 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBivariate Causal Discovery Using Rate-Distortion MDL: An Information Dimension Approach
Apr 07, 2026Approaches to bivariate causal discovery based on the minimum description length (MDL) principle approximate the (uncomputable) Kolmogorov complexity of the models in each causal direction, selecting the one with the lower total complexity. The premise is that nature's mechanisms are simpler in their true causal order. Inherently, the description length (complexity) in each direction includes the description of the cause variable and that of the causal mechanism. In this work, we argue that current state-of-the-art MDL-based methods do not correctly address the problem of estimating the description length of the cause variable, effectively leaving the decision to the description length of the causal mechanism. Based on rate-distortion theory, we propose a new way to measure the description length of the cause, corresponding to the minimum rate required to achieve a distortion level representative of the underlying distribution. This distortion level is deduced using rules from histogram-based density estimation, while the rate is computed using the related concept of information dimension, based on an asymptotic approximation. Combining it with a traditional approach for the causal mechanism, we introduce a new bivariate causal discovery method, termed rate-distortion MDL (RDMDL). We show experimentally that RDMDL achieves competitive performance on the Tübingen dataset. All the code and experiments are publicly available at github.com/tiagobrogueira/Causal-Discovery-In-Exchangeable-Data.
Enhancing Multi-Robot Exploration Using Probabilistic Frontier Prioritization with Dirichlet Process Gaussian Mixtures
Apr 03, 2026Multi-agent autonomous exploration is essential for applications such as environmental monitoring, search and rescue, and industrial-scale surveillance. However, effective coordination under communication constraints remains a significant challenge. Frontier exploration algorithms analyze the boundary between the known and unknown regions to determine the next-best view that maximizes exploratory gain. This article proposes an enhancement to existing frontier-based exploration algorithms by introducing a probabilistic approach to frontier prioritization. By leveraging Dirichlet process Gaussian mixture model (DP-GMM) and a probabilistic formulation of information gain, the method improves the quality of frontier prioritization. The proposed enhancement, integrated into two state-of-the-art multi-agent exploration algorithms, consistently improves performance across environments of varying clutter, communication constraints, and team sizes. Simulations showcase an average gain of $10\%$ and $14\%$ for the two algorithms across all combinations. Successful deployment in real-world experiments with a dual-drone system further corroborates these findings.
A Teacher-Student Perspective on the Dynamics of Learning Near the Optimal Point
Dec 17, 2025Near an optimal learning point of a neural network, the learning performance of gradient descent dynamics is dictated by the Hessian matrix of the loss function with respect to the network parameters. We characterize the Hessian eigenspectrum for some classes of teacher-student problems, when the teacher and student networks have matching weights, showing that the smaller eigenvalues of the Hessian determine long-time learning performance. For linear networks, we analytically establish that for large networks the spectrum asymptotically follows a convolution of a scaled chi-square distribution with a scaled Marchenko-Pastur distribution. We numerically analyse the Hessian spectrum for polynomial and other non-linear networks. Furthermore, we show that the rank of the Hessian matrix can be seen as an effective number of parameters for networks using polynomial activation functions. For a generic non-linear activation function, such as the error function, we empirically observe that the Hessian matrix is always full rank.
LxCIM: a new rank-based binary classifier performance metric invariant to local exchange of classes
Dec 10, 2025

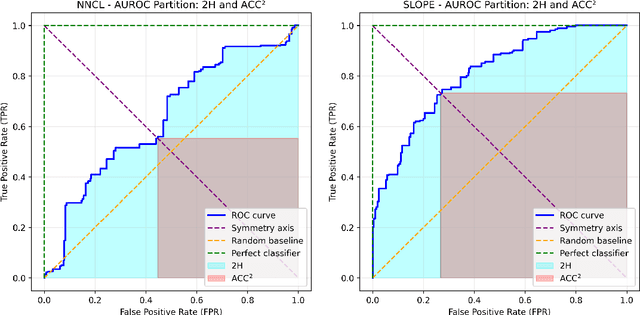

Binary classification is one of the oldest, most prevalent, and studied problems in machine learning. However, the metrics used to evaluate model performance have received comparatively little attention. The area under the receiver operating characteristic curve (AUROC) has long been a standard choice for model comparison. Despite its advantages, AUROC is not always ideal, particularly for problems that are invariant to local exchange of classes (LxC), a new form of metric invariance introduced in this work. To address this limitation, we propose LxCIM (LxC-invariant metric), which is not only rank-based and invariant under local exchange of classes, but also intuitive, logically consistent, and always computable, while enabling more detailed analysis through the cumulative accuracy-decision rate curve. Moreover, LxCIM exhibits clear theoretical connections to AUROC, accuracy, and the area under the accuracy-decision rate curve (AUDRC). These relationships allow for multiple complementary interpretations: as a symmetric form of AUROC, a rank-based analogue of accuracy, or a more representative and more interpretable variant of AUDRC. Finally, we demonstrate the direct applicability of LxCIM to the bivariate causal discovery problem (which exhibits invariance to local exchange of classes) and show how it addresses the acknowledged limitations of existing metrics used in this field. All code and implementation details are publicly available at github.com/tiagobrogueira/Causal-Discovery-In-Exchangeable-Data.
