we propose a heterogeneous quantization strategy that assigns different precision levels to model components, reducing the overall memory footprint by a factor of 6x without sacrificing performance. Our results provide actionable insights for deploying quantized SSMs in resource-constrained environments.
MINIMALIST: switched-capacitor circuits for efficient in-memory computation of gated recurrent units
May 13, 2025

Recurrent neural networks (RNNs) have been a long-standing candidate for processing of temporal sequence data, especially in memory-constrained systems that one may find in embedded edge computing environments. Recent advances in training paradigms have now inspired new generations of efficient RNNs. We introduce a streamlined and hardware-compatible architecture based on minimal gated recurrent units (GRUs), and an accompanying efficient mixed-signal hardware implementation of the model. The proposed design leverages switched-capacitor circuits not only for in-memory computation (IMC), but also for the gated state updates. The mixed-signal cores rely solely on commodity circuits consisting of metal capacitors, transmission gates, and a clocked comparator, thus greatly facilitating scaling and transfer to other technology nodes. We benchmark the performance of our architecture on time series data, introducing all constraints required for a direct mapping to the hardware system. The direct compatibility is verified in mixed-signal simulations, reproducing data recorded from the software-only network model.
The Role of Temporal Hierarchy in Spiking Neural Networks
Jul 26, 2024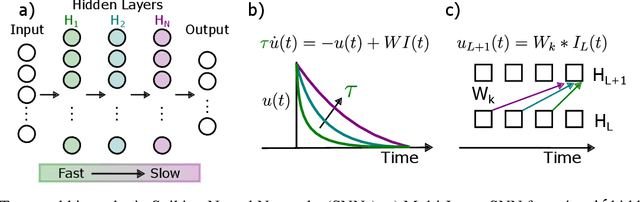
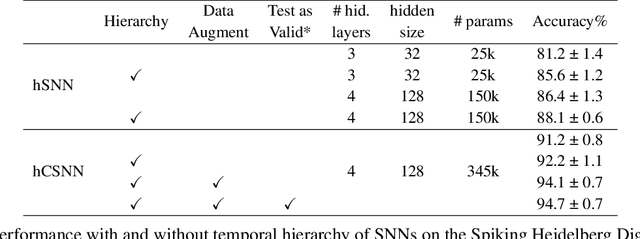
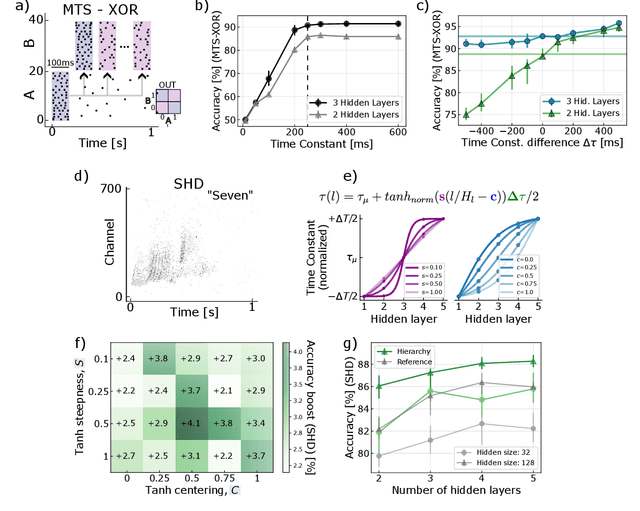

Spiking Neural Networks (SNNs) have the potential for rich spatio-temporal signal processing thanks to exploiting both spatial and temporal parameters. The temporal dynamics such as time constants of the synapses and neurons and delays have been recently shown to have computational benefits that help reduce the overall number of parameters required in the network and increase the accuracy of the SNNs in solving temporal tasks. Optimizing such temporal parameters, for example, through gradient descent, gives rise to a temporal architecture for different problems. As has been shown in machine learning, to reduce the cost of optimization, architectural biases can be applied, in this case in the temporal domain. Such inductive biases in temporal parameters have been found in neuroscience studies, highlighting a hierarchy of temporal structure and input representation in different layers of the cortex. Motivated by this, we propose to impose a hierarchy of temporal representation in the hidden layers of SNNs, highlighting that such an inductive bias improves their performance. We demonstrate the positive effects of temporal hierarchy in the time constants of feed-forward SNNs applied to temporal tasks (Multi-Time-Scale XOR and Keyword Spotting, with a benefit of up to 4.1% in classification accuracy). Moreover, we show that such architectural biases, i.e. hierarchy of time constants, naturally emerge when optimizing the time constants through gradient descent, initialized as homogeneous values. We further pursue this proposal in temporal convolutional SNNs, by introducing the hierarchical bias in the size and dilation of temporal kernels, giving rise to competitive results in popular temporal spike-based datasets.