Sparse Activations as Conformal Predictors
Feb 23, 2025Conformal prediction is a distribution-free framework for uncertainty quantification that replaces point predictions with sets, offering marginal coverage guarantees (i.e., ensuring that the prediction sets contain the true label with a specified probability, in expectation). In this paper, we uncover a novel connection between conformal prediction and sparse softmax-like transformations, such as sparsemax and $\gamma$-entmax (with $\gamma > 1$), which may assign nonzero probability only to a subset of labels. We introduce new non-conformity scores for classification that make the calibration process correspond to the widely used temperature scaling method. At test time, applying these sparse transformations with the calibrated temperature leads to a support set (i.e., the set of labels with nonzero probability) that automatically inherits the coverage guarantees of conformal prediction. Through experiments on computer vision and text classification benchmarks, we demonstrate that the proposed method achieves competitive results in terms of coverage, efficiency, and adaptiveness compared to standard non-conformity scores based on softmax.
Conformal Prediction for Natural Language Processing: A Survey
May 03, 2024The rapid proliferation of large language models and natural language processing (NLP) applications creates a crucial need for uncertainty quantification to mitigate risks such as hallucinations and to enhance decision-making reliability in critical applications. Conformal prediction is emerging as a theoretically sound and practically useful framework, combining flexibility with strong statistical guarantees. Its model-agnostic and distribution-free nature makes it particularly promising to address the current shortcomings of NLP systems that stem from the absence of uncertainty quantification. This paper provides a comprehensive survey of conformal prediction techniques, their guarantees, and existing applications in NLP, pointing to directions for future research and open challenges.
Cost-Sensitive Learning to Defer to Multiple Experts with Workload Constraints
Mar 21, 2024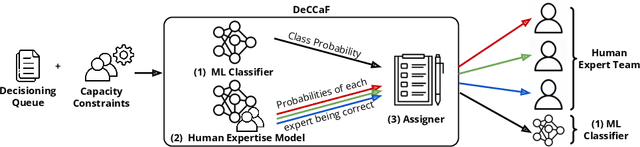
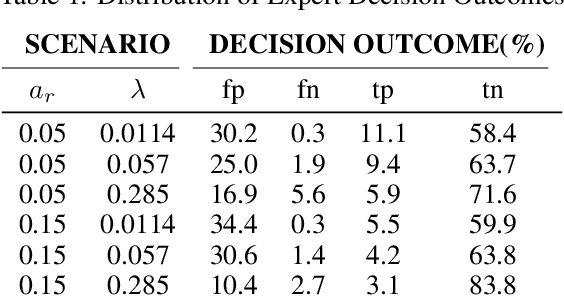
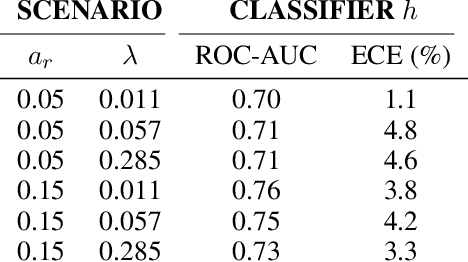
Learning to defer (L2D) aims to improve human-AI collaboration systems by learning how to defer decisions to humans when they are more likely to be correct than an ML classifier. Existing research in L2D overlooks key aspects of real-world systems that impede its practical adoption, namely: i) neglecting cost-sensitive scenarios, where type 1 and type 2 errors have different costs; ii) requiring concurrent human predictions for every instance of the training dataset and iii) not dealing with human work capacity constraints. To address these issues, we propose the deferral under cost and capacity constraints framework (DeCCaF). DeCCaF is a novel L2D approach, employing supervised learning to model the probability of human error under less restrictive data requirements (only one expert prediction per instance) and using constraint programming to globally minimize the error cost subject to workload limitations. We test DeCCaF in a series of cost-sensitive fraud detection scenarios with different teams of 9 synthetic fraud analysts, with individual work capacity constraints. The results demonstrate that our approach performs significantly better than the baselines in a wide array of scenarios, achieving an average 8.4% reduction in the misclassification cost.