DelGrad: Exact gradients in spiking networks for learning transmission delays and weights
Apr 30, 2024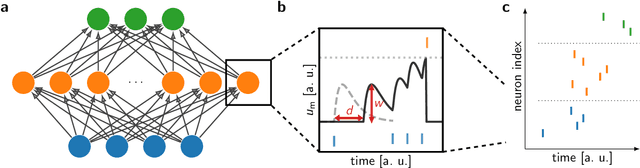
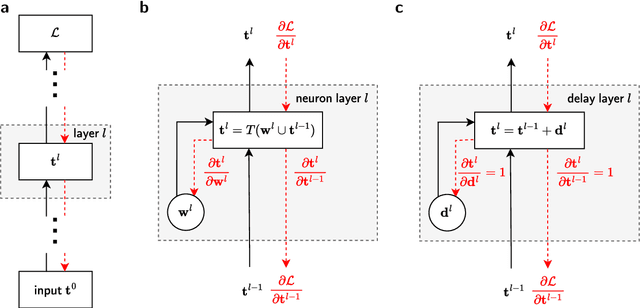
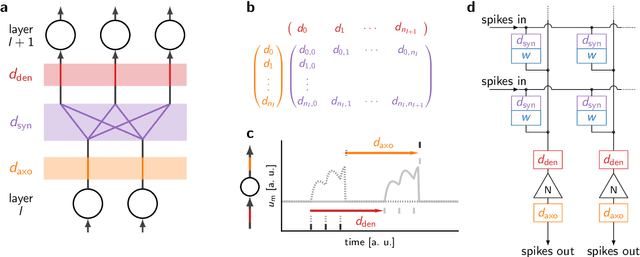
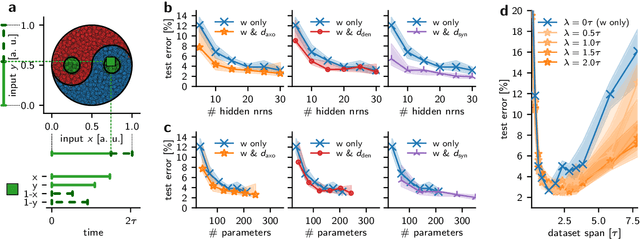
Spiking neural networks (SNNs) inherently rely on the timing of signals for representing and processing information. Transmission delays play an important role in shaping these temporal characteristics. Recent work has demonstrated the substantial advantages of learning these delays along with synaptic weights, both in terms of accuracy and memory efficiency. However, these approaches suffer from drawbacks in terms of precision and efficiency, as they operate in discrete time and with approximate gradients, while also requiring membrane potential recordings for calculating parameter updates. To alleviate these issues, we propose an analytical approach for calculating exact loss gradients with respect to both synaptic weights and delays in an event-based fashion. The inclusion of delays emerges naturally within our proposed formalism, enriching the model's search space with a temporal dimension. Our algorithm is purely based on the timing of individual spikes and does not require access to other variables such as membrane potentials. We explicitly compare the impact on accuracy and parameter efficiency of different types of delays - axonal, dendritic and synaptic. Furthermore, while previous work on learnable delays in SNNs has been mostly confined to software simulations, we demonstrate the functionality and benefits of our approach on the BrainScaleS-2 neuromorphic platform.
Backpropagation through space, time, and the brain
Mar 25, 2024Effective learning in neuronal networks requires the adaptation of individual synapses given their relative contribution to solving a task. However, physical neuronal systems -- whether biological or artificial -- are constrained by spatio-temporal locality. How such networks can perform efficient credit assignment, remains, to a large extent, an open question. In Machine Learning, the answer is almost universally given by the error backpropagation algorithm, through both space (BP) and time (BPTT). However, BP(TT) is well-known to rely on biologically implausible assumptions, in particular with respect to spatiotemporal (non-)locality, while forward-propagation models such as real-time recurrent learning (RTRL) suffer from prohibitive memory constraints. We introduce Generalized Latent Equilibrium (GLE), a computational framework for fully local spatio-temporal credit assignment in physical, dynamical networks of neurons. We start by defining an energy based on neuron-local mismatches, from which we derive both neuronal dynamics via stationarity and parameter dynamics via gradient descent. The resulting dynamics can be interpreted as a real-time, biologically plausible approximation of BPTT in deep cortical networks with continuous-time neuronal dynamics and continuously active, local synaptic plasticity. In particular, GLE exploits the ability of biological neurons to phase-shift their output rate with respect to their membrane potential, which is essential in both directions of information propagation. For the forward computation, it enables the mapping of time-continuous inputs to neuronal space, performing an effective spatiotemporal convolution. For the backward computation, it permits the temporal inversion of feedback signals, which consequently approximate the adjoint states necessary for useful parameter updates.
Order from chaos: Interplay of development and learning in recurrent networks of structured neurons
Feb 26, 2024



Behavior can be described as a temporal sequence of actions driven by neural activity. To learn complex sequential patterns in neural networks, memories of past activities need to persist on significantly longer timescales than relaxation times of single-neuron activity. While recurrent networks can produce such long transients, training these networks in a biologically plausible way is challenging. One approach has been reservoir computing, where only weights from a recurrent network to a readout are learned. Other models achieve learning of recurrent synaptic weights using propagated errors. However, their biological plausibility typically suffers from issues with locality, resource allocation or parameter scales and tuning. We suggest that many of these issues can be alleviated by considering dendritic information storage and computation. By applying a fully local, always-on plasticity rule we are able to learn complex sequences in a recurrent network comprised of two populations. Importantly, our model is resource-efficient, enabling the learning of complex sequences using only a small number of neurons. We demonstrate these features in a mock-up of birdsong learning, in which our networks first learn a long, non-Markovian sequence that they can then reproduce robustly despite external disturbances.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Learning efficient backprojections across cortical hierarchies in real time
Dec 20, 2022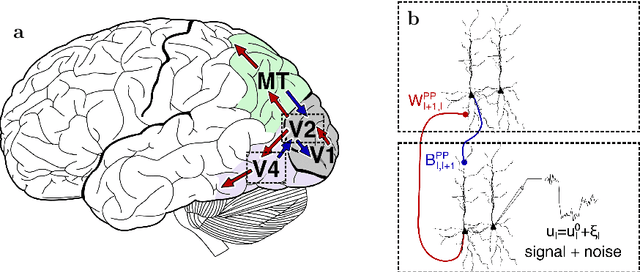
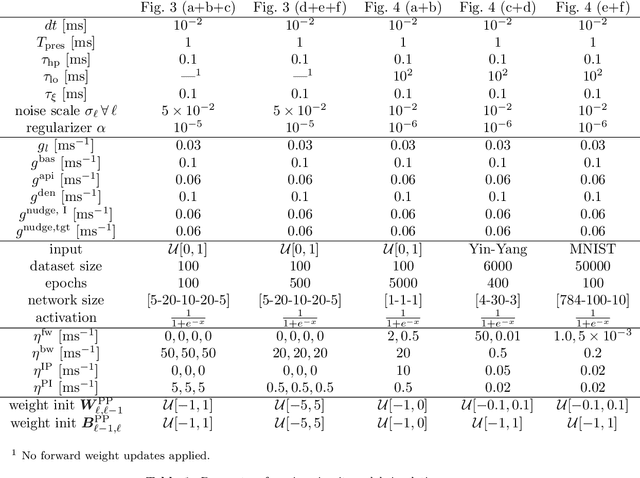
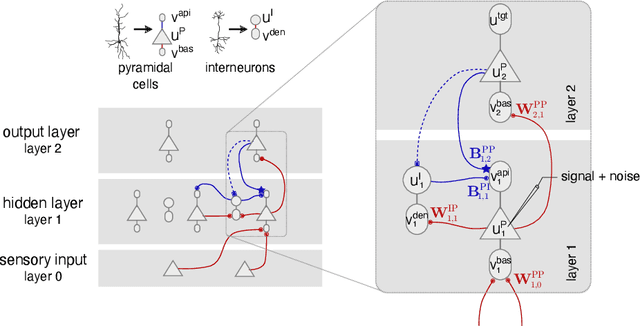
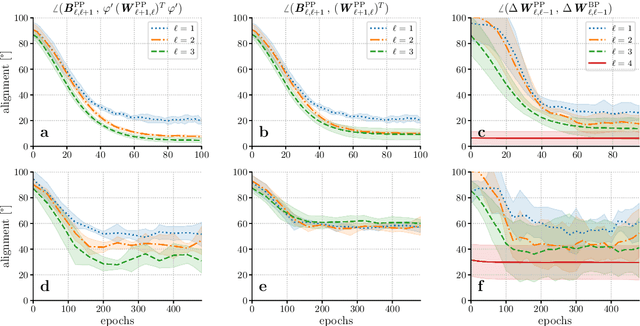
Models of sensory processing and learning in the cortex need to efficiently assign credit to synapses in all areas. In deep learning, a known solution is error backpropagation, which however requires biologically implausible weight transport from feed-forward to feedback paths. We introduce Phaseless Alignment Learning (PAL), a bio-plausible method to learn efficient feedback weights in layered cortical hierarchies. This is achieved by exploiting the noise naturally found in biophysical systems as an additional carrier of information. In our dynamical system, all weights are learned simultaneously with always-on plasticity and using only information locally available to the synapses. Our method is completely phase-free (no forward and backward passes or phased learning) and allows for efficient error propagation across multi-layer cortical hierarchies, while maintaining biologically plausible signal transport and learning. Our method is applicable to a wide class of models and improves on previously known biologically plausible ways of credit assignment: compared to random synaptic feedback, it can solve complex tasks with less neurons and learn more useful latent representations. We demonstrate this on various classification tasks using a cortical microcircuit model with prospective coding.