DiConStruct: Causal Concept-based Explanations through Black-Box Distillation
Jan 26, 2024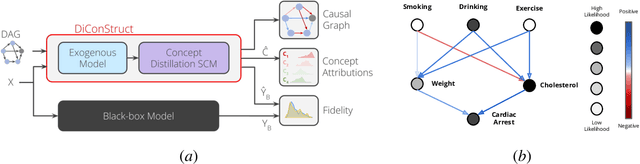
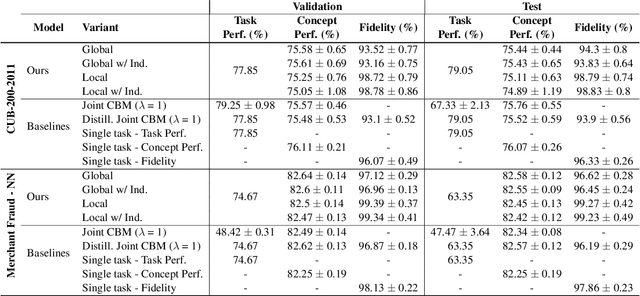
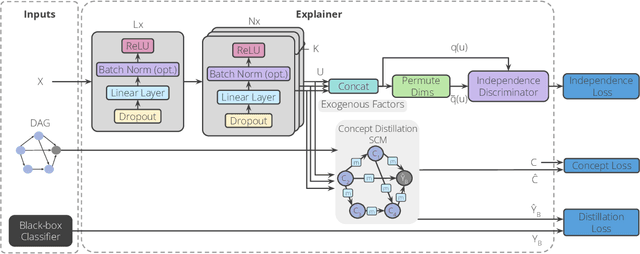
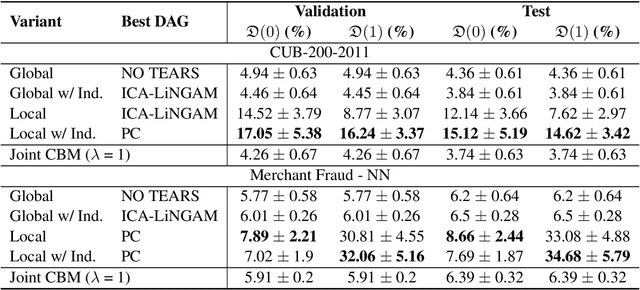
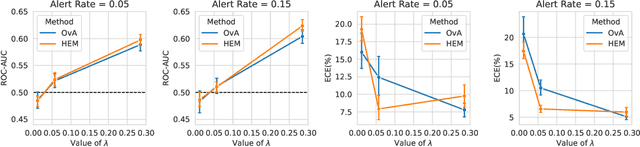
Model interpretability plays a central role in human-AI decision-making systems. Ideally, explanations should be expressed using human-interpretable semantic concepts. Moreover, the causal relations between these concepts should be captured by the explainer to allow for reasoning about the explanations. Lastly, explanation methods should be efficient and not compromise the performance of the predictive task. Despite the rapid advances in AI explainability in recent years, as far as we know to date, no method fulfills these three properties. Indeed, mainstream methods for local concept explainability do not produce causal explanations and incur a trade-off between explainability and prediction performance. We present DiConStruct, an explanation method that is both concept-based and causal, with the goal of creating more interpretable local explanations in the form of structural causal models and concept attributions. Our explainer works as a distillation model to any black-box machine learning model by approximating its predictions while producing the respective explanations. Because of this, DiConStruct generates explanations efficiently while not impacting the black-box prediction task. We validate our method on an image dataset and a tabular dataset, showing that DiConStruct approximates the black-box models with higher fidelity than other concept explainability baselines, while providing explanations that include the causal relations between the concepts.
FiFAR: A Fraud Detection Dataset for Learning to Defer
Dec 20, 2023Public dataset limitations have significantly hindered the development and benchmarking of learning to defer (L2D) algorithms, which aim to optimally combine human and AI capabilities in hybrid decision-making systems. In such systems, human availability and domain-specific concerns introduce difficulties, while obtaining human predictions for training and evaluation is costly. Financial fraud detection is a high-stakes setting where algorithms and human experts often work in tandem; however, there are no publicly available datasets for L2D concerning this important application of human-AI teaming. To fill this gap in L2D research, we introduce the Financial Fraud Alert Review Dataset (FiFAR), a synthetic bank account fraud detection dataset, containing the predictions of a team of 50 highly complex and varied synthetic fraud analysts, with varied bias and feature dependence. We also provide a realistic definition of human work capacity constraints, an aspect of L2D systems that is often overlooked, allowing for extensive testing of assignment systems under real-world conditions. We use our dataset to develop a capacity-aware L2D method and rejection learning approach under realistic data availability conditions, and benchmark these baselines under an array of 300 distinct testing scenarios. We believe that this dataset will serve as a pivotal instrument in facilitating a systematic, rigorous, reproducible, and transparent evaluation and comparison of L2D methods, thereby fostering the development of more synergistic human-AI collaboration in decision-making systems. The public dataset and detailed synthetic expert information are available at: https://github.com/feedzai/fifar-dataset
Fairness-Aware Data Valuation for Supervised Learning
Mar 29, 2023


Data valuation is a ML field that studies the value of training instances towards a given predictive task. Although data bias is one of the main sources of downstream model unfairness, previous work in data valuation does not consider how training instances may influence both performance and fairness of ML models. Thus, we propose Fairness-Aware Data vauatiOn (FADO), a data valuation framework that can be used to incorporate fairness concerns into a series of ML-related tasks (e.g., data pre-processing, exploratory data analysis, active learning). We propose an entropy-based data valuation metric suited to address our two-pronged goal of maximizing both performance and fairness, which is more computationally efficient than existing metrics. We then show how FADO can be applied as the basis for unfairness mitigation pre-processing techniques. Our methods achieve promising results -- up to a 40 p.p. improvement in fairness at a less than 1 p.p. loss in performance compared to a baseline -- and promote fairness in a data-centric way, where a deeper understanding of data quality takes center stage.